-
Notifications
You must be signed in to change notification settings - Fork 33
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge pull request #42 from Eclectic-Sheep/fix/sac_ae
Fix/sac ae
- Loading branch information
Showing
4 changed files
with
164 additions
and
4 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,155 @@ | ||
| # SAC-AutoEncoder (SAC-AE) | ||
| Images are everywhere, thus having effective RL approaches that can utilize pixels as input would potentially enable solutions for a wide range of real world applications, for example robotics and videogames. In [SAC-AutoEncoder](https://arxiv.org/abs/1910.01741) the standard [SAC](https://arxiv.org/abs/1801.01290) agent is enriched with a convolutional encoder, which encodes images into features, shared between the actor and critic. Also, to improve the quality of the extracted features, a convolutional decoder is used to reconstruct the input images from the features, effectively creating the Encoder-Decoder architecture. | ||
|
|
||
| The architecture is depicted in the following figure: | ||
|
|
||
| 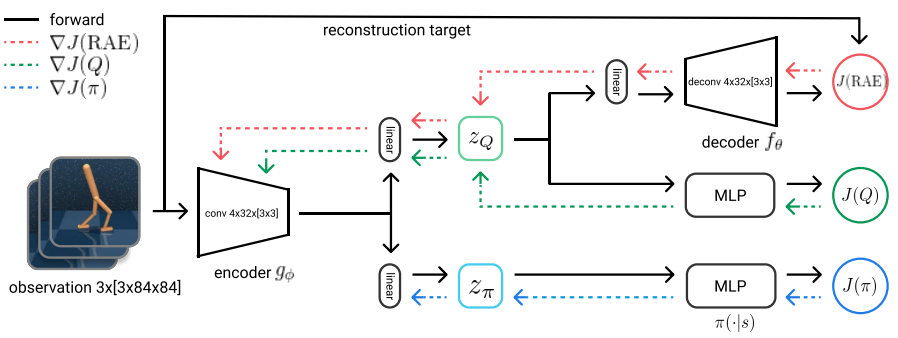 | ||
|
|
||
| Since learning directly from images can be cumbersome, as the authors have found out, some tricks must be taken into account: i.e.: | ||
|
|
||
| 1. Deterministic autoencoder: the encoder-decoder architecture is a standard deterministic one, which means that we are not going to learn a distribution over the extracted features conditioned on the input images | ||
| 2. The encoder will receive the gradients from the critic but not from the actor: receiving the gradients from the actor changes also the Q-function during the actor update, since the encoder is shared between the actor and the critic. | ||
| 3. To overcame the slowdown in the encoder update due to 2., the convolutional weights of the target Q-function are updated faster than the rest of the network’s parameters (effectively using a $\tau_{\text{enc}} > \tau_{\text{Q}}$) | ||
|
|
||
| Since we are learning in a distributed environment we also need to be careful regarding the weights reduction during the backward pass. For all those reasons the models are initialized as follows: | ||
|
|
||
| ```python | ||
| # Define the encoder and decoder and setup them with fabric. | ||
| # Then we will set the critic encoder and actor decoder as the unwrapped encoder module: | ||
| # we do not need it wrapped with the strategy inside actor and critic | ||
| encoder = Encoder(in_channels=in_channels, features_dim=args.features_dim, screen_size=args.screen_size) | ||
| decoder = Decoder( | ||
| encoder.conv_output_shape, | ||
| features_dim=args.features_dim, | ||
| screen_size=args.screen_size, | ||
| out_channels=in_channels, | ||
| ) | ||
| encoder = fabric.setup_module(encoder) | ||
| decoder = fabric.setup_module(decoder) | ||
|
|
||
| # Setup actor and critic. Those will initialize with orthogonal weights | ||
| # both the actor and critic | ||
| actor = SACPixelContinuousActor( | ||
| encoder=copy.deepcopy(encoder.module), # Unwrapping the strategy and deepcopy the encoder module | ||
| action_dim=act_dim, | ||
| hidden_size=args.actor_hidden_size, | ||
| action_low=envs.single_action_space.low, | ||
| action_high=envs.single_action_space.high, | ||
| ) | ||
| qfs = [ | ||
| SACPixelQFunction( | ||
| input_dim=encoder.output_dim, action_dim=act_dim, hidden_size=args.critic_hidden_size, output_dim=1 | ||
| ) | ||
| for _ in range(args.num_critics) | ||
| ] | ||
| critic = SACPixelCritic(encoder=encoder.module, qfs=qfs) # Unwrapping the encoder module. This is already tied to the wrapped encoder | ||
| actor = fabric.setup_module(actor) | ||
| critic = fabric.setup_module(critic) | ||
|
|
||
| # The agent will tied convolutional weights between the encoder actor and critic | ||
| agent = SACPixelAgent( | ||
| actor, | ||
| critic, | ||
| target_entropy, | ||
| alpha=args.alpha, | ||
| tau=args.tau, | ||
| encoder_tau=args.encoder_tau, | ||
| device=fabric.device, | ||
