
This is an attempt to install the k8s cluster proposed in the tutorial kubeadm-ha.
-
VM x 5 : vCPUx2 , vRAM:4GB , Hard Disk: 30GB
-
CentOS 7.4.1708 , Minimal (http://ftp.isu.edu.tw/pub/Linux/CentOS/7/isos/x86_64/CentOS-7-x86_64-Minimal-1708.iso)
-
vNIC x 1 : 10.53.44.0/24
-
a VIP which is binding by keepalived
-
kubectl: 1.9.3
-
kubeadm: 1.9.3
-
kubelet: 1.9.3
-
Docker : 17.12.0-ce
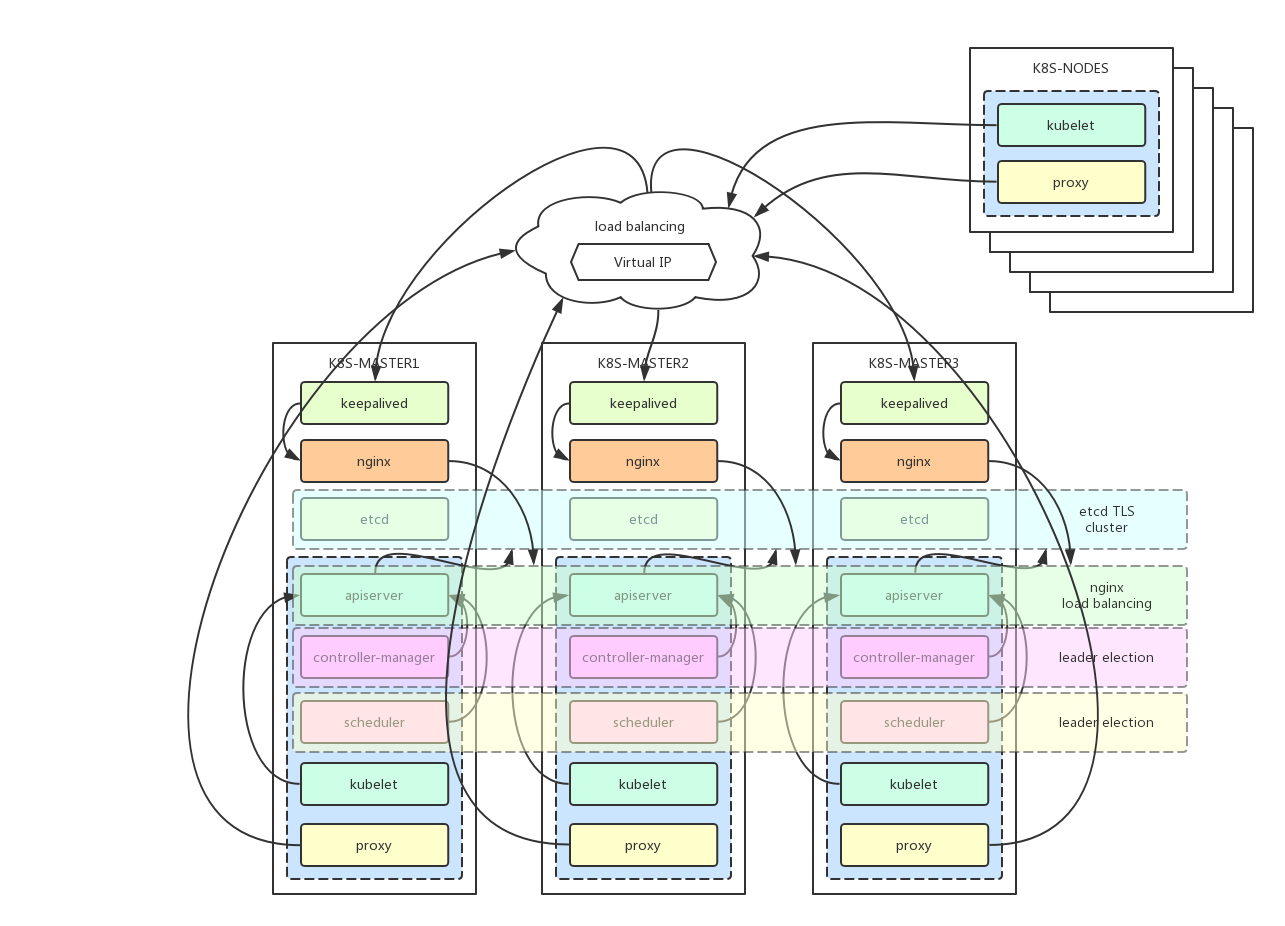
| hostname | IP | Components |
|---|---|---|
| k8s-master1.kubernates.com | 10.53.44.105 | keepalived, nginx, etcd, kubelet, kube-apiserver, kube-scheduler, kube-proxy |
| k8s-master2.kubernates.com | 10.53.44.106 | keepalived, nginx, etcd, kubelet, kube-apiserver, kube-scheduler, kube-proxy |
| k8s-master3.kubernates.com | 10.53.44.107 | keepalived, nginx, etcd, kubelet, kube-apiserver, kube-scheduler, kube-proxy |
| k8s-node1.kubernates.com | 10.53.44.108 | kubelet, kube-proxy |
| k8s-node2.kubernates.com | 10.53.44.109 | kubelet, kube-proxy |
- Keepalived VIP : 10.53.44.110
on master1,2,3, worker1,2
# setup DNS and respective hostname in each Virtual machines
# systemctl disable firewalld && systemctl stop firewalld && systemctl status firewalld
# sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
Turn off swap
# vi /etc/fstab
#/dev/sda4 swap swap defaults 0 0
# reboot
or just swapoff /dev/sda4
# yum install -y yum-utils device-mapper-persistent-data lvm2 ebtables ethtool net-tools ntpdate
# ntpdate 0.asia.pool.ntp.org
on master1,2,3, worker1,2
# yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# yum clean all
# yum --showduplicates list docker
# yum -y install docker-ce.x86_64 17.12.0.ce-1.el7.centos
# systemctl enable docker
Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /usr/lib/systemd/system/docker.service.
# systemctl start docker
# [root@k8s-master01 ~]# docker version
Client:
Version: 17.12.0-ce
API version: 1.35
Go version: go1.9.2
Git commit: c97c6d6
Built: Wed Dec 27 20:10:14 2017
OS/Arch: linux/amd64
Server:
Engine:
Version: 17.12.0-ce
API version: 1.35 (minimum version 1.12)
Go version: go1.9.2
Git commit: c97c6d6
Built: Wed Dec 27 20:12:46 2017
OS/Arch: linux/amd64
Experimental: false
on master1,2,3, worker1,2
# cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
# yum install -y kubelet kubeadm kubectl
# sed -i "s/cgroup-driver=systemd/cgroup-driver=cgroupfs/" /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
# systemctl daemon-reload
# cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# sysctl --system
on master1,2,3
