
Creating art from music through generative AI.
Explore the docs »
·
View Demo »
Table of Contents
The project's goal is to convert music into visual artwork using advanced techniques, enhancing the creative intersection of audio and visual domains. To achieve this, we use CLIP sound embeddings and a self-trained Diffusion Model as our image generator
CLIP is a deep learning model developed by OpenAI that is capable of understanding and associating images and text in a semantically meaningful way. It leverages a powerful vision model and a language model trained jointly on a large corpus of text and images.

The critical idea behind CLIP is that semantically similar text and images are placed closer together in this shared high-dimensional space. As a result, you can compare the embeddings of text and images to measure their similarity or dissimilarity. CLIP embeddings enable a wide range of applications, such as image retrieval based on textual queries, zero-shot classification, and more, by understanding the relationships between textual and visual information.
wav2CLIP is a robust audio representation learning method by distilling from Contrastive Language-Image Pre-training (CLIP). We use this library to build music CLIP embeddings for our dataset.
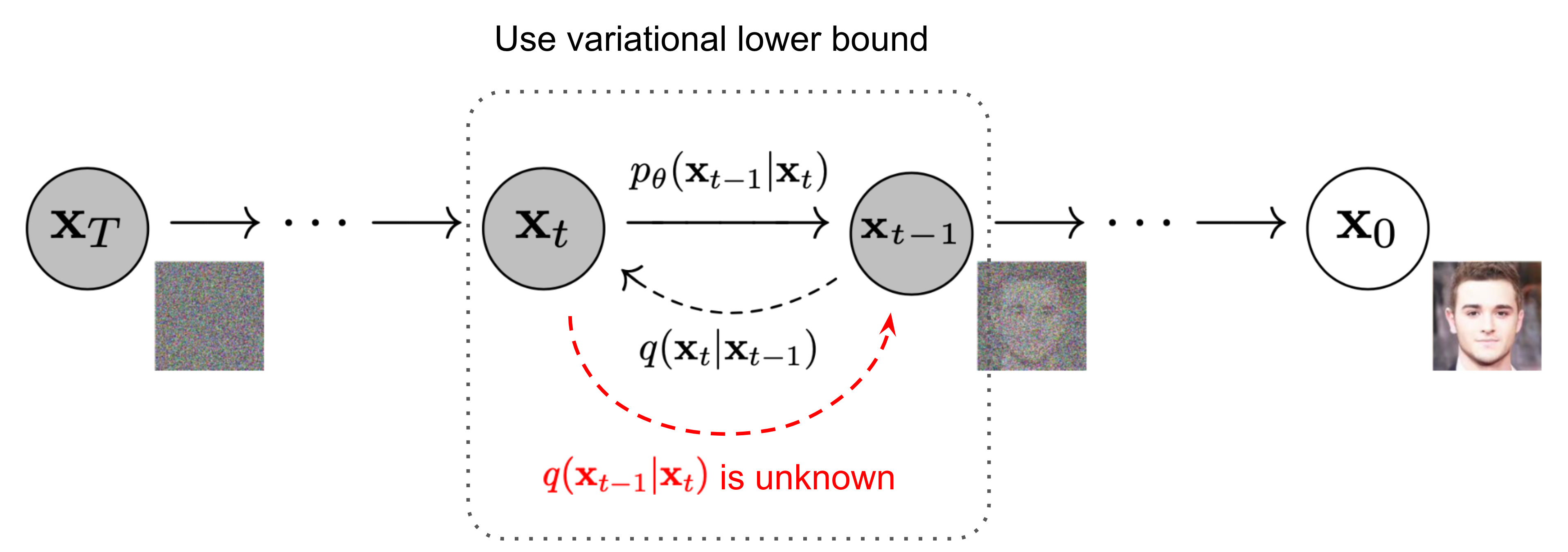
Given a data point sampled from a real data distribution, let us define a forward diffusion process in which we add small amount of Gaussian noise to the sample in T steps, producing a sequence of noisy samples. The step sizes are controlled by a variance schedule
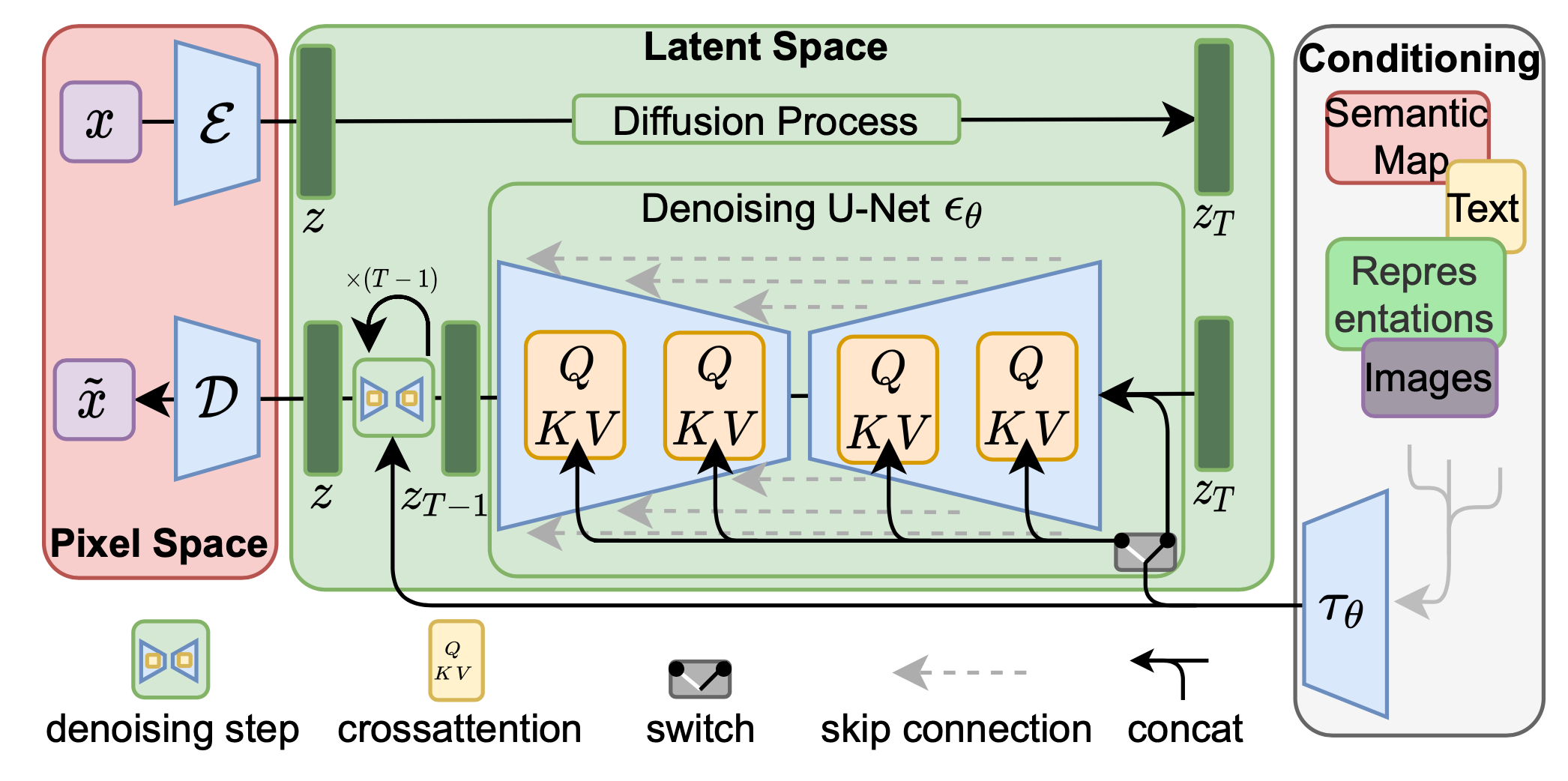
This is a U-Net based model to predict noise
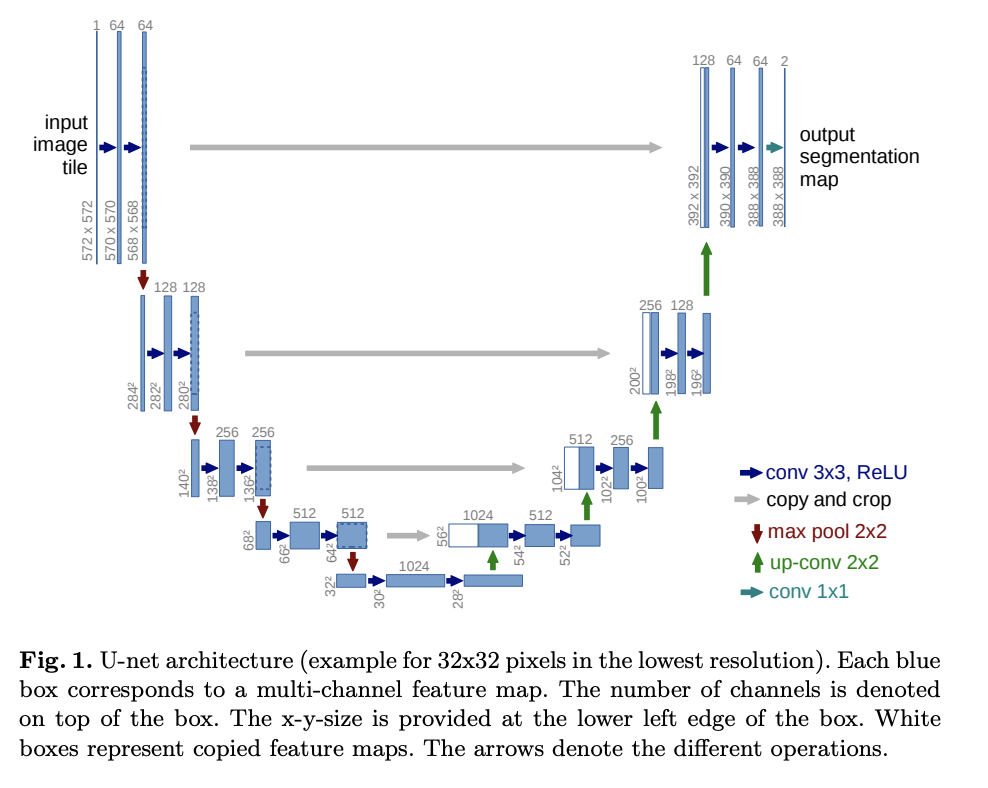
U-Net is a gets it's name from the U shape in the model diagram. It processes a given image by progressively lowering (halving) the feature map resolution and then increasing the resolution. There are pass-through connection at each resolution.
Distributed under the MIT License. See LICENSE for more information.