A one page study guide for the below Watson Certification exam:
Exam Test C7020-230 - IBM Watson V3 Application Development
The certification exam covers all of the aspects of building an application that uses Watson services. This includes a basic understanding of cognitive technologies, as well as a practical knowledge of the core APIs. Get up to speed with these resources:
The aim of this doc is to provide a more consolidated view of the required reading and study that is outlined in the IBM Watson Professional Certification Program Study Guide Series.
The Watson services are constantly evolving so always reference back to the Watson Documentation. Please also feel free to contribute or provide feedback if you see anything that is incorrect.
Watson is accessed through IBM Bluemix
-
1.6 Explain the importance of separating training, validation and test data.
-
1.8 Perform Domain Adaption using Watson Knowledge Studio (WKS).
-
1.11 Define the difference between the user question and the user intent.
-
2.1 Select appropriate combination of cognitive technologies based on use-case and data format.
-
2.2 Explain the uses of the Watson services in the Application Starter Kits.
-
2.4 Explain use cases for integrating external systems (such as Twitter, Weather API).
-
3.1 Distinguish cognitive services on WDC for which training is required or not.
-
3.3 Explain the Watson SDKs available as part of the services on Watson Developer Cloud.
-
3.4 Explain the Watson REST APIs available as part of the services on Watson Developer Cloud.
-
Section 4 - Developing Cognitive applications using Watson Developer Cloud Services
-
4.2 Describe the tasks required to implement the Conversational Agent / Digital Bot.
-
4.3 Transform service outputs for consumption by other services.
-
4.4 Define common design patterns for composing multiple Watson services together (across APIs).
-
4.5 Design and execute a use case driven service choreography (within an API).
-
Section 5 - Administration & DevOps for applications using IBM Watson Developer Cloud Services
-
5.1 Describe the process of obtaining credentials for Watson services.
-
5.2 Monitor resource utilization of applications using IBM Watson services.
- Cognitive systems understand, reason and learn
- Must understand structured and unstructured data
- Must reason by prioritizing recommendations and ability to form hypothesis
- Learns iteratively by repeated training as it build smarter patterns
- Cognitive systems are here to augment human knowledge not replace it
- Cognitive systems employ machine learning technologies
- Supervised learning versus unsupervised learning
- Cognitive systems use natural language processing
https://github.com/cazala/synaptic/wiki/Neural-Networks-101
- Neural Nets mimic how neurons in the brain communicate.
- Neural networks are models of biological neural structures.
Neurons are the basic unit of a neural network. In nature, neurons have a number of dendrites (inputs), a cell nucleus (processor) and an axon (output). When the neuron activates, it accumulates all its incoming inputs, and if it goes over a certain threshold it fires a signal thru the axon.. sort of. The important thing about neurons is that they can learn.
Artificial neurons look more like this:
Video:
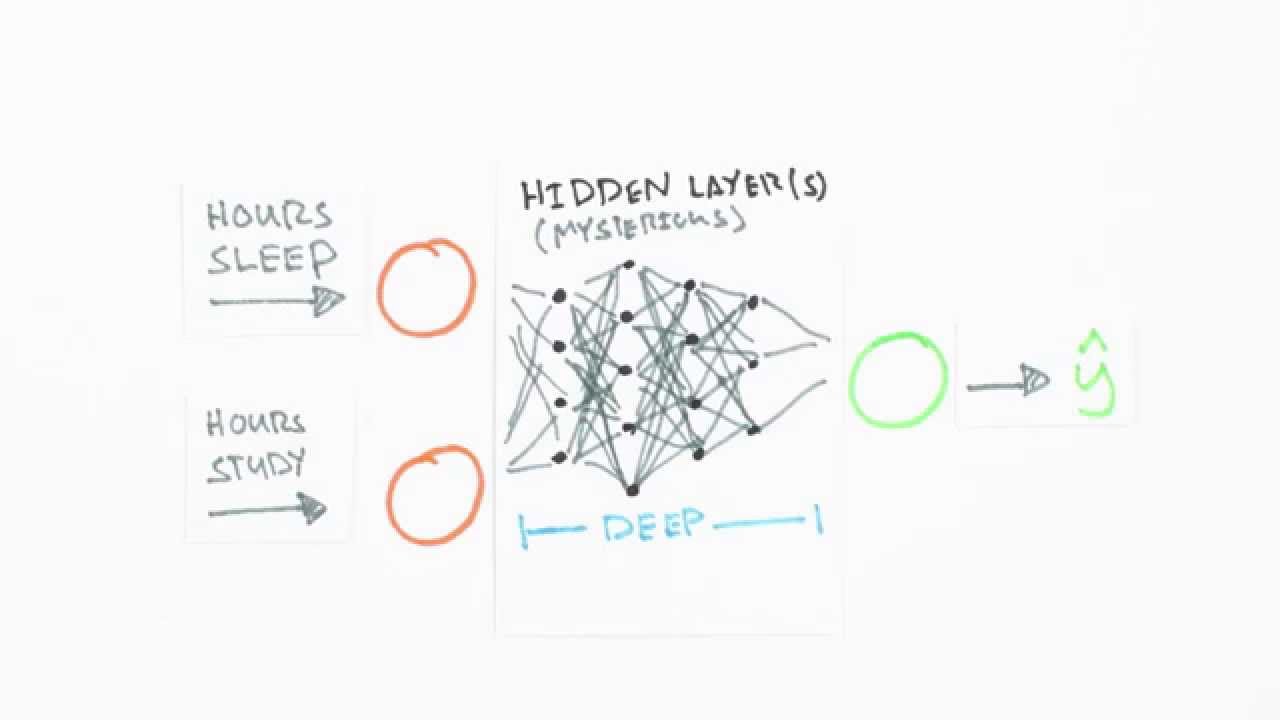
So how does a Neural Network learn? A neural network learns by training. The algorithm used to do this is called backpropagation. After giving the network an input, it will produce an output, the next step is to teach the network what should have been the correct output for that input (the ideal output). The network will take this ideal output and start adjusting the weights to produce a more accurate output next time, starting from the output layer and going backwards until reaching the input layer. So next time we show that same input to the network, it's going to give an output closer to that ideal one that we trained it to output. This process is repeated for many iterations until we consider the error between the ideal output and the one output by the network to be small enough.
