This lab will introduce some more advanced features of SQL and then proceed to introduce Dynamic Columns, and introduct a couple of data exchange formats (JSON and XML). In addition, by request, we are going to revisit the coordinated subquery idea.
- Lab5: Views, Constraints, Procedures, Dynamic Columns, JSON and XML
- Dealing with objects and communication
A view is a virtual table. Instead of creating an actual table, you specify a query that is run "behind-the-scenes".
Consider this query on our randA and randB from the previous lab (don't run it... if you do then you will likely want to open another mysql session and kill it):
SELECT randA.A AS link,
randA.B AS first_B,
randB.B AS second_B
FROM randA, randB
WHERE randA.A=randB.A
ORDER BY randA.A Let's get a sense for what the data should look like:
SELECT randA.A AS link,
randA.B AS first_B,
randB.B AS second_B
FROM randA, randB
WHERE randA.A=randB.A
ORDER BY randA.A LIMIT 10;We can take this query and create a REAL table like this:
CREATE TABLE joined
SELECT randA.A AS link,
randA.B AS first_B,
randB.B AS second_B
FROM randA, randB
WHERE randA.A=randB.A
ORDER BY randA.A;You can override the columns names if you like... see about 2/3rds of the way down here for details:
https://mariadb.com/kb/en/create-table/
But instead of doing something that permanent, we are going to create a view instead. So drop that table first:
DROP TABLE joined;Now let's create the view:
CREATE VIEW joined AS
SELECT randA.A AS link,
randA.B AS first_B,
randB.B AS second_B
FROM randA, randB
WHERE randA.A=randB.A
ORDER BY randA.A;Now you can treat joined pretty much like any table, but it's not
actually a table, it's a virtual table that provides a view onto
this organization of the data in tables randA and randB.
The nice thing about views is that you can use them to hid (or abstract out) complex SQL. For example, consider your inventory and prices tables. Suppose you needed to create a report and want your output to look like this:
<10 characters worth of item--padded if necessary by *'s>[<amount>](<price>)
So if you had pumpkins as an item, with an amount of 14 and a price of $10.13 then you would want your output to look like this:
pumpkin***[14]($10.13)
Okay... make that happen. You'll probably have to review the mariaDB string functions. I found it to be a bit of a pain in the butt, but still doable. But now convert your query into a view called ticketItem and call the calculated column output by the same name:
<I'll wait for you to figure that out>
Now you should be able to do this:
SELECT * FROM ticketItem;You might also find it useful to create views that apply some sort of filter to your raw data.
If you have the STORE ROUTINE privilege, then you can create a function that can be called by mariaDB just like any other function. Instead of a view, let's create a function to generate pumpkin***[14]($10.13)
The basic setup requires a bit of care… first the overview.
We create a function using CREATE FUNCTION and delete it using DROP FUNCTION.
Let's start with a basic outline:
CREATE FUNCTION ticketize RETURNS TEXT DETERMINISTIC
BEGIN
….
ENDI hope the pieces make sense. We give the CREATE FUNCTION keywords, then the name of the function. That's followed by RETURNS and then the data type. The data type is, not surprisingly, the same data types you use for the columns in a table. The DETERMINISTIC keyword tells the DBMS that the function will always return the same value for the same inputs (you might be able to see where this information could be useful for a system that wants to build query results as efficiently as possible).
The BEGIN and END (shades of Pascal... or Ruby if you're younger) act as brackets on the function's definition.
You must declare variables using
DECLARE <varname> <datatype>;
You assign values shudder using
SET <varname> = <value>;
And when you return the value you have to return a variable of the proper type.
You might think that this would work:
CREATE FUNCTION FortyTwo() RETURNS TINYINT DETERMINISTIC
BEGIN
DECLARE x TINYINT;
SET x = 42;
RETURN x;
ENDExcept that the ; is interpreted by the mariaDB client incorrectly.
DELIMITER //
CREATE FUNCTION FortyTwo() RETURNS TINYINT DETERMINISTIC
BEGIN
DECLARE x TINYINT;
SET x = 42;
RETURN x;
END
//
DELIMITER ;Arguments are defined between the parenthesis just like columns in the CREATE TABLE command.
Now go read the following link (and see how much of the above I pinched from that page):
https://mariadb.com/kb/en/stored-function-overview/
Okay… make your function work… you should be able to adapt your query from the view section.
