機械学習関連の論文 Survey 用レポジトリです。
論文まとめ記事は、Issues に記載しています。進捗は、Projects ページ で管理しています。
GCN
Transformer
VAE
GANs
- [GAN] Generative Adversarial Networks
- [DCGAN] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
- [cGAN] Conditional Generative Adversarial Nets
- [WGAN] Wasserstein GAN
- [WGAN-gp] improved Training of Wasserstein GANs
- SAGAN [Self-Attention Generative Adversarial Networks]
- InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
- [RSGAN,RGAN,RaGAN] The relativistic discriminator: a key element missing from standard GAN
- GAN-Tree: An Incrementally Learned Hierarchical Generative Framework for Multi-Modal Data Distributions
- A U-Net Based Discriminator for Generative Adversarial Networks
Flow-based generative model
Autoregressive Models
meta-learning, few-shot learning
Neural Processes
Image Classification
- xxx
Semantic Segmentation
- U-Net: Convolutional Networks for Biomedical Image Segmentation
- [PSPNet] Pyramid Scene Parsing Network
- Pyramid Attention Network for Semantic Segmentation
- [DeepLab v3+] Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
- Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks
- Hypercolumns for Object Segmentation and Fine-grained Localization
- Tversky loss function for image segmentation using 3D fully convolutional deep networks
- Boundary loss for highly unbalanced segmentation
- Human Parsing
- [JPPNet] Look into Person: Joint Body Parsing & Pose Estimation Network and A New Benchmark
- [CE2P] Devil in the Details: Towards Accurate Single and Multiple Human Parsing
- Graphonomy: Universal Human Parsing via Graph Transfer Learning
- Hierarchical Human Parsing with Typed Part-Relation Reasoning
- [CorrPM] Correlating Edge, Pose with Parsing
Object Detection
Instance Segmentation
- Mask R-CNN
- Human Parsing
Pose Estimation
Image Registration / geometric matching
image-to-image
- [pix2pix] Image-to-Image Translation with Conditional Adversarial Networks
- [pix2pix-HD] High-Resolution_Image_Synthesis_and_Semantic_Manipulation_with_Conditional_GANs
- [CycleGAN] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
- [StarGAN] StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
- [SPADE] Semantic Image Synthesis with Spatially-Adaptive Normalization
- [Neural Collage] Spatially Controllable Image Synthesis with Internal Representation Collaging
- Recapture as You Want
- Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation
- [Impersonator++] Liquid Warping GAN with Attention: A Unified Framework for Human Image Synthesis