- A nueron operates by recieving signals from other nuerons through connections called synapses.
- For each nueron input there is a weight (the weight of that specific connection).
- When a artifical neuron activates if computes its state by adding all the incoming inputs multiplied by it's corresponding connection weight.
- But Neurons always have one extra input, the bias which is always 1 and has it's own connection weight. THis makes sure that even when all other inputs are none there's going to be activation in the nueron.
Types of artificial neural networks
A feedforward neural network is an artificial neural network wherein connections between the units do not form a cycle. As such, it is different from recurrent neural networks. In this network, the information moves in only one direction, forward, from the input nodes, through the hidden nodes (if any) and to the output nodes. There are no cycles or loops in the network.
Video:

Backpropagation, an abbreviation for "backward propagation of errors", is a common method of training artificial neural networks used in conjunction with an optimization method such as gradient descent. It calculates the gradient of a loss function with respect to all the weights in the network, so that the gradient is fed to the optimization method which in turn uses it to update the weights, in an attempt to minimize the loss function.
Backpropagation requires a known, desired output for each input value in order to calculate the loss function gradient – it is therefore usually considered to be a supervised learning method; nonetheless, it is also used in some unsupervised networks such as autoencoders. It is a generalization of the delta rule to multi-layered feedforward networks, made possible by using the chain rule to iteratively compute gradients for each layer. Backpropagation requires that the activation function used by the artificial neurons (or "nodes") be differentiable.
But how does the backpropagation work? This algorithm adjusts the weights using Gradient Descent calculation. Let's say we make a graphic of the relationship between a certain weight and the error in the network's output:
This algorithm calculates the gradient, also called the instant slope (the arrow in the image), of the actual value of the weight, and it moves it in the direction that will lead to a lower error (red dot in the image). This process is repeated for every weight in the network.
The goal of any supervised learning algorithm is to find a function that best maps a set of inputs to its correct output. An example would be a classification task, where the input is an image of an animal, and the correct output would be the name of the animal. The goal and motivation for developing the backpropagation algorithm was to find a way to train a multi-layered neural network such that it can learn the appropriate internal representations to allow it to learn any arbitrary mapping of input to output.
Video:

Video:

(supervised, unsupervised, reinforcement learning approaches).
Reference: Computing, cognition and the future of knowing
Machine learning is a branch of the larger discipline of Artificial Intelligence, which involves the design and construction of computer applications or systems that are able to learn based on their data inputs and/or outputs. The discipline of machine learning also incorporates other data analysis disciplines, ranging from predictive analytics and data mining to pattern recognition. And a variety of specific algorithms are used for this purpose, frequently organized in taxonomies, these algorithms can be used depending on the type of input required.
Many products and services that we use every day from search-engine advertising applications to facial recognition on social media sites to “smart” cars, phones and electric grids are beginnin to demonstrate aspects of Artificial Intelligence. Most consist of purpose-built, narrowly focused applications, specific to a particular service. They use a few of the core capabilities of cognitive computing. Some use text mining. Others use image recognition with machine learning. Most are limited to the application for which they were conceived.
Cognitive systems, in contrast, combine five core capabilities:
-
- They create deeper human engagement.
-
- They scale and elevate expertise.
-
- They infuse products and services with cognition.
-
- They enable cognitive processes and operations.
-
- They enhance exploration and discovery.
Large-scale machine learning is the process by which cognitive systems improve with training and use.
Cognitive computing is not a single discipline of computer science. It is the combination of multiple academic fields, from hardware architecture to algorithmic strategy to process design to industry expertise.
Many of these capabilities require specialized infrastructure that leverages high-performance computing, specialized hardware architectures and even new computing paradigms. But these technologies must be developed in concert, with hardware, software, cloud platforms and applications that are built expressly to work together in support of cognitive solutions.
- A Tour of Machine Learning Algorithms
- List of machine learning concepts
- Supervised learning, unsupervised learning and reinforcement learning: Workflow basics
- We are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and output.
- In a classification problem we are trying to predict results in a discrete output. In other words we are trying to map input variables into categories.
- In a regression problem we are trying to predict results with a continous output meaning that we are trying to map input variables to some continous function.
- Semi-supervised learning are tasks and techniques that also make use of unlabeled data for training – typically a small amount of labeled data with a large amount of unlabeled data.
- Unsupervised learning is a type of machine learning algorithm used to draw inferences from datasets consisting of input data without labeled responses. Input data is not labeled and does not have a known result.
- An Artificial Neural Network (ANN) is an information processing paradigm that is inspired by the way biological nervous systems, such as the brain, process information.
- Association rule learning is a rule-based machine learning method for discovering interesting relations between variables in large databases. It is intended to identify strong rules discovered in databases using some measures of interestingness.
-
Hierarchical clustering is a method of cluster analysis which seeks to build a hierarchy of clusters. Strategies for hierarchical clustering generally fall into two types:
-
Agglomerative: This is a "bottom up" approach: each observation starts in its own cluster, and pairs of clusters are merged as one moves up the hierarchy.
-
Divisive: This is a "top down" approach: all observations start in one cluster, and splits are performed recursively as one moves down the hierarchy.
- Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense or another) to each other than to those in other groups (clusters).