If you get it working correctly, then you should be able to do this:
mysql> select ticketize("pumpkin",20,1.23);
+------------------------------+
| ticketize("pumpkin",20,1.23) |
+------------------------------+
| pumpkin***[20]($1.23) |
+------------------------------+
1 row in set (0.06 sec)
Now read the MariaDB page on user defined variables, but skim over PREPARE. Also read the page about assignment operators
Give this a try:
SET @a=0;And then this:
SELECT @a;now leave MariaDB, come back in, and do it again
SELECT @a;Now do this:
SELECT *,(@a:=@a+1) AS counter FROM inventory;What's with all the NULLS? Fix it by assigning a value to @a BEFORE the query.
<I'll wait>
Now modify the query above so that @a is replaced with @a+1 if @a<10, but is set to 1 otherwise. (The if function might be useful.) Run your query 3 or 4 times.
<Waiting again>
Modify the query above (again) so that item is concatenated with @a (you will probably want to reset the value using SET @a="";between queries.
<still here>
Now try to come up with some way to do what you did above, but suppress the output. I found a way to do it that just generates a blank column…. but there might be a better way. Let me know what you find.
<waiting hopefully>
This is, so to speak, the scripting language, of mariaDB... of course the technology was developed quite some time ago so it's showing its age. The ability to execute a stored procedure is distinct from the ability to create one:
https://mariadb.com/kb/en/grant/#procedure-privileges
One stores a procedure using CREATE PROCEDURE (begin mindful of the delimiter issue):
DELIMITER //
CREATE PROCEDURE averageprice()
BEGIN
SELECT AVG(price) AS price_avg
FROM prices;
END//
DELIMITER ;Okay, now you call the stored procedure by name:
CALL averageprice();You remove a stored procedure using DROP PROCEDURE (or DROP PROCEDURE IF EXISTS)
Now read the topics in the link below. Skip over the one on binary logging and the one on SHOW PROCEDURE CODE(because I have not enabled debugging). As you read, bear in mind that the ability to call CREATE PROCEDURE requires the CREATE ROUTINE privilege (I find this naming convention disturbing... why not call the privilege the CREATE PROCEDURE privilege?). Also notice that we can define parameters for a procedure just as we did for functions… but we ALSO have the ability to CHANGE the contents of a parameter (read the examples carefully in the create-procedure topic). Also pay attention to the INTO clause (which is part of SELECT), which allows you to assign the output of a single value query into a variable:
https://mariadb.com/kb/en/library/stored-procedures/
Also note that it is possible to have the stored-procedure run as the DEFINER rather than the INVOKER (which is occasionally useful, and occasionally a security nightmare).
Procedures are, by default, associated with the current database.
Let's do one that returns the min, max and average values from a table and stores them in the variables of our choosing (NOTE: I used DECIMAL(5,2) for my prices):
DELIMITER //
CREATE PROCEDURE summary(
OUT pmin DECIMAL(5,2),
OUT pmax DECIMAL(5,2),
OUT pavg DECIMAL(5,2)
)
BEGIN
SELECT MIN(price) INTO pmin FROM prices;
SELECT MAX(price) INTO pmax FROM prices;
SELECT AVG(price) INTO pavg FROM prices;
END//
DELIMITER ;Now call it:
CALL summary(@mymin, @mymax, @myavg);And then check that it worked:
SELECT @mymin, @mymax, @myavg;There used to be a section here on constraints, which are a way of telling the database that certain operations should be forbidden. How mariaDB handles constraints changed a lot in version 10.2, and we're currently using 10.0, making most of this obsolete. We'll just skip constraints for now.
Triggers allow an action in a database (such as a DELETE action) to cause another action to occur as well (such as an INSERT action).
Duke University has a good reference to the syntax, and MariaDB's documentation has some good examples too.
Trigger Exercise
- Copy your
pricesdatabase to one calledTR_prices. - Ensure that
TR_priceshas anotesfield. - CREATE two archive tables with the same structure as
TR_prices:TR_archiveAandTR_archiveB - Create a trigger that occurs when attempting to delete a row from TR_prices.
