{kind=link}
![]()
![]()
Clusterman (the Cluster Manager) is an autoscaling engine for Mesos and Kubernetes clusters. It looks at metrics and can launch or terminate compute to meet the needs of your workloads, similarly to the official Kubernetes Cluster Autoscaler It provides the following set of features:
- Customizable metrics: All metrics for Clusterman are stored in an external datastore, and are automatically loaded into the signals that need them
- Pluggable autoscaling signals: Your team knows how the application you're running should scale in response to metrics, so your team should own the signal that tells Clusterman what to do
- Full-featured simulation environment: Want to know how the autoscaler is going to respond to production traffic before you deploy changes? The Clusterman simulation environment lets you do this. You can also simulate future traffic so that you can predict usage or cost increase before they happen.
For more information, see the Clusterman documentation
You can try out Clusterman in a local development environment against a Dockerized Mesos cluster by running the following commands:
make example
clusterman status --cluster local-dev -v
All of the Clusterman CLI commands should work in the above environment. You can see examples of the Clusterman services by running
make itest-external
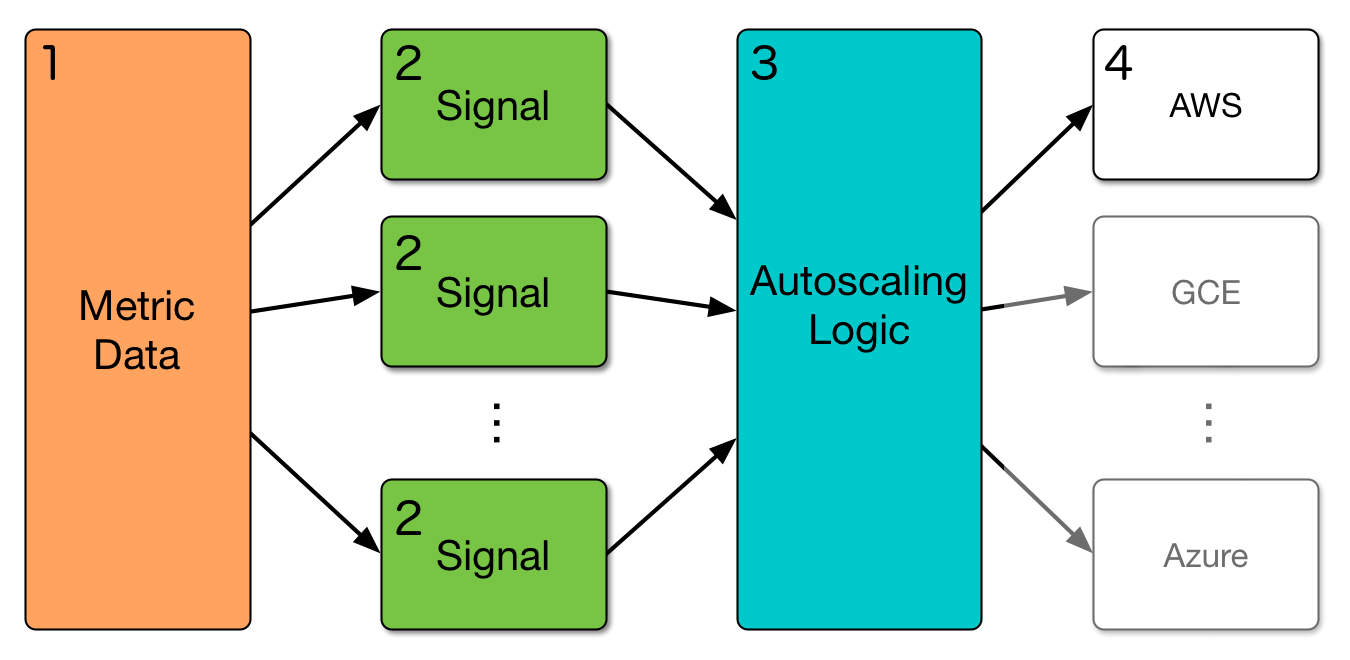
Clusterman is made up of the following components:
- Metrics Data Store: All relevant data used by scaling signals is written to a single data store for a single source of truth about historical cluster state. At Yelp, we use AWS DynamoDB for this datastore. Metrics are written to the datastore via a separate metrics library.
- Pluggable Signals: Metrics (from the data store) are consumed by signals (small bits of code that are used to produce resource requests. Signals run in separate processes configured by supervisord, and use Unix sockets to communicate.