- The local outlier factor is based on a concept of a local density, where locality is given by {\displaystyle k} k nearest neighbors, whose distance is used to estimate the density. By comparing the local density of an object to the local densities of its neighbors, one can identify regions of similar density, and points that have a substantially lower density than their neighbors. These are considered to be outliers.
- These algorithms choose an action, based on each data point and later learn how good the decision was. Over time, the algorithm changes its strategy to learn better and achieve the best reward. Thus, reinforcement learning is particularly well-suited to problems which include a long-term versus short-term reward trade-off.
Customer Call Centers
- Agent Assist: Q&A
- Problem Solved: Provides a natural language help system so call agents can rapidly retrieve answers to customer questions
- Services used: Conversation, natural language answer retrieval, keyword extraction, and entity extraction
- Automation: Customer/Technical Support Tickets Routing
- Customer: Go Moment
- Problems Solved:
- a) Detect the topic of a ticket and route to the appropriate department to handle it
- b) room service, maintenance, housekeeping
- c) Escalate support tickets based on customersentiment
- d) Route support requests to agents that already solved similar problems by detecting natural language similarities between new customer tickets and resolved ones.
- Services used: natural language (text) classification, keyword extraction, entity extraction, and sentiment/tone analysis
Physicians
- Expert Advisor:
- Example: Watson Discovery Advisor
- Problem Solved: Provides relevant medical suggestions and insights in natural language so physicians can more accurately diagnose patients.
- Services used: Conversation + natural language answer retrieval, entity extraction
Social Media
- Data Insights:
- Partner: Ground Signal
- Problem Solved: Extract useful insights from social media such as Instagram and Twitter by determining the content of photos and topics/sentiment of user posts.
- Services used: keyword, entity, and sentiment/tone analysis
- Definition: Precision is the percentage of documents labelled as positive that are actually positive.
- Formula: True Positives/(True Positives + False Positives)
- Recall is the percent of documents labelled as positive were successfully retrieved.
- Formula: True Positives/(True Positives + False Negatives)
- Accuracy is the fraction of documents relevant to a query that were successfully retrieved.
- Formula: (True Positives + True Negatives)/Total Document Count
Positive/Negatives described above: https://www.quora.com/What-is-the-best-way-to-understand-the-terms-precision-and-recall
Normally to perform supervised learning you need two types of data sets:
- In one dataset (your "gold standard") you have the input data together with correct/expected output, This dataset is usually duly prepared either by humans or by collecting some data in semi-automated way. But it is important that you have the expected output for every data row here, because you need for supervised learning.
- The data you are going to apply your model to. In many cases this is the data where you are interested for the output of your model and thus you don't have any "expected" output here yet.
While performing machine learning you do the following:
- Training phase: you present your data from your "gold standard" and train your model, by pairing the input with expected output.
- Validation/Test phase: in order to estimate how well your model has been trained (that is dependent upon the size of your data, the value you would like to predict, input etc) and to estimate model properties (mean error for numeric predictors, classification errors for classifiers, recall and precision for IR-models etc.)
- Application phase: now you apply your freshly-developed model to the real-world data and get the results. Since you normally don't have any reference value in this type of data (otherwise, why would you need your model?), you can only speculate about the quality of your model output using the results of your validation phase.
The validation phase is often split into two parts:
- In the first part you just look at your models and select the best performing approach using the validation data (=validation)
- Then you estimate the accuracy of the selected approach (=test).
Hence the separation to 50/25/25.
In case if you don't need to choose an appropriate model from several rivaling approaches, you can just re-partition your set that you basically have only training set and test set, without performing the validation of your trained model. I personally partition them 70/30 then.
The goal of the ML model is to learn patterns that generalize well for unseen data instead of just memorizing the data that it was shown during training. Once you have a model, it is important to check if your model is performing well on unseen examples that you have not used for training the model. To do this, you use the model to predict the answer on the evaluation dataset (held out data) and then compare the predicted target to the actual answer (ground truth).
A number of metrics are used in ML to measure the predictive accuracy of a model. The choice of accuracy metric depends on the ML task. It is important to review these metrics to decide if your model is performing well.
There is a great YouTube video series for Watson Knowledge Studio here:
Video:

IBM Watson Knowledge Studio is a cloud-based application that enables developers and domain experts to collaborate on the creation of custom annotator components that can be used to identify mentions and relations in unstructured text. Watson Knowledge Studio is:
- Intuitive: Use a guided experience to teach Watson nuances of natural language without writing a single line of code
- Collaborative: SMEs work together to infuse domain knowledge in cognitive applications
Use Watson™ Knowledge Studio to create a machine-learning model that understands the linguistic nuances, meaning, and relationships specific to your industry.
To become a subject matter expert in a given industry or domain, Watson must be trained. You can facilitate the task of training Watson with Watson Knowledge Studio. It provides easy-to-use tools for annotating unstructured domain literature, and uses those annotations to create a custom machine-learning model that understands the language of the domain. The accuracy of the model improves through iterative testing, ultimately resulting in an algorithm that can learn from the patterns that it sees and recognize those patterns in large collections of new documents.
The following diagram illustrates how it works.
[
- Based on a set of domain-specific source documents, the team creates a type system that defines entity types and relation types for the information of interest to the application that will use the model.
- A group of two or more human annotators annotate a small set of source documents to label words that represent entity types, words that represent relation types between entity mentions, and to identify coreferences of entity types. Any inconsistencies in annotation are resolved, and one set of optimally annotated documents is built, which forms the ground truth.
- The ground truth is used to train a model.
- The trained model is used to find entities, relations, and coreferences in new, never-seen-before documents.
Deliver meaningful insights to users by deploying a trained model in other Watson cloud-based offerings and cognitive solutions.
