{kind=link}
This project allows you to download whole dictionary from lingualeo.com and save the new words from choosen text file.
TL;DR
Result of script:
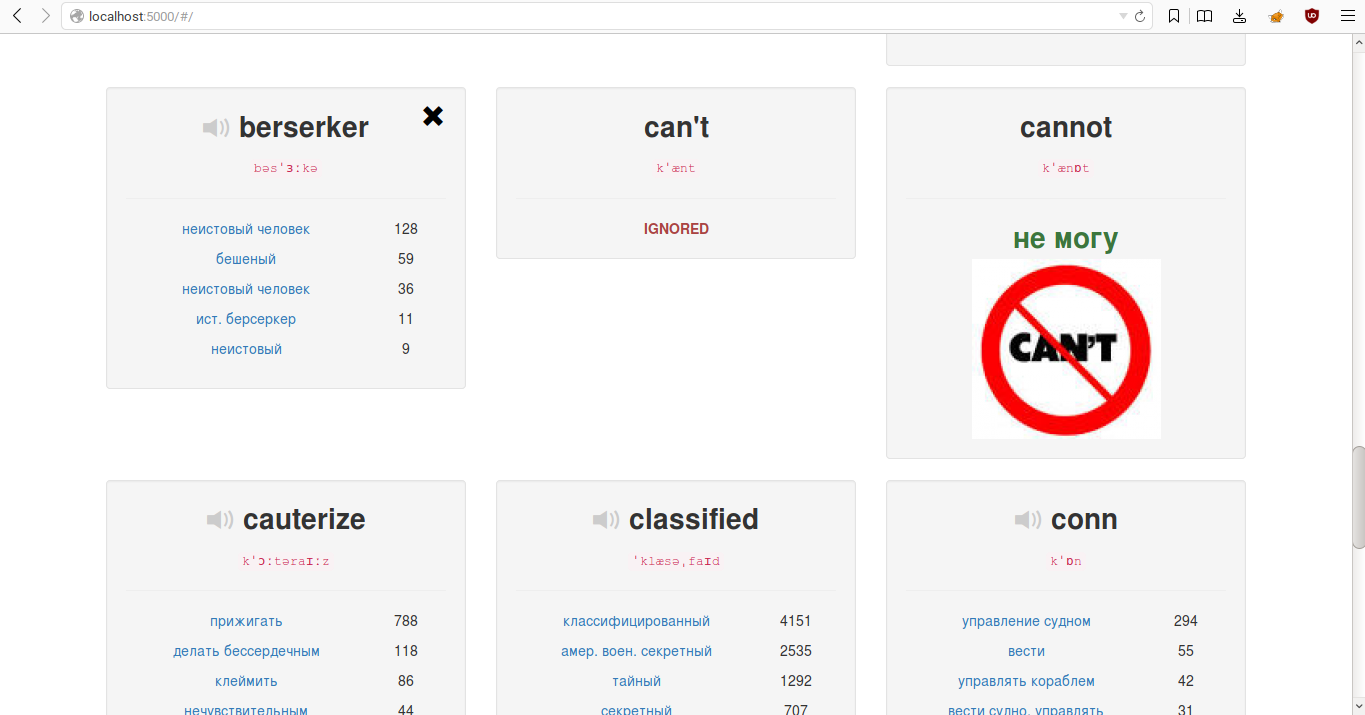
It's pretty simple:
- download or clone this repo
- cd in downloaded dir
- optional: activate virtualenv (docs)
- run
pip3 install -r requirements.txt
At this moment you are ready to run main.py (database in repo is empty, if you want to recreate it — just remove and run python3 models.py):
python3 main.pyand as it is the first run, script will ask you a login data (email, password). If you input it correctly script saved it in config.ini in CREDENTIALS section and never asked it again.
If you do not specify the text file then script just save your whole dictionary from site to dictionary.db otherwise script parsed out the file and save new words in translated_words table of db.
You have two choices:
- save whole dictionary to csv (includes audio and pictures):
python3 main.py --savecsv example.csv- save only new words (translated) by clicking a link on site panel.
Very simple. Now you run python3 server.py and open 127.0.0.1:5000 in browser. Here you can choose the preffered translate for every word or ignore it. Ignored words writes to stopword table and never show up in translated_words again.
Using ffmpeg. For example, we have movie example.mkv, in order to know which stream (streams are video, audio, subtitle) you need you have to run:
~ $ ffmpeg -i exmaple.mkv
.....
Metadata:
title : Dub, AC3 5.1 ~384 kbps
Stream #0:2(eng): Audio: ac3, 48000 Hz, 5.1(side), fltp, 384 kb/s
Metadata:
title : Original, AC3 5.1 ~384 kbps
Stream #0:3(rus): Subtitle: subrip (default)
Metadata:
title : forced
Stream #0:4(rus): Subtitle: subrip
Stream #0:5(eng): Subtitle: subripHere we see Stream #0:5(eng) — that's what we need. Now we map ffmpeg to this stream:
~ $ ffmpeg -i example.mkv -map 0:5 -c copy out.srtand this file you can pass as first argument to script to add words from it.
Yes. Issues and pull requests are welcome.