


Command line tool to extract data from Trello, in particular for creating burndown charts.
A detailed description of the functionality of the tool can be found in the man page.
For expectations how the board has to be structured to make the burndown chart functions work see the Trollolo man page. There is an example Trello board which demonstrates the expected structure.
You need to have Ruby install. Trollolo works with Ruby >= 2.2.
You can install Trollolo as gem with gem install trollolo.
For the chart generation you will need a working matplotlib installation and the python module to read YAML. On openSUSE you can get that with
zypper install python2-matplotlib python2-matplotlib-tk python2-PyYAML
or
zypper install python-matplotlib python-matplotlib-tk python-PyYAML
Trollolo reads a configuration file .trollolorc in the home directory of the
user running the command line tool. It reads the data required to authenticate
with the Trello server from it. It's two values (the example shows random data):
developer_public_key: 87349873487ef8732487234
member_token: 87345897238957a29835789b2374580927f3589072398579820345These values have to be set with the personal access data for the Trello API and the personal access token of the application, which has to be generated.
For creating a developer key go to the Developer API Keys page on Trello. It's the key in the first box.
For creating a member token use the following URL, replacing ... by
the key you obtained in the first step.
https://trello.com/1/authorize?key=...&name=trollolo&expiration=never&response_type=token
To create a member token for the set-priority command use this URL instead:
https://trello.com/1/connect?key=...&name=trollolo&response_type=token&scope=read,write
The board id is the cryptic string in the URL of your board.
The .trollolorc file can also be used to set aliases for board ids. When set,
you will be able to use the alias instead of the board-id in the various
commands. E.g.
With the following configuration
board_aliases:
MyTrelloBoard: 53186e8391ef8671265ebf9e
You can issue the command:
trollolo get-cards --board-id=MyTrelloBoard
Trollolo implements a simple work flow for creating burndown charts from the data on a Trello board. It fetches the data from Trello, stores and processes it locally, and generates charts which can then be uploaded as graphics to Trello again.
At the moment it only needs read-only access to the Trello board from which it reads the data. In the future it would be great, if it could also write back the generated data and results to make it even more automatic.
The work flow goes as follows:
Start the workflow by using the current directory as working directory and initialize it for the burndown chart generation:
trollolo burndown-init --board-id=MYBOARDID
By default, trollolo uses the current directory as working directory, if you
want to specify another directory as working directory, use the --output
option as follows:
trollolo burndown-init --board-id=MYBOARDID --output=WORKING_DIR
This will create a directory WORKING_DIR and put an initial data file there,
which contains the meta data. The file is called burndown-data-1.yaml. You
might want to keep this file in a git repository for safe storage and history.
After each daily go to the working directory and call:
trollolo burndown
This will get the current data from the Trello board and update the data file with the data from the current day. If there already was some data in the file for the same day it will be overridden.
When the sprint is over and you want to start with the next sprint, go to the working directory and call:
trollolo burndown --new-sprint
This will create a new data file for the next sprint number and populate it
with initial data taken from the Trello board. You are ready to go for the
sprint now and can continue with calling trollolo burndown after each daily.
To push the current state of the scrum process (current day) to an api endpoint call:
trollolo burndown --push-to-api URL
Trollolo will send a json encoded POST request to URL with the same structure as the generated burndown yaml file.