Watson services integration
Share domain artifacts and models between IBM Watson Knowledge Studio and other Watson services.
Use Watson Knowledge Studio to perform the following tasks:
- Bootstrap annotation by using the AlchemyLanguage entity extraction service to automatically find and annotate entities in your documents. When human annotators begin to annotate the documents, they can see the annotations that were already made by the service and can review and add to them. See Pre-annotating documents with IBM AlchemyLanguage for details.
- Import industry-specific dictionaries that you downloaded from IBM® Bluemix® Analytics Exchange.
- Import analyzed documents that are in UIMA CAS XMI format. For example, you can import UIMA CAS XMI files that were exported from IBM Watson Explorer content analytics collections or IBM Watson Explorer Content Analytics Studio.
- Deploy a trained model to use with the AlchemyLanguage service.
- Export a trained model to use in IBM Watson Explorer.
-
The Natural Language Classifier service available via WDC, enables clustering or classification based on some measure of inherent similarity or distance given the input data. Such clustering is known as intents or classes.
-
Where classes may include images, intent is a similar clustering for written utterances in unstructured natural language format.
-
Ground truth is used in both supervised and unsupervised machine learning approaches, yet portray different values and formats. For example, in a typical supervised learning system, ground truth consisted of inputs (questions) and approved outputs (answers). With the aide of logistical regression and iterative training the system improves in accuracy.
-
In unsupervised approach, such as NLC, the ground truth consists of a comma-separated csv or a JSON file that lists hundreds of sample utterances and a dozen or so intents (or classes) classifying those utterances.
To answer correctly, we need to understand the intent behind the question, in order to first classify it then take action on it (e.g., with a Dialog API)
- The user question is the verbatim question
- The user intent maps the user question to a known classification
- This is a form of classifying question based on search goals
- Intents are the superset of all actions your users may want your cognitive system to undertake. Put another way, questions are a subset of user intents. Questions usually end in "?", but sometimes we need to extract the user intent from the underlying context.
- Common examples of user intents:
- Automation: “Schedule a meeting with Sue at 5pm next Tuesday.”
- Declarative: “I need to change my password.”
- Imperative: “Show me the directions to my the nearest gas station.”
- Data: customer emails
- Services: Q&A, Text classification, entity extraction and, keyword extraction
- Watson-specific: NLC, R&R, Alchemy Language
- Data: customer voice recordings
- Services: Q&A, Speech recognition, text-to-speech, text classification, entity extraction, keyword extraction
- Watson-specific: NLC, R&R, Alchemy Language
- Data: natural language intents
- Services: Q&A, Text classification, entity extraction and keyword extraction
- Watson-specific: NLC, R&R, Alchemy Language
- Data: images
- Services: Image classification and natural OCR
- Watson-specific: Visual Insights
- Data: tweets
- Services: Text classification, entity extraction, keyword extraction
- Watson-specific: NLC and Alchemy Language
For section 2.2 and 2.3, we deep dive into the Watson services currently available and stated in the study guide. By understanding the services individually, it will help with knowing what services would work for different scenarios.
You can view the list of Watson Starter Kits here
The IBM Watson™ Natural Language Classifier service uses machine learning algorithms to return the top matching predefined classes for short text inputs. The service interprets the intent behind text and returns a corresponding classification with associated confidence levels. The return value can then be used to trigger a corresponding action, such as redirecting the request or answering a question.
The Natural Language Classifier is tuned and tailored to short text (1000 characters or less) and can be trained to function in any domain or application.
- Tackle common questions from your users that are typically handled by a live agent.
- Classify SMS texts as personal, work, or promotional
- Classify tweets into a set of classes, such as events, news, or opinions.
- Based on the response from the service, an application can control the outcome to the user. For example, you can start another application, respond with an answer, begin a dialog, or any number of other possible outcomes.
Here are some other examples of how you might apply the Natural Language Classifier:
- Twitter, SMS, and other text messages
- Classify tweets into a set of classes, such as events, news, or opinions.
- Analyze text messages into categories, such as Personal, Work, or Promotions.
- Sentiment analysis
- Analyze text from social media or other sources and identify whether it relates positively or negatively to an offering or service.
Text to a pre-trained model
Classes ordered by confidence
The process of creating and using the classifier:

Make sure that your CSV training data adheres to the following format requirements:
- The data must be UTF-8 encoded.
- Separate text values and each class value by a comma delimiter. Each record (row) is terminated by an end-of-line character, which is a special character or sequence of characters that indicate the end of a line.
- Each record must have one text value and at least one class value.
- Class values cannot include tabs or end-of-line characters.
- Text values cannot contain tabs or new lines without special handling. To preserve tabs or new lines, escape a tab with \t, and escape new lines with \r, \n or \r\n.
- For example, Example text\twith a tab is valid, but Example text with a tab is not valid.
- Always enclose text or class values with double quotation marks in the training data when it includes the following characters:
- Commas ("Example text, with comma").
- Double quotation marks. In addition, quotation marks must be escaped with double quotation marks ("Example text with ""quotation""").
There are size limitations to the training data:
- The training data must have at least five records (rows) and no more than 15,000 records.
- The maximum total length of a text value is 1024 characters.
The classifier supports English (en), Arabic (ar), French (fr), German (de), Japanese (ja), Italian (it), Portuguese (pt), and Spanish (es). The language of the training data must match the language of the text that you intend to classify. Specify the language when you create the classifier.
The following guidelines are not enforced by the API. However, the classifier tends to perform better when the training data adheres to them:
- Limit the length of input text to fewer than 60 words.
- Limit the number of classes to several hundred classes. Support for larger numbers of classes might be included in later versions of the service.
- When each text record has only one class, make sure that each class is matched with at least 5 - 10 records to provide enough training on that class.
