LsHNE
在阿里妈妈搜索广告场景下,广告召回的任务是,给定用户搜索请求(Request),召回模块通过理解用户意图,快速准确地从海量广告中找到高质量的小规模候选广告集,送给后续的广告排序模块进行排序。为了兼顾召回广告集的规模和质量,搜索广告召回一般包含搜索词改写(query-rewritten)和广告筛选(ad-selection)两个过程,并通过建立相应的倒排索引实现高效召回链路。
基于图的广告召回算法(如SimRank++)已经被证明在广告召回任务上有很好的效果。近些年来,各种Network Embedding算法有了很快地发展,如DeepWalk、Node2vec、LINE、DNGR等。Network Embedding的目标是将图中的节点Embedding成低维向量,并使向量在低维空间上的距离反应节点在图中的“亲密”程度。
将Network Embedding引入搜索广告召回任务,我们可以通过用户搜索意图节点向量和广告节点向量之间的距离进行广告召回,而不再依赖倒排索引。和传统的基于倒排索引的召回方法相比,基于向量进行召回有若干优点:
- 倒排索引的长度往往是固定的,导致改写很难在长尾流量上灵活地控制候选广告数目;而基于向量的召回方式,则可以被视为将全体广告作为候选,保证了在任意流量上召回足够多的广告。
- 考虑到响应时间限制,以往的召回方法在广告筛选时往往只能使用少量信息和简单的公式,很难准确地衡量广告质量;而在进行Network Embedding时,我们则可以使用复杂的模型将大量的信息“融入”节点向量,使得排序更加准确。