- If the row to be deleted has your name in the notes field make a copy of the record in
TR_archiveA, - Otherwise make a copy of the record in
TR_archiveB
- If the row to be deleted has your name in the notes field make a copy of the record in
Recall that A correlated subquery is a subquery that uses values from the outer query. The subquery is evaluated once for each row processed by the outer query. (heavily edit Wikipedia quote). The Wikipedia entry that I had you read last lab has a couple of great examples, so do the following:
Correlated Subquery Exercise Each group (remember to tell me whose database has the group's works in canvas), should do the following:
- Create a table named
CSQ_employeewith the following fields:- employee_number: INT
- salary: FIXED(6,2)
- department_ID: INT
- employee_name: TEXT
- Create a table named
CSQ_dept_lookup:- department_ID: INT
- depatment_name: TEXT
Add 10 departments to your CSQ_dept_lookup using whatever reasonable names you prefer (this means names we would not be afraid to show to the parents of prospective students). The IDs should range from 1 to 10-- make them a primary key for the table.
For the other table, it would be nice to have closer to 200 names. You can use random name generator. To make them. The link I provided generates up to 50 at a time-- you'll need to generate them, and copy and paste them into a text file. After you have the 200 names, use LOAD DATA LOCAL INFILE to fill the records. The SET keyword will allow you to use the RAND(), ROUND() or FLOOR() functions to generate reasonable salaries (shoot for values between $35,000 and $120,000. You can also use these functions to randomly generate department IDs for your fictitious people.
Those of you with some knowledge of statistics will recognize that RAND() generates numbers according to a uniform random distribution (equally likley possibilities). Various techniques are available for working around that issue, but we don't need to be particularly fancy for this exercise.
Once you have the entries in your tables perform the examples in the Wikipedia page (suitably modified).
There is more than one way to communicate commands or receive results from a database server. You have entered commands by hand using a text-based client. You can also use the SOURCE command
From the shell (in the same directory from which you will launch the mariadb host), create the file "test.sql". The contents should be:
SELECT * FROM <dbf>.inventory;Now start mariadb and execute this command:
SOURCE test.sql; You can also do the same thing (from the shell) via:
mysql -u[your name] -p --host=ids --port=[your port] [your database] < test.sql NOTE: I usually use angle brackets to denote things that you will replace... but in the example above I needed to use the < symbol as a pipe character, so I used [] instead of <>.
You can also do something like this:
mysql -u[your name] -p --host=ids --port=[your port] [your database] -e "SELECT * FROM [dbf].inventory"As some point you are going to have to wrap your head around two data exchange formats: XML and JSON. Both are ways of representing data that can be organized using a tree structure, but each has its advantages and disadvantages.
As a thought experiment, imagine that you are writing some Java code and your program has an object which you would really like to pass to another program running on a different computer. How would you do it?
Question One: Are we going to pass the entire object (methods included), or do we only care about the data values (this question is a bit wonky because on some level there's no difference-- a method is just data that can be executed… but let's pretend there's a distinction)?
Answer One: We are only going to concern ourselves with the data in the object-- we'll assume that the program on the other side already has the class defined.
Question Two: How do we compress the information in a meaningful fashion that can be sent over a network connection?
Answer Two: ????
Answer Three: Profit!
Both XML and JSON can address these issues.
The trick behind JSON, is to turn the object into a string that is syntactically correct JavasSript. Since JavaScript is an evaluated language, the string can be transferred and then evaluated upon receipt. Here's an example compliments of Wikipedia:
{ "firstName": "John",
"lastName": "Smith",
"age": 25,
"address": {
"streetAddress": "21 2nd Street",
"city": "New York",
"state": "NY",
"postalCode": 10021
},
"phoneNumbers": [
{
"type": "home",
"number": "212 555-1234"
},
{
"type": "fax",
"number": "646 555-4567"
}
]
}Just for fun, open up your javascript console
Copy the JSON string above to the clipboard. In the browser's console type example=, then paste the JSON string. You may now hit enter. (Microsoft's Edge Browser is a bit different-- but you get the idea)
Typing example<enter> in the console should give you access to an attribute viewer of some sort (the exact details depend upon the browser).
Play around with the contents of this for awhile. The object inspector will show you the structure but you can interact with the properties in a bit more of a classic manner-- using print(Object.keys(example)) or Object.keys(example).