- Core Autoscaler: The autoscaler logic consumes resource requests from the signals and combines them to determine how many resources to request from or release back to the cloud provider.
- Resource Groups and Pools: Each autoscaler instance manages exactly one "pool", that is, a logical grouping of machines in a cluster. Pools consist of "resource groups", such as a Spot Fleet Request (SFR) or AutoScaling Group (ASG) from AWS EC2.
- Configuration: Clusterman stores global configuration values in a file called
clusterman.yaml, and per-pool configuration inclusterman-clusters/<cluster-name>/<pool-name>.(mesos|kubernetes). These config files tell the Clusterman services when and how to run, and they serve as the glue to hook up an autoscaler with its signals. Configure the path toclusterman.yamlwith the--env-config-pathflag, and the path toclusterman-clusterswith--cluster-config-directory. - An Autoscaling Simulation Environment: Clusterman comes with a complete simulation environment for running tests with your signals on historical data before they are deployed. This environment can produce information about the cost of your cluster, as well as whether it is over- or under-provisioned.
Clusterman has two main ways of interacting with the clusters it manages. The
Clusterman CLI provides a set of command-line tools for viewing and managing
the state of the cluster; type clusterman --help to see a list of possible
subcommands. See the Clusterman documentation for more details.
The Clusterman service runs as a set of three long-running processes; the first process collects data about spot instance pricing from AWS (not required if you aren't using AWS, spot instances, or the Clusterman simulator); the second process queries each of the pools in a cluster to collect metadata and system metrics about the pool; and the third process is responsible for actually autoscaling each of the pools.
At Yelp, we use PaaSTA, our platform-as-a-service, to manage Clusterman. If you use PaaSTA, setting up Clusterman should be relatively straightforward. Otherwise you will need to provide additional tooling to deploy the Clusterman code or Docker image to your environment.
If you'd like to use Clusterman in your environment, you will need the following components set up:
- A metrics datastore with the appropriate tables. See
examples/terraform/clusterman.tffor a Terraform representation of the schema in DynamoDB. - A
clusterman_metricslibrary that can communicate with your chosen metrics datastore. There is a reference copy of the metrics library inexamples/clusterman_metricsthat is capable of communicating with AWS DynamoDB. - Code to run the autoscaler service. At Yelp, we use an internal
batch library called
yelp_batchfor this task; however, the same goal can be achieved by simply running the code in a never-terminating while loop. See the sample code inexamples/batchfor a place to start. - Configuration files. Clusterman uses one "master" configuration file as well
as a configuration file per pool that it autoscales. You can see examples of
these config files in
acceptance/srv-configs, and the config file schema inexamples/schemas.
To build a Debian package for the Clusterman CLI, run make package. To build
an example Docker image which can run the Clusterman batch code, run make cook-image-external
Clusterman uses EC2 tags in order to find the resource groups that it manages. To configure a resource group so that Clusterman can find it, you need to add a tag like the following to your ASG or SFR:
tag-name: "{\"paasta_cluster\": \"cluster-name\", \"pool\": \"pool-name\"}"
You can specify the value of tag-name in your configuration file for the pool:
resource_groups:
- (sfr|asg):
tag: tag-name
Clusterman is designed to support a wide range of cluster autoscaling needs at Yelp. We run many different types of workloads (long-running services, batch jobs, machine learning tasks, databases, etc.) on top of Kubernetes and Mesos, and each of these workloads has a different set of scaling requirements. Clusterman is designed to be a unified system that can accomodate each of these workloads. To that end, Clusterman's design goals are:
- A modular design that separates cloud API calls from signal evaluation and the core autoscaling loop
- Unified autoscaling logic for a multi-tenant cluster
- Client-owned scaling signals for requesting resources
- A command-line interface for managing and interacting with clusters
- A simulation environment for performing cost and behaviour analysis
Clusterman is licensed under the Apache License, Version 2.0: http://www.apache.org/licenses/LICENSE-2.0
Everyone is encouraged to contribute to Clusterman by forking the Github repository and making a pull request or opening an issue. Please read our Code of Conduct.
- Make your changes, push a branch to GitHub, and create a pull request
- Once your PR is approved, merge your changes to master
A Jenkins pipeline polls GitHub and brings any changes into our internal version. Jenkins will then build and deploy Clusterman as normal.