This message is used to verify that this feed (feedId:69641690532004864) belongs to me (userId:68917208290305024). Join me in enjoying the next generation information browser https://follow.is. 平台链接:点击链接
项目链接: 点击链接跳转
在微表情识别系统中,关键的技术步骤包括图像采集与处理、人脸检测、微表情特征提取,以及深度学习的应用。本章将深入介绍这些关键技术的步骤和挑战。
- 实时视频流的获取微表情的捕捉通常依赖于实时视频流。通过摄像头采集的视频流提供了连续的面部信息,为后续微表情分析奠定基础。
- 图像预处理步骤.在微表情识别之前,对图像进行预处理是至关重要的。这包括图像的灰度化、去噪、亮度调整等步骤,以确保后续分析的准确性。
人脸检测是微表情识别的关键步骤之一。常用的算法包括Haar级联分类器、深度学习中的卷积神经网络(CNN)等。这些算法能够在图像中准确地定位和标识人脸的位置。
Haar级联检测器介绍:Haar是一种特征描述,随着时代的进步Haar也从Haar Basic的三种简单特征扩展到了Haar-Like以及到现在的Haar Extended。但是万变不离其宗,我们笼统得把他们分成三类:中心特征,线性特征, 边缘特征。特征模板内有白色和黑色两种矩形,并定义该模板的特征值为白色矩形像素和减去黑色矩形像素和。Haar特征值反映了图像的灰度变化情况。
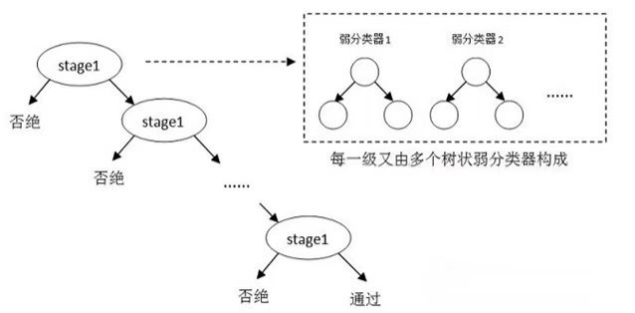
- Haar级联检测器是一种基于机器学习的对象检测方法,利用Haar特征进行目标检测。
- 它通过训练得到一个级联的弱分类器集合,级联中的每个弱分类器都是一个Haar特征分类器。
- Haar特征是一种简单的图像特征,通过在图像中滑动特定的窗口并比较不同区域的像素和来识别目标。
- Haar级联检测器在目标检测中具有高速和高效的优势,常用于人脸、眼睛等对象的检测。
这里使用的是harr级联检测器检测人脸:
- 初始化Haar级联检测器路径:
detectorPaths字典包含了不同检测器的名称和对应的Haar级联检测器文件路径。- 加载Haar级联检测器:
- 使用
cv2.CascadeClassifier()函数加载Haar级联检测器,将加载的检测器存储在detectors字典中。 - 图像处理:
- 从磁盘读取输入图像,并使用
imutils.resize函数将图像的宽度调整为500像素。 - 将图像转换为灰度图,以便进行人脸检测。
- 执行面部检测:
- 使用
detectors["face"].detectMultiScale方法执行人脸检测,得到面部的边界框坐标 (faceRects)。 - 参数包括:
