Objective of the project is to reproduce results from OpenAI paper "Emergent Tool Use From Multi-Agent Autocurricula" (Blog page) by using free Unity engine instead of MuJoCo. In the paper researches observed how agents learned to use different objects while playing hide-and-seek game in order to beat the opposite team.
There two teams of agents: hiders and seekers. The task of hiders is to avoid seekers line of sight and the task of seekers is to keep hiders in sight. Agents can move, turn around, grab and lock special objects in the environment. Seekers get positive reward and hiders get the same negative reward if any of the hiders are seen otherwise rewards are mirrored. Agents also penalized if they escape from playing area, it is possible because of physics engine imperfection, and it is a winning strategy for hiders (they get it quickly enough) because seekers can not deal much with it while this is not very interesting case, same problem was met in the paper. There is also preparation phase when seekers are disabled and rewards are not given.
For more details see paper or OpenAI blog page.
Agents' actions and observations are made as in the paper
x denotes two dimensional position vector and v denotes two dimensional velocity vector below
| Observation | Details |
|---|---|
| x and v of self | |
| Lidar | Range sensors arrayed evenly around the agents |
| Line of sight | Cone in front of the agent. Agent get information about other object only if it gets inside the cone |
| x, v, label of another object | label indicates whether the object is hider, seeker, box or ramp |
| Action | Details |
|---|---|
| Apply force to self | Applying force to the agent makes it move |
| Add torque to self | Adding torque makes agent turn around |
| Grab object | Agent can grab an object and move it around |
| Drop object | Agent can drop the object which was grabbed |
| Lock object | Agent can lock an object so object can't be moved or grabbed by anyone else |
| Unlock object | Agent can cancel object lock if it was made by the agent from the same team |
Agents are improved with reinforcement learning. The required algorithms are already implemented in the Unity ML-Agents Toolkit which allows to train agents in environment created with Unity.
To manipulate agents manually use the following keys
| Key | Action |
|---|---|
W,A,S,D |
Add force along one of directions |
Q,E |
Add torque to rotate counter-clockwise or clockwise |
1 |
Drop object |
2 |
Grab object |
3 |
Unlock object |
4 |
Lock object |
At this moment only one environment is implemented.
In simple environment there is a room with two holes placed randomly, 2 agents in each team, 2 boxes and ramp. Hiders and boxes spawn randomly inside the room, seekers and the ramp spawn randomly outside the room.

Video demonstration:

- Install ML-Agents with this instruction. Version 0.25.0 was used.
- Clone this repository with
git clone. - In Unity Hub go to Projects, press Add and choose multi-agent-emergence-unity/MAHS directory to import.
After installation you are able to open this project in Unity editor. Add as many Assets/SimpleEnv/TrainingArea prefabs as you need to the scene or just choose Assets/SimpleEnv/TrainingScene with 4 training areas.
Every TrainingArea object has attached Config script which you can change to configurate the game.
After configuring go to Unity multi-agent-emergence-unity/MAHS directory in your terminal run mlagents-learn <your-config> --run-id=<run-name>. When you see "Start training by pressing the Play button in the Unity Editor" press the Play button in Unity editor to start training. For more information check this documentation.
- Copy models that you want from multi-agent-emergence-unity/MAHS/results/ to the Unity editor
- For every agent in their Behavior Parameters attach corresponding model to the Model and change Behavior Type to Inference
- Run with the Play button
Check this documentation if you need.
Training on Amazon Web Service, Training on Microsoft Azure.
At this moment interesting results were only achieved in the simplest setup with one agent in each team and one wall in the center of playing area.
Agents learned to escape from the playing area so penalty for leaving was added. There were 4 different stages in agents behavior:
- Random actions
- Seeker start chasing hider
- Hider learns to escape from playing area sometimes
- Seeker learns to await hider at the escape spot
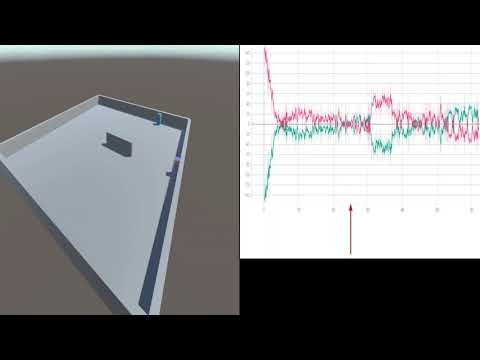
 Agents rewards during training. Pink line is hider reward, green line is seeker reward
Agents rewards during training. Pink line is hider reward, green line is seeker reward
Video demonstration:
More complex environments require more computation time and for now results in other setups are not available.