- It can be difficult to decide whether to include multiple classes for a text. Two common reasons drive multiple classes:
- When the text is vague, identifying a single class is not always clear.
- When experts interpret the text in different ways, multiple classes support those interpretations.
- However, if many texts in your training data include multiple classes, or if some texts have more than three classes, you might need to refine the classes. For example, review whether the classes are hierarchical. If they are hierarchical, include the leaf node as the class.
More detailed documentation for Natural Language Classifier
AlchemyLanguage is a collection of APIs that offer text analysis through natural language processing. The AlchemyLanguage APIs can analyze text and help you to understand its sentiment, keywords, entities, high-level concepts and more.
Use one or all of the natural language processing APIs available through AlchemyLanguage to add high-level semantic information. Browse the documentation to learn more about each of AlchemyAPI's text analysis service functions:
- Entity Extraction
- Sentiment Analysis
- Emotion Analysis
- Keyword Extraction
- Concept Tagging
- Relation Extraction
- Taxonomy Classification
- Author Extraction
- Language Detection
- Text Extraction
- Microformats Parsing
- Feed Detection
- Linked Data Support
Any publicly-accessible webpage or posted HTML/text document.
Extracted meta-data including, entities, sentiment, keywords, concepts, relations, authors, and more, returned in XML, JSON, and RDF formats
More detailed documention for AlchemyLanguage
AlchemyData provides news and blog content enriched with natural language processing to allow for highly targeted search and trend analysis. Now you can query the world's news sources and blogs like a database.
AlchemyData News indexes 250k to 300k English language news and blog articles every day with historical search available for the past 60 days. You can query the News API directly with no need to acquire, enrich and store the data yourself - enabling you to go beyond simple keyword-based searches.
Highly targeted search, time series and counts for trend analysis and pattern mapping, and historical access to news and blog content.
Build a query with natural language processing to search both the text in indexed content and the concepts that are associated with it.
News and blog content enriched with our full suite of NLP services. Keywords, Entities, Concepts, Relations, Sentiment, Taxonomy
More detailed documentation for AlchemyData News
The IBM Watson™ Tone Analyzer Service uses linguistic analysis to detect three types of tones from text: emotion, social tendencies, and language style. Emotions identified include things like anger, fear, joy, sadness, and disgust. Identified social tendencies include things from the Big Five personality traits used by some psychologists. These include openness, conscientiousness, extroversion, agreeableness, and emotional range. Identified language styles include confident, analytical, and tentative.
- Personal and business communications - Anyone could use the Tone Analyzer service to get feedback about their communications, which could improve the effectiveness of the messages and how they are received.
- Message resonance - optimize the tones in your communication to increase the impact on your audience
- Digital Virtual Agent for customer care - If a human client is interacting with an automated digital agent, and the client is agitated or angry, it is likely reflected in the choice of words they use to explain their problem. An automated agent could use the Tone Analyzer Service to detect those tones, and be programmed to respond appropriately to them.
- Self-branding - Bloggers and journalists could use the Tone Analyzer Service to get feedback on their tone and fine-tune their writing to reflect a specific personality or style.
Any Text
JSON that provides a hierarchical representation of the analysis of the terms in the input message
Mored detailed documentation for Tone Analyzer
Deprecated as of August 15, 2016 still in the test
The IBM Watson Dialog service enables a developer to automate branching conversations between a user and your application. The Dialog service enables your applications to use natural language to automatically respond to user questions, cross-sell and up-sell, walk users through processes or applications, or even hand-hold users through difficult tasks. The Dialog service can track and store user profile information to learn more about end users, guide them through processes based on their unique situation, or pass their information to a back-end system to help them take action and get the help they need.
Walk a user through the steps to reset their password or help them choose a credit card. Developers script conversations as they would happen in the real world, upload them to the Dialog application and allow end users to get the help they need. This service should be used to enable back and forth conversations with a user. For example, clarifying questions, information gathering, walkthroughs and helping a user take an action.
Script conversations based on your expert knowledge of the domain.
End users can chat with your application using natural language and get the pre-written responses you created.
More detailed documentation for Watson Dialog
Tradeoff Analytics is a Watson service that helps people make decisions when balancing multiple objectives. The service uses a mathematical filtering technique called “Pareto Optimization,” that enables users to explore tradeoffs when considering multiple criteria for a single decision. When your company makes decisions, how many factors need to be considered? What’s the process like? How do you know when you’ve found the best option? With Tradeoff Analytics, users can avoid lists of endless options and identify the right option by considering multiple objectives.
Tradeoff Analytics can help bank analysts or wealth managers select the best investment strategy based on performance attributes, risk, and cost. It can help consumers purchase the product that best matches their preferences based on attributes like features, price, or warranties. Additionally, Tradeoff Analytics can help physicians find the most suitable treatment based on multiple criteria such as success rate, effectiveness, or adverse effects.
A decision problem with objectives and options (for example, what is the best car when my goals are type, price, and fuel economy?)
JSON objects that represent the optimal options and highlight the trade-offs between them. The service recommends using a provided client-side library to consume its JSON output.
For more detailed documentation for Tradeoff Analytics
Watson Conversation combines a number of cognitive techniques to help you build and train a bot - defining intents and entities and crafting dialog to simulate conversation. The system can then be further refined with supplementary technologies to make the system more human-like or to give it a higher chance of returning the right answer. Watson Conversation allows you to deploy a range of bots via many channels, from simple, narrowly focused Bots to much more sophisticated, full-blown virtual agents across mobile devices, messaging platforms like Slack, or even through a physical robot.
- Add a chatbot to your website that automatically responds to customers’ most frequently asked questions.
- Build Twitter, Slack, Facebook Messenger, and other messaging platform chatbots that interact instantly with channel users.