Note: If no fast lane cards are in this sprint the fast_lane structure won't appear in the json structure
The specified URL can contain placeholders which will be replaced:
:sprint => Current running sprint
:board => Board ID
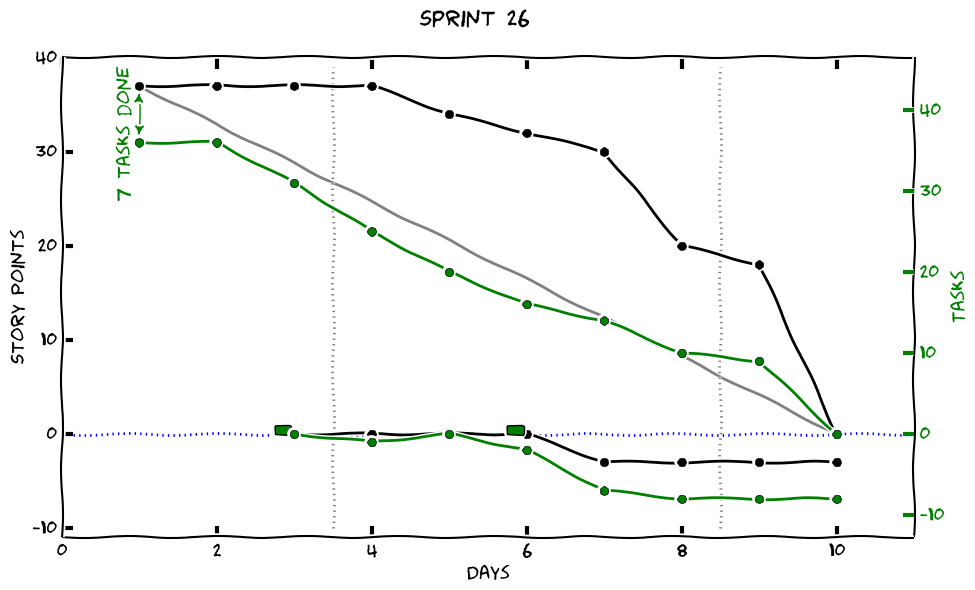
To generate the actual burndown chart, go to the working directory and call:
trollolo plot SPRINT_NUMBER
or fetch and plot data in one step with:
trollolo burndown --plot
This will take the data from the file burndown-data-SPRINT_NUMBER.yaml and
create a nice chart from it. It will show the chart and also create a file
burndown-SPRINT_NUMBER.png you can upload as cover graphics to a card on your
Trello board.
Some more info can be found in the command line help with trollolo help and
trollolo help burndown.
You can define swimlanes to exclude certain cards from the normal burndown data. This can be useful when you track work of multiple projects on the same board and you don't want to apply the full Scrum framework to all of them. An example would be a side project which you limit to one card in process.
Swimlanes are defined by putting a label with the name of the swimlane on all cards which belong to this swimlane. It does not matter in which column they are. To make Trollolo aware of the swimlane, you need to add an entry in the meta section of the burndown YAML such as:
meta:
swimlanes:
- My Side Project
This lets Trollolo exclude all cards which have the label with the name
My Side Project from the burndown chart.
The data for swimlane cards is collected separately in the burndown YAML
separated in todo, doing, and done values. This can be used to generate
statistics for the swimlanes. Trollolo currently only writes the raw data
but doesn't support any statistics such as generating graphs.
Trollolo by default looks for columns named such as Sprint Backlog, Doing,
or Done. If you need more or other names you can configure that in the burndown
YAML. Here is an example:
meta:
todo_columns:
- Main Backlog
- Swimlane Backlog
doing_columns:
- Doing
- Review
- QA
Trollolo supports SCRUM on Trello by using one board for the sprint and another one for planning. On these boards several lists are used to organize stories.
The setup-scrum command creates the necessary elements. The names are taken from the configuration.
If you change the names in Trello, you need to update theconfiguration in trollolorc.
At the end of a sprint, after the review meeting, remaining cards can be moved back to the planning
board with cleanup-sprint.
Once the sprint backlog is ready, priorities can be added to the card titles with prioritize.
Move the planning backlog to the sprint board with move-backlog.
sticky: used to mark cards which are not moved, like the goal cardwaterline: for cards which are under the waterline
sprint_backlog: this list contains the stories of the current sprintsprint_qa: any cards in the current sprint which need QAsprint_doing: cards currently being worked onplanning_backlog: used to plan the next sprint, these cards will be prioritizedplanning_ready: contains cards which are not yet estimated and therefore not in the backlog
These are the default names, add this to trollolorc and change as necessary.
scrum:
board_names:
planning: Planning Board
sprint: Sprint Board
label_names:
sticky: Sticky
waterline: Waterline
list_names:
sprint_backlog: Sprint Backlog
sprint_qa: QA
sprint_doing: Doing
planning_backlog: Backlog
planning_ready: Ready for Estimation
The board names are not used to find the boards on trello. Since several boards can share the same name, they are only used when creating the SCRUM setup.
Create the boards and lists:
trollolo setup-scrum
Lookup the ID of the created boards and use them as arguments:
# https://trello.com/b/123abC/sprint-board
# https://trello.com/b/GHi456/planning-board
trollolo cleanup-sprint --board-id=123abC --target-board-id=GHi456
trollolo set-priorities --board-id=GHi456
trollolo move-backlog --planning-board-id=GHi456 --sprint-board-id=123abC
You can use aliases, as described in the configuration section, instead of IDs.