- 改写和广告筛选往往是单独优化的。而通过向量召回,可以一步完成召回。
然而,就我们所知,Network Embedding并没有被很好地应用于搜索广告召回场景。具体在淘宝搜索广告召回任务中,Network Embedding面临着若干新的挑战:
- 多种不同类型的节点。淘宝搜索广告场景中包含多种不同类型的实体,如query、item、ad等。因此,图中应包含多种类型的节点。
- 多种不同类型的边。在搜索广告场景,不同节点之间会存在多种不同类型的边,反应不同的关系。如query和item之间的点击关系,item是ad的前置点击关系等。
- 规模巨大。由于淘宝的巨大体量,我们的图规模会非常大,包含上亿节点和百亿边。
- 向量距离敏感。在以往的Network Embedding工作中,节点向量往往是作为后续任务的特征使用。而在搜索广告召回场景,我们直接使用向量的距离进行召回和排序。因此,节点向量需要能够有效地反映意图节点和ad节点之间的相关性。
- 节点属性。在淘宝平台,除了节点ID,还存在着丰富的节点属性信息,如item的价格、品牌等。这些节点属性信息是很好的泛化特征,能够帮助我们更好的理解任务场景。
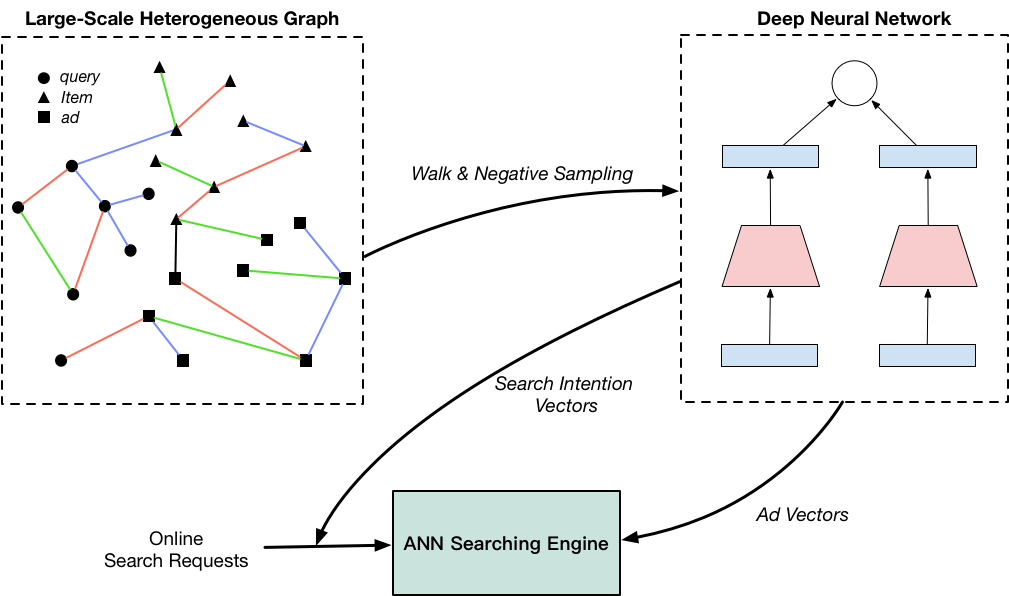 为了解决上述挑战,我们在淘宝上,提出了一种针对搜索广告召回的大规模异构网络Embedding方法,并通过Embedding得到的节点向量,进行广告召回。如上图所示,整个系统包括异构图构建、样本生成、模型训练、ANN检索等步骤。
为了解决上述挑战,我们在淘宝上,提出了一种针对搜索广告召回的大规模异构网络Embedding方法,并通过Embedding得到的节点向量,进行广告召回。如上图所示,整个系统包括异构图构建、样本生成、模型训练、ANN检索等步骤。
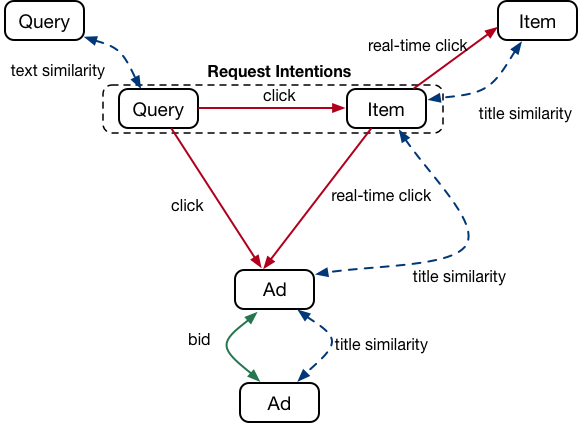
首先,我们为搜索场景构造一张大规模异构图。如上图所示,图中包含query、item、ad等多种类型节点,表示搜索场景中不同的实体:
- query节点和item节点:分别表示用户搜索query和淘宝上的item。我们使用这两种节点做为用户意图节点,刻画用户的个性化搜索意图。
- ad节点:为广告主投放的广告。
同时,图中还包含了多种类型边,表示实体之间的多种关系:
- 用户行为边:用户行为边表示用户的历史行为。例如,我们会在query和item之间建立“点击边”,并使用点击次数作为边权重。在搜索场景下,用户行为边刻画的是一种动态变化的关系。此外,热门的节点(如高频query)会有更多的展示和点击,进而拥有更稠密的边关系和更大的边权重。而冷门节点和新节点,则会相对稀疏。因此,用户行为边更加适合刻画热门节点。