- Allow customers to control your mobile app using natural language virtual agents.
Your domain expertise in the form of intents, entities and crafted conversation
A trained model that enables natural conversations with end users
With the IBM Watson™ Conversation service, you can create an application that understands natural-language input and uses machine learning to respond to customers in a way that simulates a conversation between humans.
This diagram shows the overall architecture of a complete solution:

- Users interact with your application through the user interface that you implement. For example, A simple chat window or a mobile app, or even a robot with a voice interface.
- The application sends the user input to the Conversation service.
- The application connects to a workspace, which is a container for your dialog flow and training data.
- The service interprets the user input, directs the flow of the conversation and gathers information that it needs.
- You can connect additional Watson services to analyze user input, such as Tone Analyzer or Speech to Text.
- The application can interact with your back-end systems based on the user’s intent and additional information. For example, answer question, open tickets, update account information, or place orders. There is no limit to what you can do.
More detailed documentation for Watson Conversation
The Watson Language Translator service provides domain-specific translation utilizing Statistical Machine Translation techniques that have been perfected in our research labs over the past few decades. The service offers multiple domain-specific translation models, plus three levels of self-service customization for text with very specific language. (Note: The Watson Language Translation service has been rebranded as the Language Translator service. The Language Translator service provides the same capabilities as the Language Translation service, but with simpler pricing.)
What can be done with Watson Language Translator? As an example, an English-speaking help desk representative can assist a Spanish-speaking customer through chat (using the conversational translation model). As another example, a West African news website can curate English news from across the globe and present it in French to its constituents (using the news translation model). Similarly, a patent attorney in the US can effectively discover prior art (to invalidate a patent claims litigation from a competitor) based on invention disclosures made in Korean with the Korean Patent Office. Another example would be that a bank can translate all of their product descriptions from English to Arabic using a custom model tailored to that bank's product names and terminology. All of these examples (and more) can benefit from the real-time, domain-specific translation abilities of the Language Translator service.
Plain text in one of the supported input languages and domains.
Plain text in the target language selected.
More detailed documentation for Language Translator
Personality Insights extracts and analyzes a spectrum of personality attributes to help discover actionable insights about people and entities, and in turn guides end users to highly personalized interactions. The service outputs personality characteristics that are divided into three dimensions: the Big 5, Values, and Needs. We recommend using Personality Insights with at least 1200 words of input text.
The Personality Insights service lends itself to an almost limitless number of potential applications. Businesses can use the detailed personality portraits of individual customers for finer-grained customer segmentation and better-quality lead generation. This data enables them to design marketing, provide product recommendations, and deliver customer care that is more personal and relevant. Personality Insights can also be used to help recruiters or university admissions match candidates to companies or universities. For more detailed information, see the "Use Cases" section of the Personality Insights documentation.
JSON, or Text or HTML (such as social media, emails, blogs, or other communication) written by one individual
A tree of cognitive and social characteristics in JSON or CSV format
The Personality Insights service offers a set of core analytics for discovering actionable insights about people and entities. The following sections provide basic information about using the service.
The Personality Insights service is based on the psychology of language in combination with data analytics algorithms. The service analyzes the content that you send and returns a personality profile for the author of the input. The service infers personality characteristics based on three models:
- Big Five personality characteristics represent the most widely used model for generally describing how a person engages with the world. The model includes five primary dimensions:
- Agreeableness is a person's tendency to be compassionate and cooperative toward others.
- Conscientiousness is a person's tendency to act in an organized or thoughtful way.
- Extraversion is a person's tendency to seek stimulation in the company of others.
- Emotional Range, also referred to as Neuroticism or Natural Reactions, is the extent to which a person's emotions are sensitive to the person's environment.
- Openness is the extent to which a person is open to experiencing a variety of activities.
- Each of these top-level dimensions has six facets that further characterize an individual according to the dimension.
- Needs describe which aspects of a product will resonate with a person. The model includes twelve characteristic needs: Excitement, Harmony, Curiosity, Ideal, Closeness, Self-expression, Liberty, Love, Practicality, Stability, Challenge, and Structure.
- Values describe motivating factors that influence a person's decision making. The model includes five values:Self-transcendence / Helping others, Conservation / Tradition, Hedonism / Taking pleasure in life, Self-enhancement / Achieving success, and Open to change / Excitement.
More detailed documentation for Personality Insights
This service helps users find the most relevant information for their query by using a combination of search and machine learning algorithms to detect "signals" in the data. Built on top of Apache Solr, developers load their data into the service, train a machine learning model based on known relevant results, then leverage this model to provide improved results to their end users based on their question or query.
The Retrieve and Rank Service can be applied to a number of information retrieval scenarios. For example, an experienced technician who is going onsite and requires help troubleshooting a problem, or a contact center agent who needs assistance in dealing with an incoming customer issue, or a project manager finding domain experts from a professional services organization to build out a project team.
Your documents Queries (questions) associated with your documents Service Runtime: User questions and queries
Indexed documents for retrieval Machine learning model (Rank) Service Runtime: A list of relevant documents and metadata
The IBM Watson™ Retrieve and Rank service combines two information retrieval components in a single service: the power of Apache Solr and a sophisticated machine learning capability. This combination provides users with more relevant results by automatically reranking them by using these machine learning algorithms.
The following image shows the process of creating and using the Retrieve and Rank service:
For a step-by-step overview of using the Retrieve and Rank service, see the Tutorial page.
The purpose of the Retrieve and Rank service is to help you find documents that are more relevant than those that you might get with standard information retrieval techniques.
- Retrieve: Retrieve is based on Apache Solr. It supports nearly all of the default Solr APIs and improves error handling and resiliency. You can start your solution by first using only the Retrieve features, and then add the ranking component.
