Based on Sora like structure and DIT, EasyAnimateV1 uses transformer as a diffuser for video generation. In order to ensure good expansibility, EasyAnimateV1 builts easyanimate based on motion module.
EasyAnimateV1 is introduced additional motion module upon PixArt-alpha,so that can extend the DiT model from 2D image generation to 3D video generation. The pipeline is shwon as follows.
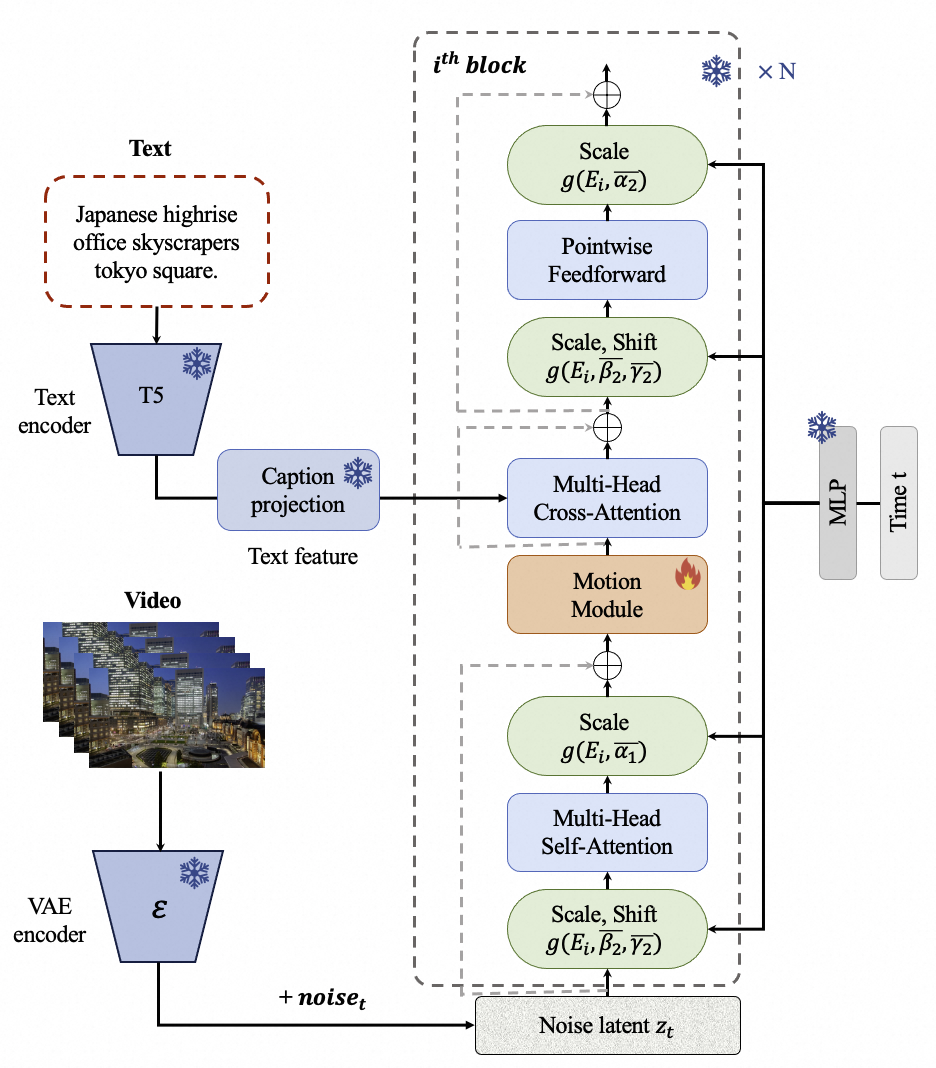
The motion module is used to capture the temporal information among frames. The structure is shown as follows.
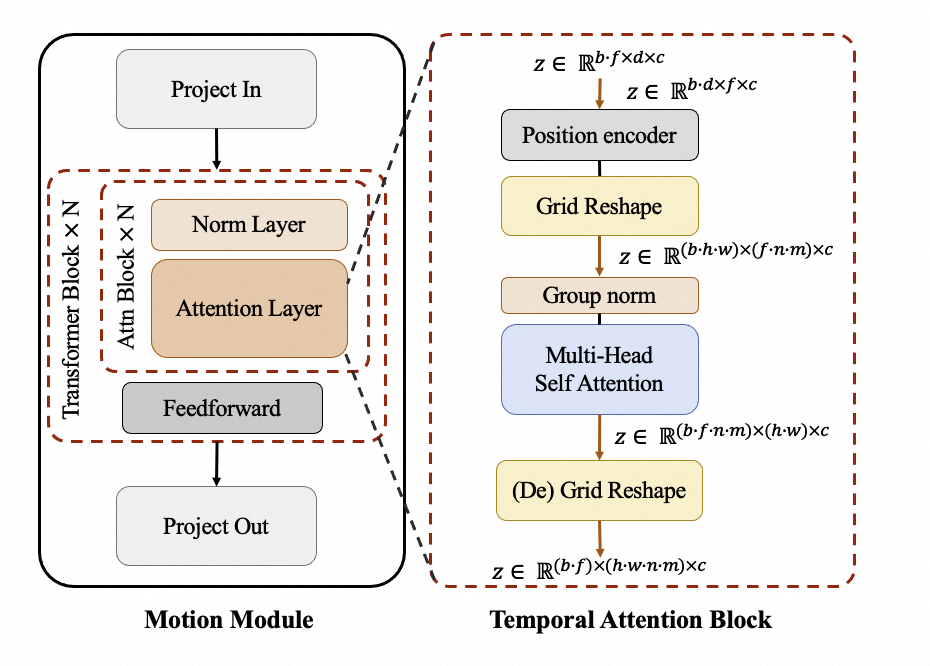
We introduce attention mechanisms in the temporal dimension to enable the model to learn temporal information for generating continuous video frames. At the same time, we utilize an additional Grid Reshape calculation to expand the number of input tokens for the attention mechanism, thus making greater use of the spatial information in images to achieve better generative results.
The Motion Module, as a separate module, can be applied to different DiT baseline models during inference. Furthermore, EasyAnimate not only supports the training of the motion-module but also supports the training of the DiT base model/LoRA model, making it convenient for users to complete training of a customized-style model according to their own needs and thereby generate videos of any style.