# docker pull quay.io/calico/kube-controllers:v2.0.0
# docker pull quay.io/calico/node:v3.0.2
# docker pull quay.io/calico/cni:v2.0.1
# docker pull quay.io/coreos/flannel:v0.10.0-amd64
# docker pull gcr.io/google_containers/heapster-amd64:v1.5.1
# docker pull gcr.io/google_containers/heapster-grafana-amd64:v4.4.3
# docker pull gcr.io/google_containers/heapster-influxdb-amd64:v1.3.3
# docker pull gcr.io/google_containers/k8s-dns-kube-dns-amd64:1.14.8
# docker pull gcr.io/google_containers/k8s-dns-dnsmasq-nanny-amd64:1.14.8
# docker pull gcr.io/google_containers/k8s-dns-sidecar-amd64:1.14.8
# docker pull gcr.io/google_containers/kube-apiserver-amd64:v1.9.1
# docker pull gcr.io/google_containers/kube-controller-manager-amd64:v1.9.1
# docker pull gcr.io/google_containers/kube-proxy-amd64:v1.9.1
# docker pull gcr.io/google_containers/kube-scheduler-amd64:v1.9.1
# docker pull gcr.io/google_containers/kubernetes-dashboard-amd64:v1.8.2
# docker pull gcr.io/google_containers/etcd-amd64:3.2.14
# docker pull gcr.io/google_containers/pause-amd64:3.1
# docker pull nginx
# docker images
on master1
# mkdir -p /var/lib/etcd-cluster
# docker run --restart always -d -v /etc/ssl/certs:/etc/ssl/certs -v /var/lib/etcd-cluster:/var/lib/etcd -p 2380:2380 -p 2379:2379 --name etcd gcr.io/google_containers/etcd-amd64:3.2.14 etcd --name infra0 --initial-advertise-peer-urls http://10.53.44.105:2380 --listen-peer-urls http://0.0.0.0:2380 --listen-client-urls http://0.0.0.0:2379 --advertise-client-urls http://10.53.44.105:2379 --initial-cluster-token etcd-cluster-1 --initial-cluster infra0=http://10.53.44.105:2380,infra1=http://10.53.44.106:2380,infra2=http://10.53.44.107:2380 --auto-tls --peer-auto-tls --initial-cluster-state new
on master2
# mkdir -p /var/lib/etcd-cluster
# docker run --restart always -d -v /etc/ssl/certs:/etc/ssl/certs -v /var/lib/etcd-cluster:/var/lib/etcd -p 2380:2380 -p 2379:2379 --name etcd gcr.io/google_containers/etcd-amd64:3.2.14 etcd --name infra1 --initial-advertise-peer-urls http://10.53.44.106:2380 --listen-peer-urls http://0.0.0.0:2380 --listen-client-urls http://0.0.0.0:2379 --advertise-client-urls http://10.53.44.106:2379 --initial-cluster-token etcd-cluster-1 --initial-cluster infra0=http://10.53.44.105:2380,infra1=http://10.53.44.106:2380,infra2=http://10.53.44.107:2380 --auto-tls --peer-auto-tls --initial-cluster-state new
on master3
# mkdir -p /var/lib/etcd-cluster
# docker run --restart always -d -v /etc/ssl/certs:/etc/ssl/certs -v /var/lib/etcd-cluster:/var/lib/etcd -p 2380:2380 -p 2379:2379 --name etcd gcr.io/google_containers/etcd-amd64:3.2.14 etcd --name infra2 --initial-advertise-peer-urls http://10.53.44.107:2380 --listen-peer-urls http://0.0.0.0:2380 --listen-client-urls http://0.0.0.0:2379 --advertise-client-urls http://10.53.44.107:2379 --initial-cluster-token etcd-cluster-1 --initial-cluster infra0=http://10.53.44.105:2380,infra1=http://10.53.44.106:2380,infra2=http://10.53.44.107:2380 --auto-tls --peer-auto-tls --initial-cluster-state new
Enter into container and check if etcd cluster is working: on master1
# docker exec -ti $(docker ps -a|grep etcd|awk '{print $1}') ash
/ # etcdctl cluster-health
member 2daaf7000079d672 is healthy: got healthy result from http://10.53.44.105:2379
member 5b48d88ad920b750 is healthy: got healthy result from http://10.53.44.106:2379