scaleFactor:在每个图像尺度下缩小图像的比例,以便进行多尺度检测。minNeighbors:指定每个候选矩形应该保留多少个相邻矩形,这可以减少噪声。minSize:对象的最小尺寸。flags:控制级联器的行为。
- 眼睛和嘴巴检测:
- 对于每个检测到的面部,提取面部ROI(Region of Interest)。
- 使用
detectors["eyes"].detectMultiScale在面部ROI中应用左右眼级联检测器,得到眼睛的边界框坐标 (eyeRects)。 - 使用
detectors["smile"].detectMultiScale在面部ROI中应用嘴巴检测器,得到嘴巴的边界框坐标 (smileRects)。

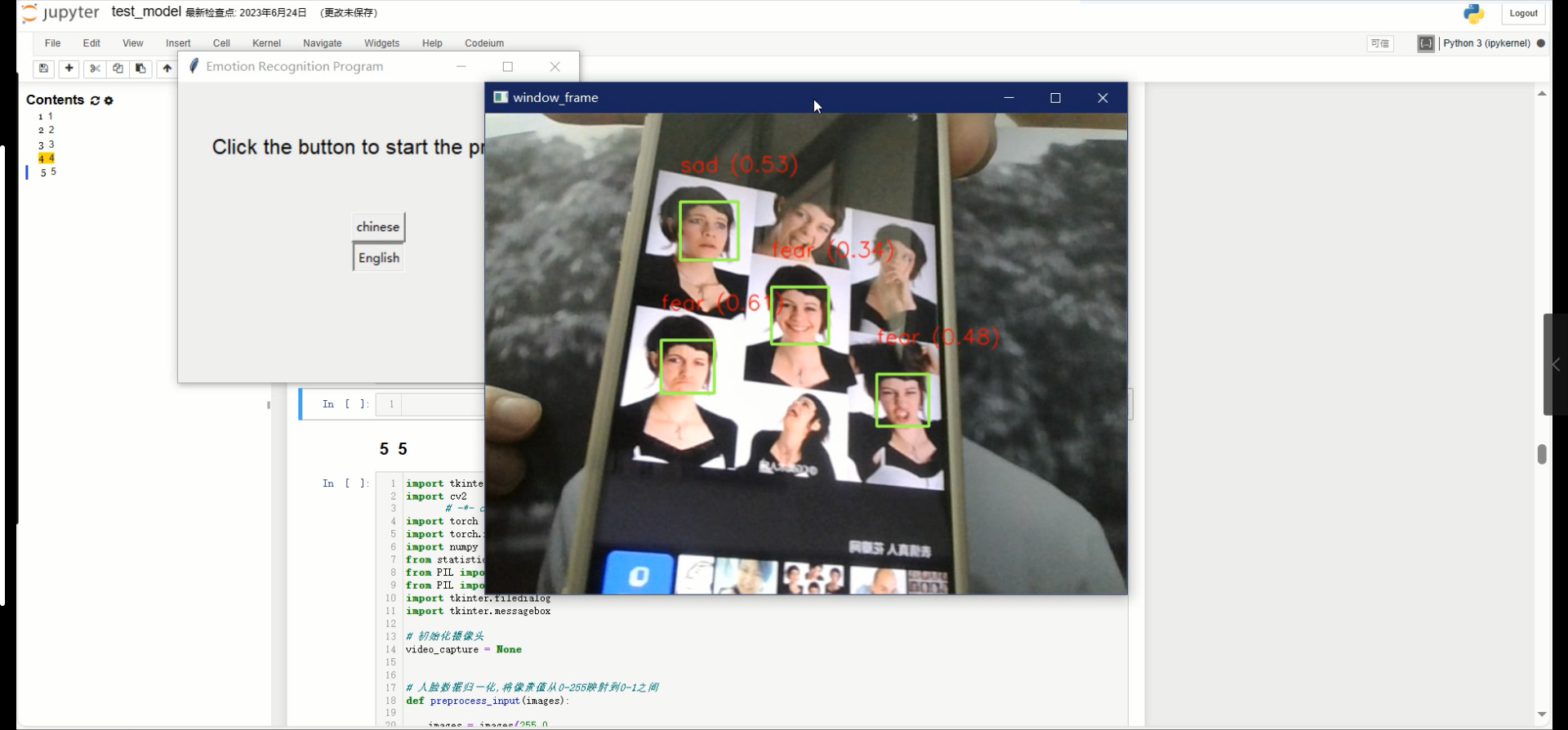
微表情的特征通常通过关键点检测来实现。关键点通常是人脸上一些具有代表性的点,如眼睛、嘴巴等。通过追踪这些关键点的运动变化,可以提取出微表情的特征。
卷积神经网络在微表情识别中被广泛应用。通过卷积层、池化层等结构,CNN能够自动学习图像特征,提高微表情的识别精度。
模型结构总览——该微表情识别模型采用卷积神经网络(CNN)的结构,包括三个卷积层和一个全连接层。
卷积层1 (
conv1)——卷积层1接受灰度图像作为输入,通过3x3的卷积核进行特征提取,输出64个通道的特征图。批量归一化和随机修正线性单元(RReLU)有助于提高训练稳定性。最大值池化进一步减小特征图的空间尺寸,提取显著特征。 卷积层2 (conv2)——卷积层2接受卷积层1的输出,进行类似的操作,将64通道的输入转化为128通道的输出。这一层继续强化特征,并通过最大值池化减小空间维度,使网络对位置的变化更加鲁棒。 卷积层3 (conv3)——卷积层3进一步加深网络,将128通道的输入转化为256通道的输出。卷积操作提取高级特征,而最大值池化降低了空间维度。这一层有助于模型学习更加抽象和复杂的特征。 全连接层 (fc)——全连接层包含三个子层,通过线性变换和激活函数处理扁平化后的特征。Dropout操作有助于防止过拟合。最终的全连接层输出包含7个神经元,对应7个不同的情感类别。这一层对特征进行整合,生成最终的表情分类结果。 参数初始化——卷积层的权重参数采用正态分布初始化,有助于更好地训练模型。

1 Huai-Qian Khor, John See, Raphael C.W.Phan, Weiyao Lin.Enriched Long-term Recurrent Convolutional Network for Facial Micro-Expression Recognition.Published in Micro-Expression Grand Challenge 2018, Workshop of 13th IEEE Facial & Gesture 2018.
2 牛瑞华, 杨俊, 邢斓馨, 吴仁彪. 基于卷积注意力模块和双通道网络的微表情识别算法J. 计算机应用, 2021, 41(9): 2552-2559.