- Focal Frequency Loss for Generative Models
- few-shot learning
noize-to-image
Inpainting
Person Image Generation
recommendation
text-to-image
Optical Flow
3D Reconstruction
- param-to-3D / parametric 3D models
- image-to-3D / image-based 3D Reconstruction
- none-parametric 3D models
- Mesh R-CNN
- Occupancy Networks: Learning 3D Reconstruction in Function Space
- PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
- PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
- NormalGAN: Learning Detailed 3D Human from a Single RGB-D Image
- using templete mesh
- parametric 3D models
- [HMR] End-to-end Recovery of Human Shape and Pose
- Multi-Garment Net: Learning to Dress 3D People from Images
- Deep Fashion3D: A Dataset and Benchmark for 3D Garment Reconstruction from Single Images
- BCNet: Learning Body and Cloth Shape from A Single Image
- ExPose: Monocular Expressive Body Regression through Body-Driven Attention
- I2L-MeshNet: Image-to-Lixel Prediction Network for Accurate 3D Human Pose and Mesh Estimation from a Single RGB Image
- none-parametric 3D models
- video-to-3D
- texture mapping
- camera localization
Others
- xxx
xxx
- xxx
-
論文調査
- その論文の発展版を探すには、Google Scholer でその論文の被引用論文を探すのが手っ取り早い。
- 基本的には、その論文の被引用数が多いものが注目の論文。但し最新の論文は当然被引用数は少なくなる。
- 著者の所属組織も優れた論文であるか判断材料になり得る。例えば、GAFA や NVIDIA, Adobe などの論文は、優れた論文である可能性が高い
- 基本的には、最新の論文ほど優れた実験結果を出しているので、Google Scholer で出来るだけ公開日時の最新のものを探す。
- 論文の公式実装がないものは、自前実装の再現コストが高いので、公式実装があるものを優先的に探す。
- 論文の公式実装の有無は、papers with code で確認できる。
- github 上に論文公式実装がある場合は、スター数も優れた論文であるかの判断材料になり得る。
- 探している分野の論文が1つ見つかれば、その論文を papers with code で検索する。その論文の "Tasks" が割り振られている場合は、その Tasks の名前からその分野の最新論文を調べることが出来る。
-
論文の読み方
- 基本的に、「Abstract」→「Introduction」→「Conclusion」→「何をしたかの詳細」→「Experiments」→「Related Work」項目の順に読むのが効率的。Related Work は最悪飛ばしても良い。
- Abstract や Introduction 内の "In this paper ...", "In this work ..." という文面や、Introduction の最後にある "the contributions of this paper ... as follows." という文面には注目。
- その論文の未解決課題や問題点は、論文中の Future work や Conculution に述べられていることが多い。或いは、その論文を引用している論文の Related Work に述べられていることが多い。
layout: post
title: "論文タイトル"
date: YYYY-MM-DD
categories: CV NLP Others
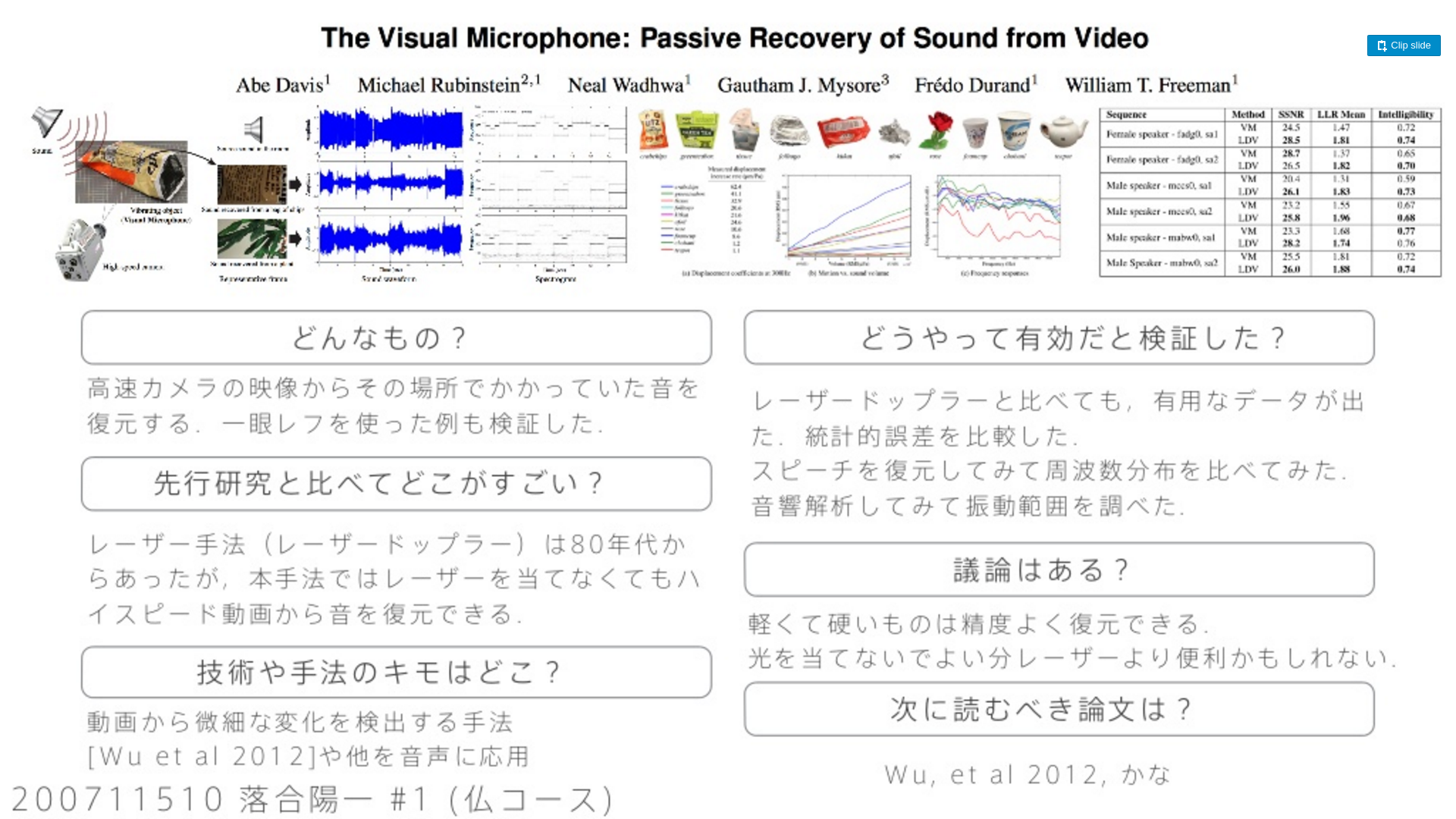
## 1. どんなもの?
## 2. 先行研究と比べてどこがすごいの?
## 3. 技術や手法の"キモ"はどこにある?
/(title)/figure1.png)
## 4. どうやって有効だと検証した?
## 5. 議論はあるか?
## 6. 次に読むべき論文はあるか?
### 論文情報・リンク
* [著者,"タイトル," ジャーナル名,voluem,no.,ページ,年](論文リンク)
- DeepL
- papers with code
- 論文実装の有無を確認できる。
- Hyper Collocation
- arXiv Vanity