member f831bcb90f445493 is healthy: got healthy result from http://10.53.44.107:2379
cluster is healthy
/ # exit
on master1
# yum install -y git
# git clone https://github.com/coolpalani/k8s-kubeadm-ha.git ~/kubeadm-ha
# cd ~/kubeadm-ha
[root@k8s-master01]# vi kubeadm-init-v1.9.3.yaml
apiVersion: kubeadm.k8s.io/v1alpha1
kind: MasterConfiguration
kubernetesVersion: v1.9.3
networking:
podSubnet: 10.244.0.0/16
apiServerCertSANs:
- k8s-master1
- k8s-master2
- k8s-master3
- 10.53.44.105
- 10.53.44.106
- 10.53.44.107
- 10.53.44.110
etcd:
endpoints:
- http://10.53.44.105:2379
- http://10.53.44.106:2379
- http://10.53.44.107:2379
# systemctl daemon-reload
# kubeadm init --config=/root/kubeadm-ha/kubeadm-init-v1.9.3.yaml
Waiting for initialization, then you can see:
Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join --token dbc020.1186330e3b3f9573 10.53.44.105:6443 --discovery-token-ca-cert-hash sha256:c226b2e3b498bd2311f1c14f11422220b3854f8dcf0a71c28850ea444452f1fe
**remember the kubeadm join token
on master1
copy Kube Config to root directory
# mkdir -p .kube
# cp /etc/kubernetes/admin.conf ~/.kube/config
then test it:
# [root@k8s-master1 ~]# kubectl get pods --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE
kube-system kube-apiserver-k8s-master1.kubernates.com 1/1 Running 0 46s 10.53.44.105 k8s-master1.kubernates.com
kube-system kube-controller-manager-k8s-master1.kubernates.com 1/1 Running 0 37s 10.53.44.105 k8s-master1.kubernates.com
kube-system kube-dns-6f4fd4bdf-545z4 0/3 Pending 0 1m <none> <none>
kube-system kube-proxy-2vqm5 1/1 Running 0 1m 10.53.44.105 k8s-master1.kubernates.com
kube-system kube-scheduler-k8s-master1.kubernates.com 1/1 Running 0 25s 10.53.44.105 k8s-master1.kubernates.com
# vi /etc/kubernetes/manifests/kube-apiserver.yaml
delete this line:
- --admission-control=Initializers,NamespaceLifecycle,LimitRanger,ServiceAccount,PersistentVolumeLabel,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,ResourceQuota
add this line:
- --admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,PersistentVolumeLabel,DefaultStorageClass,ResourceQuota,DefaultTolerationSeconds
Restart kubelet and docker
# systemctl restart docker kubelet
Wait for 30 seconds to see if container : 'k8s_kube-apiserver_kube-apiserver-k8s-master1_kube-system_xxx' is started
# docker ps -a|grep apiserver
on master1
# kubectl create -f /root/kubeadm-ha/kube-flannel
configmap "calico-config" unchanged
secret "calico-etcd-secrets" configured
daemonset "calico-node" configured
deployment "calico-kube-controllers" unchanged
serviceaccount "calico-kube-controllers" unchanged
serviceaccount "calico-node" unchanged
clusterrole "calico-kube-controllers" configured
clusterrolebinding "calico-kube-controllers" configured
clusterrole "calico-node" configured
clusterrolebinding "calico-node" configured
# [root@k8s-master1 kubeadm-ha]# kubectl get pods --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE
kube-system kube-apiserver-k8s-master1.kubernates.com 1/1 Running 1 6m 10.53.44.105 k8s-master1.kubernates.com