As expected, you can access individual entries (capitalization matters) using dot or bracket notation:
example.firstNameexample["firstName"]
The dot notation is often easier to read, but lacks the flexibility of the bracket notation; In particular, the bracket notation allows the use of variables:
property="lastName"
example[property]If the return value isn't atomic you'll get back something that can be clicked or otherwise manipulated to open an object or array browers:
example.phoneNumbers[0] example.phoneNumbers["0"]An array (in Javascript) is really just a special type of object. It has some extra methods, but under the hood it is just a collection of attribute:value pairs (just like all the other objects):
example.phoneNumber[0]
example.phoneNumbers["0"]But the dot notation does not allow attributes (or properties as they tend to be called in Javascript) to start with a number. so
example.phoneNumber.0will give you an error.
This slideshow gives a good overview and introduces us to how we can interface MariaDB with JSON data. I understand that the stuff on dynamic columns will be a bit mysterious (we will get back to that down below). What I want you to get out of this is a better feel for JSON, and a back-of-the-head awareness of how one might start going about interfacing the two technologies:
Now that you have a few examples under your belt here's a very good overview of the structure of JSON (that is totally incomprehensible without the experiences you've already had): http://www.json.org/.
NOTE JSON objects are the fundamental data structures underlying MongoDB-- a NoSQL database that we will spend some time with later. We might as well play around with it a little bit.
Dynamic Column Exercise
Each group should do the examples in the tutorial below in a database of one of their members (be sure to indicate which in the Wiki group page for this lab). BUT... change the names of the tables to start with DC_ (for example, items would become DC_items) This will ensure A) I can find the tables easily, and B) we won't run into name conflicts with our own work.
- MariaDB Introduction to Dyanamic Columns (part 1)
- Part II of the Introduction
- More details Pay particular attention to the
COLUMN_JSONkeyword.
The XML protocol has been around longer than JSON and is more free form. (It also seems to scare people… I don't know why… perhaps it's the spooky X at the beginning) People find it harder to parse by eye.
Let's start with a basic introduction to XML: http://www.w3schools.com/xml/xml_whatis.asp
Continue until you reach the section on using CSS to make the XML visible as a more normal web page (that's probably outside our paygrade in this class). One key thing to notice (as I mentioned earlier) is that any document in a well-formed XML document can be thought of as a tree. Go to the XML CD catalog example from the last tutorial.
<img src="http://personal.morris.umn.edu/~dolan118/cs4453/images/xml1.png" width="400px",height="200px">
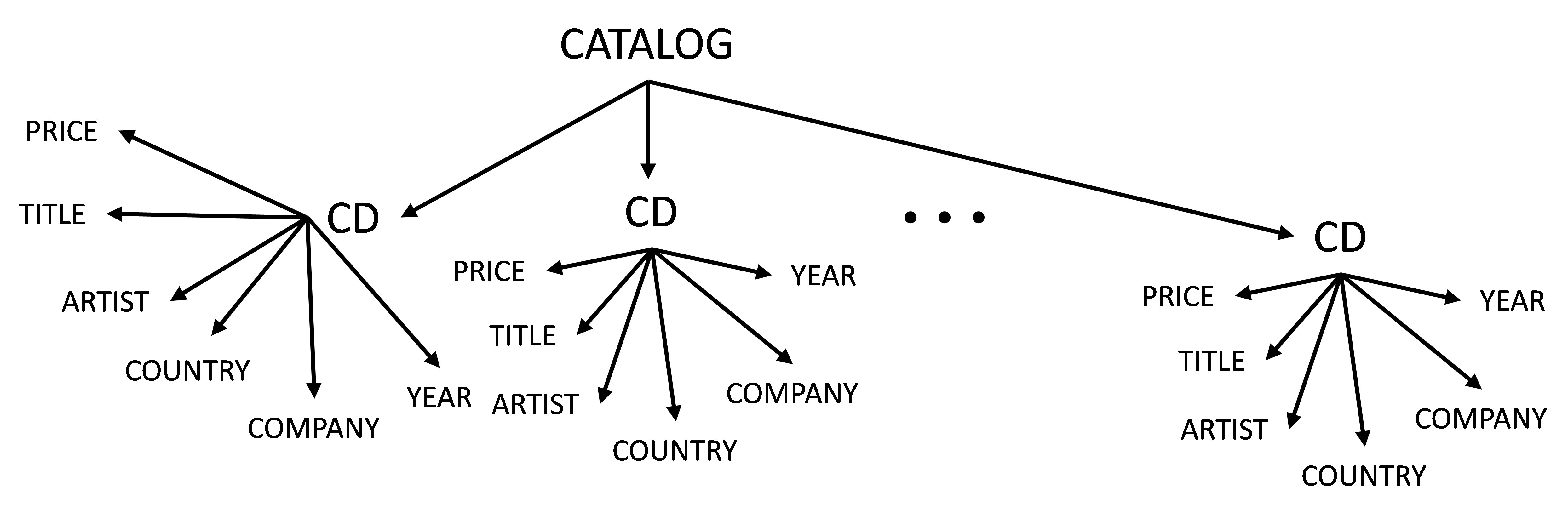{kind=link}
I truncated the tree before reaching the actual data... but I think it's enough to give you a sense of how the structure works. Think about how you would express this information in an SQL database in 3rd normal form. (Don't actually make these tables... just think about it).