- Rank: The rank component (ranker) creates a machine-learning model trained on your data. You call the ranker in your runtime queries to use this model to boost the relevancy of your results with queries that the model has not previously seen.
The service combines several proprietary machine learning techniques, which are known as learning-to-rank algorithms. During its training, the ranker chooses the best combination of algorithms from your training data.
The core users of the Retrieve and Rank service are customer-facing professionals, such as support staff, contact center agents, field technicians, and other professionals. These users must find relevant results quickly from large numbers of documents:
- Customer support: Find quick answers for customers from your growing set of answer documents
- Field technicians: Resolve technical issues onsite
- Professional services: Find the right people with the right skills for key engagements
The Retrieve and Rank service can improve information retrieval as compared to standard results.
- The ranker models take advantage of rich data in your documents to provide more relevant answers to queries.
- You benefit from new features developed both by the open source community and from advanced information retrieval techniques that are built by the Watson algorithm teams.
- Each Solr cluster and ranker is highly available in the Bluemix environment. The scalable IBM infrastructure removes the need for you to staff your own highly available data center.
As previously mentioned, the Retrieve part of the Retrieve and Rank service is based on Apache Solr. When you use Retrieve and Rank, you need to be knowledgeable about Solr as well as about the specifics of the Retrieve and Rank service. For example, when Solr passes an error code to the service, the service passes it to your application without modification so that standard Solr clients can correctly parse and act upon it. You therefore need to know about Solr error codes when writing error-handling routines in your Retrieve and Rank application.
More detailed documentation for Retrieve and Rank
Watson Speech to Text can be used anywhere there is a need to bridge the gap between the spoken word and its written form. This easy-to-use service uses machine intelligence to combine information about grammar and language structure with knowledge of the composition of an audio signal to generate an accurate transcription. It uses IBM's speech recognition capabilities to convert speech in multiple languages into text. The transcription of incoming audio is continuously sent back to the client with minimal delay, and it is corrected as more speech is heard. Additionally, the service now includes the ability to detect one or more keywords in the audio stream. The service is accessed via a WebSocket connection or REST API.
The Speech to Text service can be used anywhere voice-interactivity is needed. The service is great for mobile experiences, transcribing media files, call center transcriptions, voice control of embedded systems, or converting sound to text to then make data searchable. Supported languages include US English, UK English, Japanese, Spanish, Brazilian Portuguese, Modern Standard Arabic, and Mandarin. The Speech to Text service now provides the ability to detect the presence of specific keywords or key phrases in the input stream.
Streamed audio with Intelligible Speech Recorded audio with Intelligible Speech
Text transcriptions of the audio with recognized words
By default, the service stops transcription at the first end-of-speech (EOS) incident, which is denoted by a half-second of non-speech (typically silence) or when the stream terminates. Set the continuous parameter to true to instruct the service to transcribe the entire audio stream until the stream terminates. In this case, the results can include multiple transcript elements to indicate phrases separated by pauses. You can concatenate the transcript elements to assemble the complete transcription of the audio stream.
More detailed documentation for Speech to Text
When systems communicate with each other, this is considered Internet of Things
- Explain the components of systems communicating with one another
- Use case of Twitter and sentiment analysis
- Use case of the Weather APIs and mission critical decision that are impacted by weather
Some IBM Watson services work out-of-the-box as they were pre-trained in a specific domain (domain-adapted). Other Watson services require training. For pre-trained services, it’s critical to know the adapted domains as they indicate the areas in which the service will perform best.
Pre-trained Watson services:
- Watson Text-to-Speech
- Watson Speech-to-text
- Language Translation (conversational, news, and patent domains)
- Alchemy Language (open-domain)
- Watson Visual Insights
- Tone Analyzer
- Personality Insights (social media domain)
Services requiring training:
- Natural Language Classifier
- Rank part of Retrieve and Rank
- Visual recognition (custom models)
Some examples are:
- Sentiment analysis
- Spam email detection
- Customer message routing
- Academic paper classification into technical fields of interest
- Forum post classification to determine correct posting category
- Patient reports for escalation and routing based on symptoms
- News article analysis
- Investment opportunity ranking
- Web page topic analysis
-
Identify the programming languages with SDKs available
-
Describe the advantage and disadvantages of using an SDK
-
Find the Watson SDKs and other resources on the WDC GitHub
- Identify the Language services on WDC
- AlchemyLanguage
- Conversation
- Document Conversion
- Language Translator
- Natural Language Classifier
- Natural Language Understanding
- Personality Insights
- Retrieve and Rank
- Tone Analyzer
- Identify the Vision services on WDC
- Visual Recognition
- Identify the Speech services on WDC
- Speech to Text
- Text to Speech
- Identify the Data Insights services on WDC
- AlchemyData News
- Discovery
- Tradeoff Analytics
The service enables developers without a background in machine learning or statistical algorithms to interpret the intent behind text. Configure:
- Gather sample text from real end users (fake initially if you have to…but not much)
- Determine the users intents that capture the actions/needs expressed in the text
- Classify your user text into these user intents
- Separate your user text into train/test datasets
- Train an NLC classifier on your training dataset
- Pass the user input to an NLC classifier
- Determine the accuracy, precision, and recall of the NLC classifier using your test dataset
- Improve the confidence level iteratively through back propagation or other means.
- Describe the process for training a classifier
- Explain how to identify images with a specified classifier
- Describe the capabilities of Face Detection/Recognition
- Describe the capabilities of Natural Scene OCR
- Describe the intended use of the Personality Insights service
- Describe the inputs and outputs of the Personality Insights service
- Describe the personality models of the Personality Insights service
- Describe the common use cases of the Tone Analyzer service
- Describe the basic flow of the Tone Analyzer service
- Explain the three categories of tone scores and their sub-tones: emotional tone, social tone, and language tone.