| ) | ||
|
|
||
| # Optimizers | ||
| qf_optimizer, actor_optimizer, alpha_optimizer, encoder_optimizer, decoder_optimizer = fabric.setup_optimizers( | ||
| Adam(agent.critic.parameters(), lr=args.q_lr), | ||
| Adam(agent.actor.parameters(), lr=args.policy_lr), | ||
| Adam([agent.log_alpha], lr=args.alpha_lr, betas=(0.5, 0.999)), | ||
| Adam(encoder.parameters(), lr=args.encoder_lr), | ||
| Adam(decoder.parameters(), lr=args.decoder_lr, weight_decay=args.decoder_wd), | ||
| ) | ||
| ``` | ||
|
|
||
| The three losses of SAC-AE are the same ones used for SAC, implemented in the `sheeprl/algos/sac/loss.py` file. | ||
| To account for the points 2. and 3. above, the training function is the following: | ||
|
|
||
| ```python | ||
| # Prevent OOM for both CPU and GPU memory. Data is memory mapped if args.memmap_buffer=True (which is recommended) | ||
| data = data.to(fabric.device) | ||
| normalized_obs = data["observations"] / 255.0 | ||
| normalized_next_obs = data["next_observations"] / 255.0 | ||
|
|
||
| # Update the soft-critic | ||
| next_target_qf_value = agent.get_next_target_q_values( | ||
| normalized_next_obs, data["rewards"], data["dones"], args.gamma | ||
| ) | ||
| qf_values = agent.get_q_values(normalized_obs, data["actions"]) | ||
| qf_loss = critic_loss(qf_values, next_target_qf_value, agent.num_critics) | ||
| qf_optimizer.zero_grad(set_to_none=True) | ||
| fabric.backward(qf_loss) | ||
| qf_optimizer.step() | ||
| aggregator.update("Loss/value_loss", qf_loss) | ||
|
|
||
| # Update the target networks with EMA. `args.target_network_frequency` is set to 2 by default | ||
| if global_step % args.target_network_frequency == 0: | ||
| agent.critic_target_ema() # Target update of the qfs only | ||
| agent.critic_encoder_target_ema() # Target update of the encoder only | ||
|
|
||
| # Update the actor. `args.actor_network_frequency` is set to 2 by default. | ||
| # In here the features extracted by the encoder are detach from the computational graph to prevent | ||
| # the actor gradients' to update the encoder | ||
| if global_step % args.actor_network_frequency == 0: | ||
| actions, logprobs = agent.get_actions_and_log_probs(normalized_obs, detach_encoder_features=True) | ||
| qf_values = agent.get_q_values(normalized_obs, actions, detach_encoder_features=True) | ||
| min_qf_values = torch.min(qf_values, dim=-1, keepdim=True)[0] | ||
| actor_loss = policy_loss(agent.alpha, logprobs, min_qf_values) | ||
| actor_optimizer.zero_grad(set_to_none=True) | ||
| fabric.backward(actor_loss) | ||
| actor_optimizer.step() | ||
| aggregator.update("Loss/policy_loss", actor_loss) | ||
|
|
||
| # Update the entropy value | ||
| alpha_loss = entropy_loss(agent.log_alpha, logprobs.detach(), agent.target_entropy) | ||
| alpha_optimizer.zero_grad(set_to_none=True) | ||
| fabric.backward(alpha_loss) | ||
| agent.log_alpha.grad = fabric.all_reduce(agent.log_alpha.grad, group=group) | ||
| alpha_optimizer.step() | ||
| aggregator.update("Loss/alpha_loss", alpha_loss) | ||
|
|
||
| # Update the encoder/decoder. This should reflect the update also to the `agent.critic.encoder` module. | ||
| if global_step % args.decoder_update_freq == 0: | ||
| hidden = encoder(normalized_obs) | ||
| reconstruction = decoder(hidden) | ||
| reconstruction_loss = ( | ||
| F.mse_loss(preprocess_obs(data["observations"], bits=5), reconstruction) # Reconstruction | ||
| + args.decoder_l2_lambda * (0.5 * hidden.pow(2).sum(1)).mean() # L2 penalty on the hidden state | ||
| ) | ||
| encoder_optimizer.zero_grad(set_to_none=True) | ||
| decoder_optimizer.zero_grad(set_to_none=True) | ||
| fabric.backward(reconstruction_loss) | ||
| encoder_optimizer.step() | ||
| decoder_optimizer.step() | ||
| aggregator.update("Loss/reconstruction_loss", reconstruction_loss) | ||
| ``` | ||
|
|
||
| ## Agent | ||
| The models of the SAC-AE agent are defined in the `agent.py` file in order to have a clearer definition of the components of the agent. Our implementation of SAC-AE assumes that the observations are images of shape `(3, 64, 64)`, while both the ecoder and decoder are fixed as specified in the paper. | ||