We can actually turn any of our queries into XML. Try this:
mysql --xml -u <your name> -p --host=ids -e 'show databases'And then this:
mysql --xml -u <your name> -p --host=ids -e 'select * from <your dbf>.inventory' By now you should have a pretty good sense of how the --xml flag lets you create XML output for a query and how it encodes it.
Here is documentation on the command that pulls information in from XML back to a table:
https://mariadb.com/kb/en/load-xml/
Let's scrape the cd information our online source. Do this from the shell:
wget http://www.w3schools.com/xml/cd_catalog.xml Now you are going to actually have to go in and make the table CD. For now, let's just set it up like this (make all the fields text):
cds
PRICE
TITLE
ARTIST
COUNTRY
COMPANY
YEAR
They should all be text. See if you can use the -e parameter and do it from the command line.
This will pull the contents of the webpage to the directory that you are in. Log in as usual, and check that the cd_catalog.xml file has been created. Let's convert the data in the XML file into records in the table:
LOAD XML LOCAL INFILE 'cd_catalog.xml' INTO TABLE cds ROWS IDENTIFIED BY '<CD>';(this time the angle brackets are actually necessary)
So... now you can output a query as XML (notice that this tends to use ATTRIBUTES instead of ELEMENTS), and you can import data from XML (as long as the DEPTH of the tree isn't too deep)
Hidden behind the scenes of a table is the Storage Engine used to control the nuts-and-bolts of how the table is managed. Different engines have different capabilities and may be more (or less) efficient at certain operations.
The MariaDB dcoumentation on storage engines provides a decent overview of the various available engines, but it's a bit confusing at first so just skim over the entries.
The command SHOW ENGINES. Will reveal what engines are currently available (more may be loaded or unloaded) and which engine is the default. The particular engine that is used by default in my server is InnoDB which (as you can see) supports transactions. The CREATE TABLE command supports a STORAGE ENGINE clause which allows you to determine which storage engine that the table uses (we will play around with this a bit using the CSV option). To determine the storage engine you may use this command:
SHOW TABLE STATUS WHERE Name='<table name>';This engine does not occur in mySQL. It only appears in MariaDB 10.0.0.0 and later. It is pretty darn cool however and it allows you to access a whole slew of interesting file types and treat them as if they were tables. There is a LOT to read (do go through it-- we will cover some of this later):
https://mariadb.com/kb/en/mariadb/connect/
-
Make sure your canvas group matches your github group and submit your groups repository URL
-
Also submit the database that contains your group's work
-
Do all the examples. Make certain at least one person in your group has
- Created the View
- Created the
Ticketizefunction - Created the summary procedure
-
Read the following:
- https://mariadb.com/kb/en/create-table/
- https://mariadb.com/kb/en/stored-function-overview/
- the MariaDB page on user defined variables
- page about assignment operators
- https://mariadb.com/kb/en/grant/#procedure-privileges
- https://mariadb.com/kb/en/stored-procedures/
- https://mariadb.com/kb/en/20-sql-constraints-and-assertions-constraint/
- Duke University reference on triggers
- MariaDB's documentation on triggers
- MariaDB Introduction to Dyanamic Columns (part 1)
- Part II of the Introduction
- More details Pay particular attention to the
COLUMN_JSONkeyword. - http://www.w3schools.com/xml/xml_whatis.asp
- https://mariadb.com/kb/en/load-xml/
- MariaDB documentation on storage engines
- https://mariadb.com/kb/en/mariadb/connect/
-
Do the following Exercises:
- The Trigger Exercise
- The Correlated Subquery Exercise
- The Dynamic Column Exercises