- 内容相似边:为了更好地刻画冷门节点和新节点,我们建立内容相似边来刻画节点之间的内容相似度。例如,我们在item节点之间建立边,并使用其标题的文本相似度作为边权重。内容相似边反应了节点之间一种静态关系,更加稳定。
- 广告主行为边:此外,我们引入广告主行为边表示广告主的行为。例如,如果两个ad节点共享bidwords,我们则建立相应的边。广告主行为边反应了广告主对广告的认知,能够帮助我们更好地理解广告。
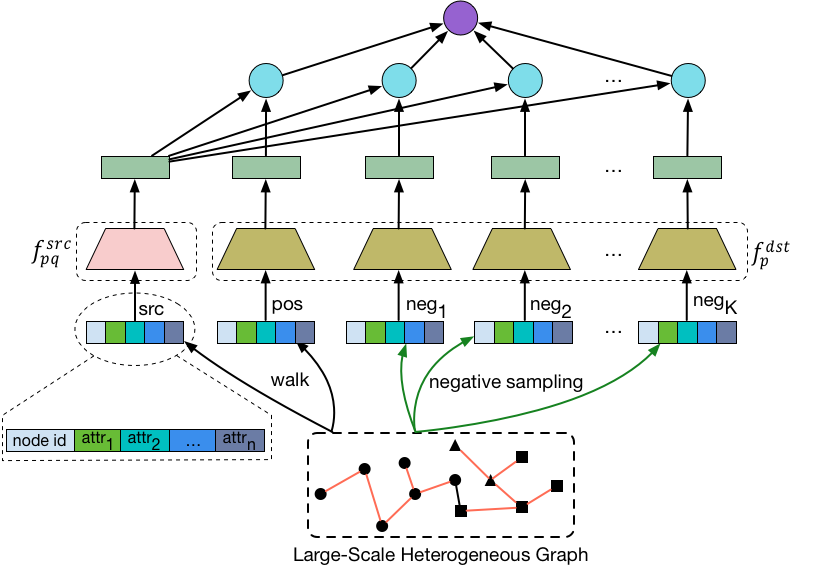
我们使用Node2vec Walk,在异构图上进行游走生成正例。Node2vec Walk是一种介于DFS和BFS之间的搜索方式,已经被证明在Network Embedding上有着很好的效果。
给定一个异构图,我们从每个节点
开始游走。对于每种边
,我们使用Node2vec Walk进行
次游走,每次游走得到长度为
的序列:
对于每个序列,我们通过滑窗得到正例对:
(src_node, pos_node, edge_type)
对于每个positive pair,我们使用负采样生成个负节点:
(src_node, pos_node, {neg_node}K, edge_type)
由于广告召回场景对向量的距离敏感,我们提出了负采样的两个原则: 一致性原则:负采样得到的负节点需要和正节点有着一致的分布。如果正负节点有着不一样的分布,模型就会“偷懒”地倾向记住正负节点是什么,而不是去学习节点之间的关系。因此,我们使用Alias Method进行带权重地负采样,保证正负节点分布一致。 相关性原则:负节点和源节点之间应该具有弱相关性。如果负节点和源节点完全无关,则会导致模型过于轻易地分别出正负样本;而在线上使用时,模型则不能很好地分别出最好的广告和次好的广告。因此,我们使用类目信息,来保证负样本和源节点之间有弱相关性。
我们将正负节点统一为目标节点:
(src_node, {dst_node}K+1, edge_type)
在淘宝搜索场景,每个节点都有丰富的属性(Side Information)来帮助我们描述节点。例如,item的价格、品牌等。和节点ID相比,这些属性具有很好的泛化能力,能够帮助提高模型的稳定性。
给定异构图,包含了
种节点和
种边。对于第
种类型的源节点
和第
种类型的边
,我们学习出一个DNN网络
:
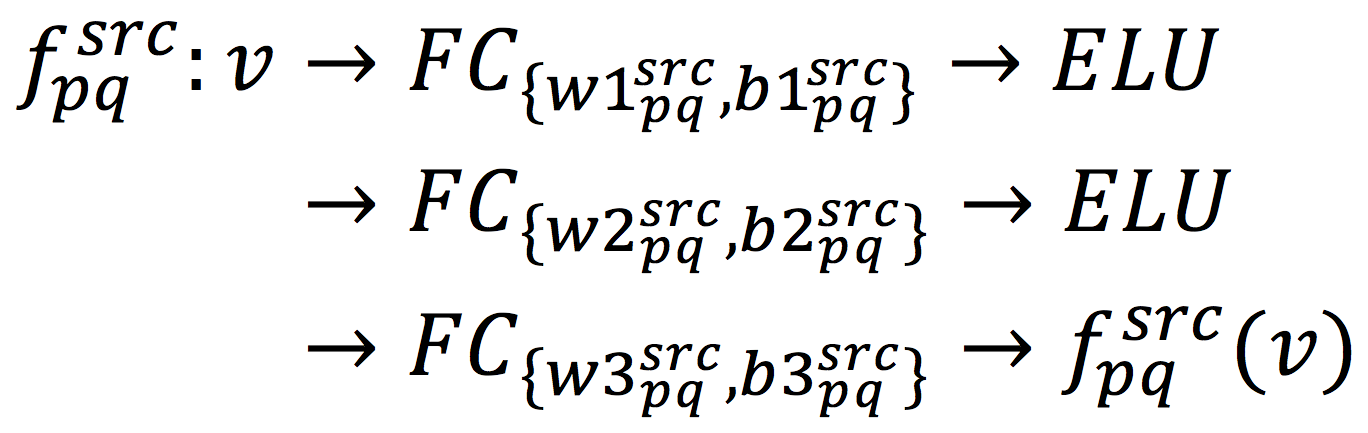
为了保证同一个节点通过不同类型的边Embedding得到的向量能够映射到同一低维空间,我们让所有目标节点(即正节点和负节点)在所有类型的边关系中,共享相同的DNN网络:
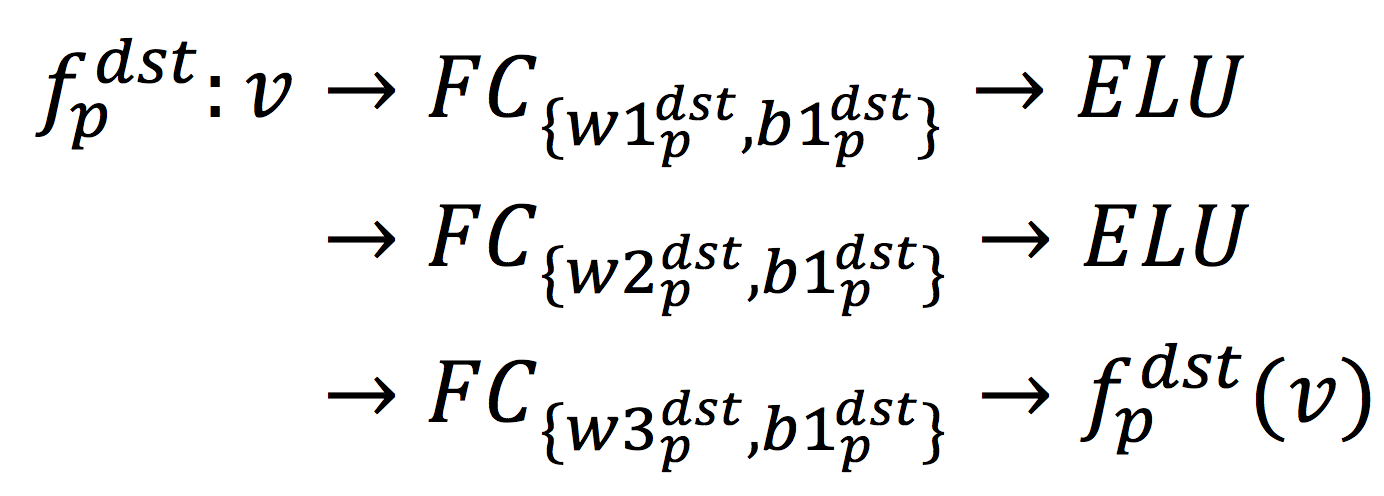
因此,我们同时协同地学习个DNN网络。其中
个网络用来Embedding源节点,
个网络用来Embedding目标节点。
给定第
种类型的边,
表示源节点,
表示正节点,