|
|
||
| ## Packages | ||
| In order to use a broader set of environments of provided by [Gymnasium](https://gymnasium.farama.org/) it is necessary to install optional packages: | ||
|
|
||
| * Mujoco environments: `pip install gymnasium[mujoco]` | ||
| * Atari environments: `pip install gymnasium[atari]` and `pip install gymnasium[accept-rom-license]` | ||
|
|
||
| ## Hyper-parameters | ||
| For SAC-AE, we decided to fix the number of environments to `1`, in order to have a clearer and more understandable management of the environment interaction. In addition, we would like to recommend the value of the `per_rank_batch_size` hyper-parameter to the users: the recommended batch size for the SAC-AE agent is 128 for single-process training, if you want to use distributed training, we recommend to divide the batch size by the number of processes and to set the `per_rank_batch_size` hyper-parameter accordingly. | ||
|
|
||
| ## Atari environments | ||
| There are two versions for most Atari environments: one version uses the *frame skip* property by default, whereas the second does not implement it. If the first version is selected, then the value of the `action_repeat` hyper-parameter must be `1`; instead, to select an environment without *frame skip*, it is necessary to insert `NoFrameskip` in the environment id and remove the prefix `ALE/` from it. For instance, the environment `ALE/AirRaid-v5` must be instantiated with `action_repeat=1`, whereas its version without *frame skip* is `AirRaidNoFrameskip-v4` and can be istanziated with any value of `action_repeat` greater than zero. | ||
| For more information see the official documentation of [Gymnasium Atari environments](https://gymnasium.farama.org/environments/atari/). | ||
|
|
||
| ## DMC environments | ||
| It is possible to use the environments provided by the [DeepMind Control suite](https://www.deepmind.com/open-source/deepmind-control-suite). To use such environments it is necessary to specify the "dmc" domain in the `env_id` hyper-parameter, e.g., `env_id = dmc_walker_walk` will create an instance of the walker walk environment. For more information about all the environments, check their [paper](https://arxiv.org/abs/1801.00690). | ||
|
|
||
| When running DreamerV1 in a DMC environment on a server (or a PC without a video terminal) it could be necessary to add two variables to the command to launch the script: `PYOPENGL_PLATFORM="" MUJOCO_GL=osmesa <command>`. For instance, to run walker walk with DreamerV1 on two gpus (0 and 1) it is necessary to runthe following command: `PYOPENGL_PLATFORM="" MUJOCO_GL=osmesa CUDA_VISIBLE_DEVICES="2,3" lightning run model --devices=2 --accelerator=gpu sheeprl.py sac_pixel --env_id=dmc_walker_walk --action_repeat=2 --capture_video --checkpoint_every=80000 --seed=1`. | ||
| Other possibitities for the variable `MUJOCO_GL` are: `GLFW` for rendering to an X11 window or and `EGL` for hardware accelerated headless. (For more information, click [here](https://mujoco.readthedocs.io/en/stable/programming/index.html#using-opengl)). | ||
|
|
||
| ## Recommendations | ||
| Since SAC-AE requires a huge number of steps and consequently a large buffer size, we recommend keeping the buffer on cpu and not moving it to cuda, while mapping it to shared-memory by setting the flag `--memmap_buffer=True` when launhing the script. Furthermore, in order to limit memory usage, we recommend to store the observations in `uint8` format and to normalize the observations just before starting the training one batch at a time. Finally, it is important to remind the user that SAC-AE works only with observations in pixel form, therefore, only environments with observation space that is an instance of `gym.spaces.Box` can be selected when used with gymnasium. |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters