Architecture
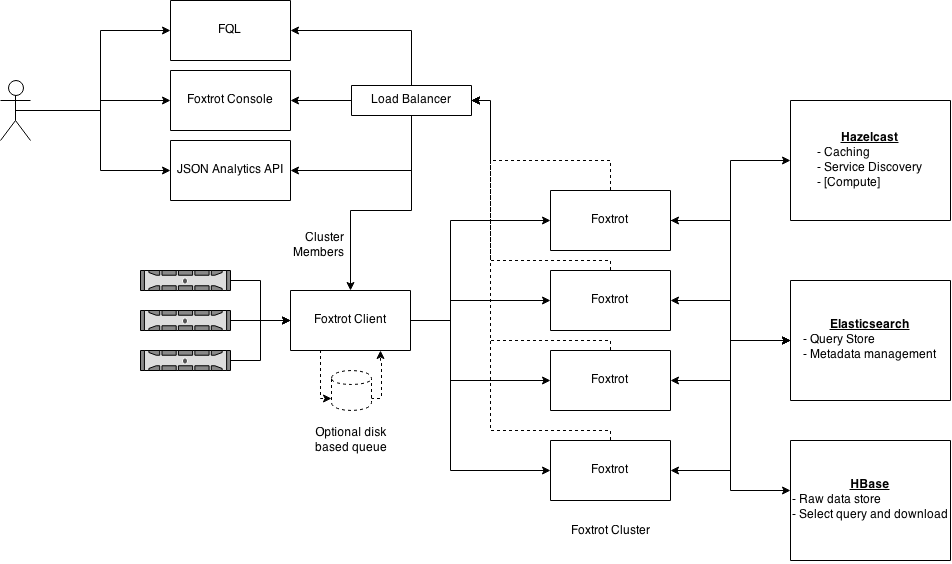
The Foxtrot system is structured in layers driven primarily by the time for which of event data needs to be stored.
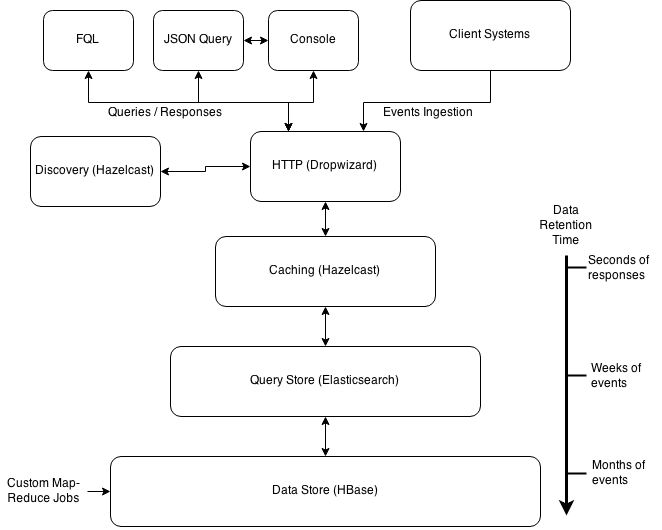
We go through them from bottom to top:
-
Long term/Key Value store - This is the raw key-value store used to pull events from foxtrot. The long term store powers the Event Get directly and Query analytics indirectly for Foxtrot. This layer will store event data for a long time. We chose HBase here because of the speed it offers and the flexibility of running custom Map-Reduce jobs on tons of events spanning over months. The document IDs become row keys on HBase. Top level Foxtrot tables can be mapped to Hbase layer in two modes:
- Common Table - Data for multiple Foxtrot tables are stored on same HBase table. This is useful when you actually are using Foxtrot mostly for it's summarization and ad-hoc search capabilities and are not planning to run MR jobs on the backend tables. Set the column-family retention to the max TTL for foxtrot table.
- Segregated Table_ - Data for the tables that have this flag set will be saved to respective separate tables. The HBase table names will be same as the foxtrot table names. An optional prefix for the table names can be provided in the YAML configuration file. Note - A running foxtrot cluster can have both common and segregated tables in place.
-
Query Store - This layer is the primary query and aggregation store for Foxtrot. We use Elasticsearch here because of the search and aggregation capabilities it provides. We use specialized mappings to make sure that memory usage and performance is balanced. We distribute data for each foxtrot table into 10 shards daily and replicate that on two nodes. For local setup no replication is done. The initialize flow takes care of setting up the mappings and replication based on the number of data nodes in the Elasticsearch cluster. We keep max 90 days of data on the Elasticsearch cluster. We store only document IDs on this layer. For the Query analytics we apply the filtering on Elasticsearch and get the raw data from the Key-Value store.
-
Query Cache - This layer makes sure that multiple similar queries do not go back to Elasticsearch. This is a common use-case where typically many people keep consoles open on multiple tabs. Each received query is analyzed for generating a cache key. The responses, if small enough, are stored on the cache and returned without ever hitting Elasticsearch. The generated cache key is time-dependent and changes every 30 seconds for the same query. This means queries coming from multiple hosts within the same 30 seconds will be using getting the same data. Queries can skip caching in two cases:
- When the response size is bigger than 4KB.
- When the analytics being applied specifies that it's not cacheable. (For example query).
-
Http Layer - We chose to use HTTP for ingestion and queries primarily because we have a very varied tech stack. We chose Dropwizard, as it provided nice clean abstractions over industry standard components.
-
Service Discovery - We wanted to avoid routing all the event data through our load balancers. To that end, we introduced simple service discovery based on Hazelcast. All Foxtrot nodes register themselves on a distributed Hazelcast map. The entries for each node TTL out on the map. To remain discoverable, a Foxtrot node keeps on re-inserting itself into the map. This re-insertion happens only when the node is healthy (Thread pools are okay, and Hazelcast and ES connectivity is fine). The list of healthy nodes are available through a simple HTTP API. This API is hit by clients through the load balancer. Every client maintains a local cache of Foxtrot node that gets refreshed by a poller. A node is selected from the cache in random and a bunch of events are pushed to it. This way, the ingestion requests are distributed evenly on the cluster without passing through the load balancer. All query and console requests which is much lesser in number, pass through the load balancer.
The main query format for Foxtrot is the JSON query. All console requests are formatted to JSON queries and forwarded to the Foxtrot nodes. All FQL queries get translated to the JSON query format. We have tried to give good coverage of operators and queries needed in real life. The code is structured to allow for quick addition of newer analytics functions. Although, at present all of the analytics pass through Elasticsearch, they don't necessarily be restricted to it. Complex analytics can be implemented that use distributed executors and other Hazelcast features.