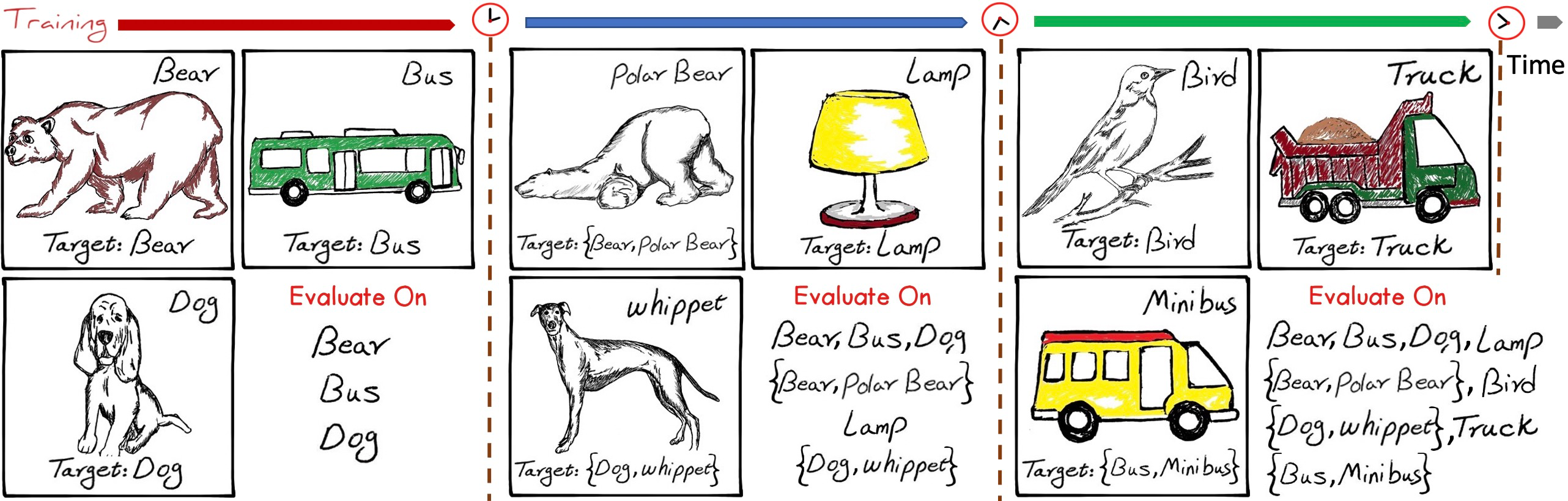
This is the implementation of the IIRC paper. IIRC is a setup and benchmark to evaluate lifelong learning models in more dynamic and real-life aligned scenarios, where the labels are changing in a dynamic way and the models have to use what they have learnt to incorporate these changes into their knowledge. Further details can be found here.
It contains the following two packages as well: iirc and lifelong_methods
iirc is a package for adapting the different datasets (currently supports CIFAR-100 and ImageNet) to the iirc setup and the class incremental learning setup, and loading them in a standardized manner.
lifelong_methods is a package that standardizes the different stages any lifelong learning method passes by, hence it provides a faster way for implementing new ideas and embedding them in the same training code as other baselines, it provides as well the implementation of some of these baselines.
The documentation of these packages is available here
Homepage | Paper | PyPI Package | Package Documentation
The starting point for running this code is experiments/main.py.
The hyperparameter configurations used in the paper are available in a Json format experiments/experiments_configurations folder.
For example, for reproducing the results of experience replay on iirc-ImageNet-lite with a buffer of 20 samples per class:
python main.py --dataset iirc_imagenet_lite --dataset_path "./data/imagenet" --epochs_per_task 100 --batch_size 128
--seed 100 --logging_path_root "./results" -n_layers 50 --tasks_configuration_id 0 --method finetune --optimizer
momentum --lr 0.1 lr_gamma 0.1 --reduce_lr_on_plateau --weight_decay 1e-5 --use_best_model --n_memories_per_class 20
This code has been tested with python 3.8.2 and the following packages:
pytorch==1.5.0
torchvision==0.6.0
numpy==1.18.5
Pillow==7.0.0
lmdb==1.0.0
git+https://[email protected]/shagunsodhani/ml-logger.git@976cab1d2524ee72aef8273e6deb25c764883f3e#egg=mllogger[all] (used for logging)
seaborn==0.10.1 (optional)
pytest==5.4.3 (optional)
pytest-cov==2.9.0 (optional)
To be able to run the code with CIFAR-100 derived datasets, just download the dataset from the official website and extract it, or use the iirc/utils/download_cifar.py file.
The path that should be provided in the dataset_path argument, when running main.py, is the path of the parent directory of the extracted cifar-100-python folder.
In the case of ImageNet, it has to be downloaded manually, and be arranged in the following manner:
- dataset folder
- train
- n01440764
- n01443537
- …
- val
- n01440764
- n01443537
- …
- train
The path that should be provided in the dataset_path argument, when running main.py, is the path of the dataset folder in the previous arrangement.
It's better to provide the dataset_path as an absolute path
If you think you can help us make the iirc and lifelong_methods packages more useful for the lifelong learning community, please don't hesistate to submit an issue or send a pull request.
If you find this work useful for your research, this is the way to cite it:
@misc{abdelsalam2021iirc,
title = {IIRC: Incremental Implicitly-Refined Classification},
author={Mohamed Abdelsalam and Mojtaba Faramarzi and Shagun Sodhani and Sarath Chandar},
year={2021}, eprint={2012.12477}, archivePrefix={arXiv},
primaryClass={cs.CV}}