表示负节点。我们使用Cosine距离刻画节点之间的相似性,并使用Softmax交叉熵Loss作为Relevance目标
:
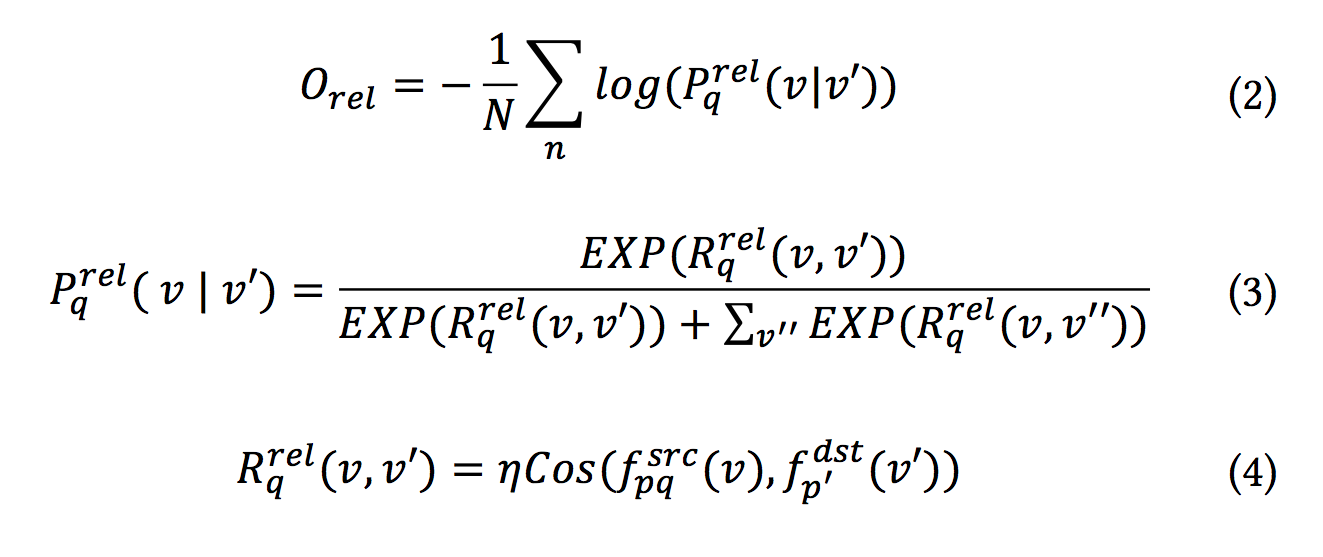
对于一个源节点,我们可以通过每种类型的边得到Q个低维向量
。我们通过Attention机制,自动学习每个向量的权重,把Q个向量合并成一个向量
:
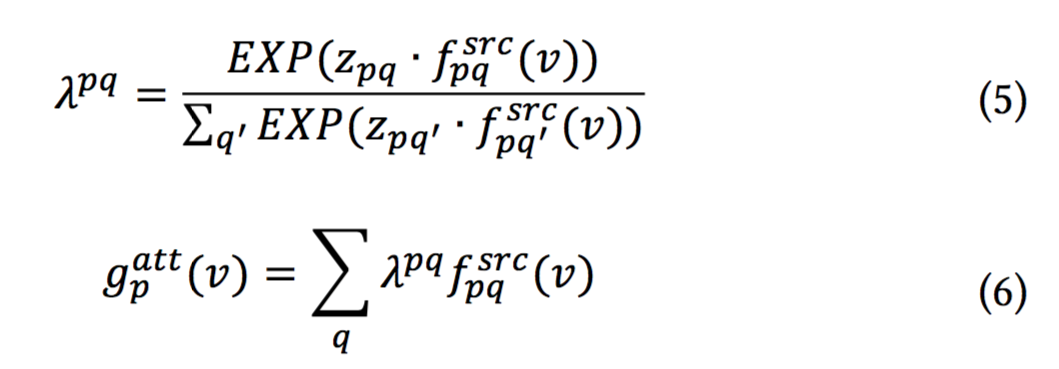
其中表示第p种类型的节点v在第q种类型边上的权重。如果
和
的内积较大,则表明v认为第q种边是有信息的。此外,如果两个节点有着类似的向量,表明它们在图中关系亲密,会有着相似的权重分布。
我们同样使用Cosine距离和Softmax交叉熵Loss作为Attention目标
:
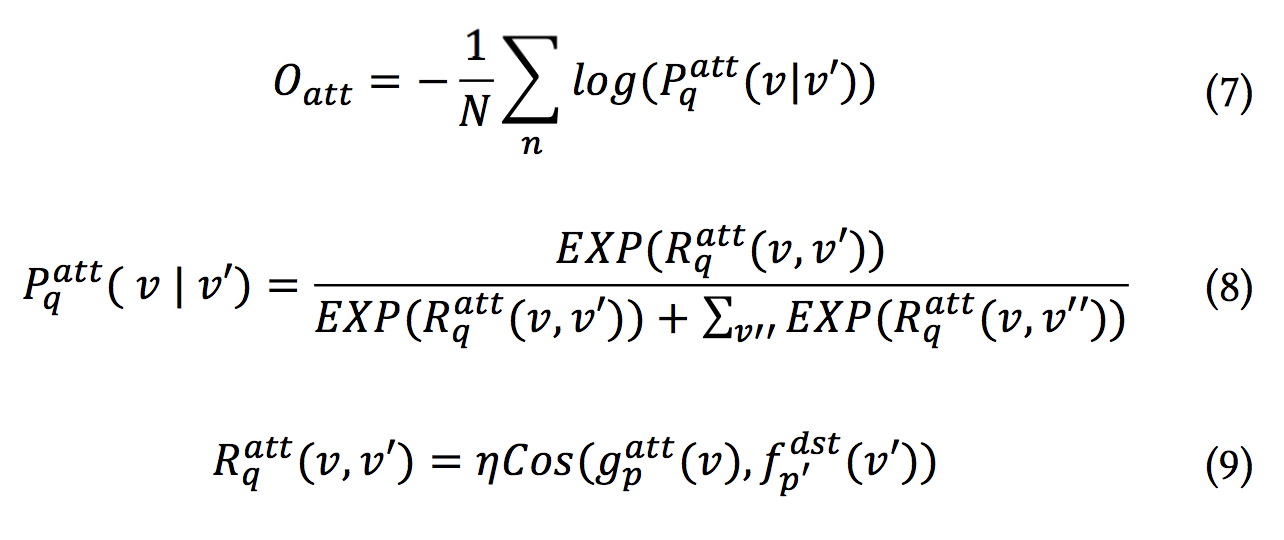
综合和
,算法伪码如下:

我们将所有ad节点的向量存入ANN引擎。线上面对搜索请求时,我们提取搜索意图(query和item),查找对应向量,通过ANN引擎召回最近的K个候选广告。
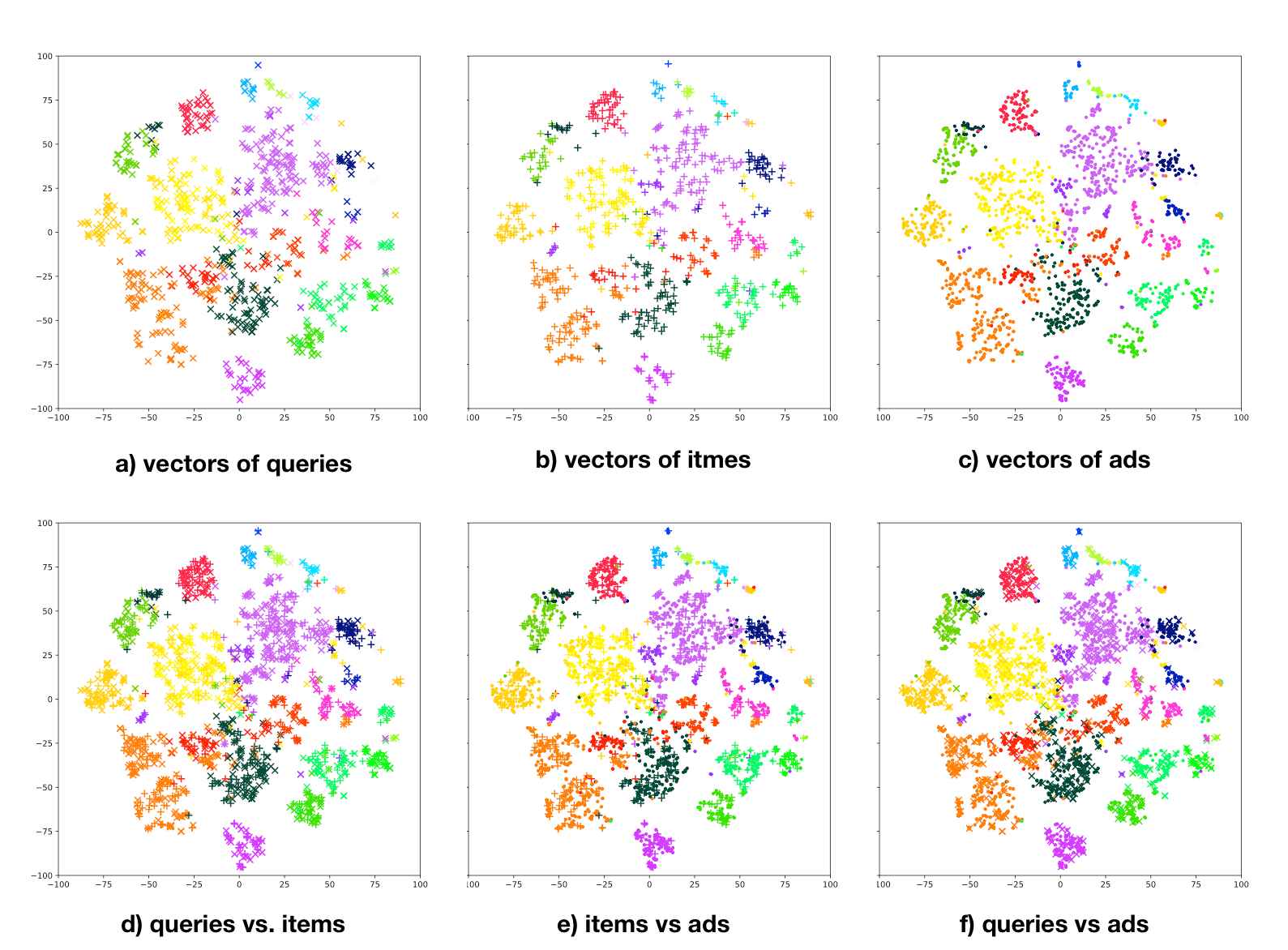
我们使用t-SNE对节点向量进行可视化。可以看到,相似的节点在低维空间上很好地进行了聚集;而且不同种类的节点也确实被投影到同一空间。
同时LsHNE在阿里妈妈搜索广告线上系统取得了良好的效果,CTR、PVR以及RPM均有显著的提升。