- Explain how Tone Analyzer service is different from the Alchemy Language - Sentiment Analysis and Emotion Insights service
- Identify the capabilities of Alchemy Language
- Describe the text extraction features of Alchemy Language
- Distinguish between keywords, entities, and concepts
- Distinguish between document-level and targeted sentiment
- Explain the difference between the taxonomy call and the knowledge graph
- Explain disambiguation as it relates to entities
- Explain how Emotion Analysis service works
- What emotions does Emotion Analysis detect?
- Describe the main use cases for applying the Emotion Insights service
- Describe the main types of positive/negative sentiment extracted from digital text
- Describe the API types provided by the Sentiment Analysis service
- Describe the differences between sentiment and emotion analyses
- Explain the function of the Retrieve and Rank service
- Configure the Retrieve and Rank service
- Create Solr cluster
- Create and upload Solr configuration
- Create Solr collection
- Upload and index documents
- Create / update ground truth
- Create and train Ranker
- Evaluate result / update ground truth
- Alchemy Language
- Create an instance of the Alchemy Language service in Bluemix
- Select the correct API to call for text extraction, sentiment analysis, or any of the Alchemy Language services.
- Pass your content to your Alchemy services’ endpoint through a RESTful API call
- Natural Language Classifier
- Gather sample text from real end users (fake initially if you have to…but not much)
- Determine the users intents that capture the actions/needs expressed in the text
- Classify your user text into these user intents
- Separate your user text into train/test datasets
- Create an instance of the Natural Language Classifier service in Bluemix
- Train an NLC classifier on your training dataset
- Pass your content to your NLC services’ endpoint through a RESTful API call
- Determine the accuracy, precision, and recall of the NLC classifier using your test dataset
- Personality Insights
- Create an instance of the Personality Insights service in Bluemix
- Gather text from users in their own voice
- Ensure you meet the minimum limits for word count (currently 5,000 words) to limit sampling error.
- Pass your content to your Personality Insight services’ endpoint through a RESTful API call
- Document the primary conversation flow for your users.
- Determine ways users could diverge from this flow and how to redirect them back.
- Determine the primary user intents plus paraphrases at various nodes in your conversation
- Define profile variables
- Create instances of Dialog and NLC services on Bluemix
- Upload these intents plus paraphrases into the NLC Service
- Build out conversation flow with Dialog Service
- Present your beta conversation agent to end users to capture real end user text
- Identify areas where users strayed outside the domain of your conversation agent
- Identify areas where your conversation agent misunderstood the user
- Update your conversation agent with new intents plus real end user text
- Natural Language Classifier
- Using classifiers from NLC to drive dialog selections in Dialog
- Personality Insights
- Use the service output from two different textual inputs and compare the personalities based on the results
- Speech to text
- Use the transcribed output from speed to text as input to language translation
- Language translation
- Use the translated text from language translation as input to text to speech
- AlchemyNews
- Use the top article returned by the search from AlchemyNews as input to AlchemyLanuage-Sentiment Analysis and Tone Analyzer
- Use the top article returned by the search from AlchemyNews as input to relationship extraction to tell who is trending in the article
Cognitive systems tend to gain more value as additional services are composed. With so many services, it’s sometimes hard to tell which services work best together.
- Conversation
- Goal: Engage user in back-and-forth dialog while detecting and acting on user intent. The specifics of the actions taken are guided by the entities discovered.
- Services: Watson Dialog + Natural Language Classifier + entity extraction (Alchemy Language)
- Q&A
- Goal: Answer a wide range of customer questions while offering precise answers for frequently asked facts and highly relevant passages for less frequent questions that may not have a single best answer
- Services: Watson Dialog + Natural Language Classifier + Retrieve and Rank
- Agent Assist
- Goal: Provide natural language help systems so call agents can rapidly retrieve answers to customer questions
- Services: Watson Dialog + Natural Language Classifier + entity extraction (Alchemy Language)
- Automated Customer Support Routing
- Goal: Detect the topic of a ticket and route to the appropriate department to handle it. E.g. room service, maintenance, housekeeping in the case of hotel guest request routing.
- Services: Keyword extraction and sentiment analysis (Alchemy Language)
- Data Insights
- Goal: Monitor all posts with specific keywords (e.g. for a company’s followers, sponsors, or critiques) to detect what’s being discussed and the sentiment/tone associated to it.
- Services used: Keyword extraction, entity extraction, and sentiment/tone analysis (Alchemy Language)
- Natural Language Classifier
- Create a classifier
- Return label information
- List classifiers
- Dialog
- Upload a dialog
- Retrieve content
- Update content for specific nodes
- Start new conversation
- Set profile variables
- Language Translation
- Upload glossary
- Return translation status
- Translate input
- Alchemy Vision
- Recognize face
- Extract link
- Tag image
- Detect text
- Configure application’s manifest to request the correct memory and app instance allocations
- Configure application with service credentials extracted from VCAP services
- Create instances of your required services in IBM Bluemix
- Install Cloud Foundry command line tools
- Log-in to IBM Bluemix from the command line
- Push the application to IBM Bluemix using the Cloud Foundry command line tools
- Use the Bluemix web interface
- Get service credentials in Bluemix
- Get service credentials programmatically
- Manage organizations, spaces, and assigned users in IBM Bluemix
- Using tokens with Watson services
- Obtain a token
- Use a token
- Get a token programmatically
- Monitor applications running on Cloud Foundry
- Monitor applications by using IBM Monitoring and Analytics for Bluemix
- Configure performance monitoring
- Monitor performance of applications
- Log for apps running on Cloud Foundry
- View logs from the Bluemix dashboard
- View logs from the command line interface
- Filter logs
- Configure external logs hosts
- View logs from external logs hosts