kube-system kube-controller-manager-k8s-master1.kubernates.com 1/1 Running 1 10m 10.53.44.105 k8s-master1.kubernates.com
kube-system kube-dns-6f4fd4bdf-545z4 3/3 Running 0 11m 10.244.0.2 k8s-master1.kubernates.com
kube-system kube-flannel-ds-dxvzt 2/2 Running 0 50s 10.53.44.105 k8s-master1.kubernates.com
kube-system kube-proxy-2vqm5 1/1 Running 1 11m 10.53.44.105 k8s-master1.kubernates.com
kube-system kube-scheduler-k8s-master1.kubernates.com 1/1 Running 1 10m 10.53.44.105 k8s-master1.kubernates.com
waiting for 30 seconds then check flannel interface You should see those two interfaces: cni0, flannel.1
# ifconfig|grep MULT
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1400
:
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1400
:
untaint master1 in order to schedule resources
# [root@k8s-master1 kubeadm-ha]# kubectl describe node k8s-master1|grep Taints
Taints: node-role.kubernetes.io/master:NoSchedule
# [root@k8s-master1 kubeadm-ha]# kubectl taint nodes --all node-role.kubernetes.io/master-
node "k8s-master1.kubernates.com" untainted
# [root@k8s-master1 kubeadm-ha]# kubectl describe node k8s-master1|grep Taints
Taints: <none>
on master1
# scp -r /etc/kubernetes/ k8s-master2:/etc/
# scp -r /etc/kubernetes/ k8s-master3:/etc/
restart kubelet to bring up the cluster on master2,3
# systemctl daemon-reload && systemctl restart kubelet
# mkdir -p .kube
# cp /etc/kubernetes/admin.conf ~/.kube/config
Join master2 & master 3 into cluster on master1
# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
dbc020.1186330e3b3f9573 22h 2018-02-22T18:44:45+05:30 authentication,signing The default bootstrap token generated by 'kubeadm init'. system:bootstrappers:kubeadm:default-node-token
on master2,3
# ps ax|grep kubelet
There is no kubelet process
# kubeadm join --token dbc020.1186330e3b3f9573 10.53.44.105:6443 --skip-preflight-checks --discovery-token-unsafe-skip-ca-verification
# [root@k8s-master3 ~]# ps ax|grep kubelet
1379 ? Ssl 0:00 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true --network-plugin=cni --cni-conf-dir=/etc/cni/net.d --cni-bin-dir=/opt/cni/bin --cluster-dns=10.96.0.10 --cluster-domain=cluster.local --authorization-mode=Webhook --client-ca-file=/etc/kubernetes/pki/ca.crt --cadvisor-port=0 --cgroup-driver=cgroupfs --rotate-certificates=true --cert-dir=/var/lib/kubelet/pki
The kubelet is running now
waiting for a few minutes.....then you can verify the nodes are been joined.
# [root@k8s-master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1.kubernates.com Ready master 1h v1.9.3
k8s-master2.kubernates.com Ready <none> 3m v1.9.3
k8s-master3.kubernates.com Ready <none> 3m v1.9.3
# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
Edit configuration files
on master2,3
edit kube-apiserver.yaml file, replace ${HOST_IP} to current host's IP address
# vi /etc/kubernetes/manifests/kube-apiserver.yaml
- --advertise-address=${HOST_IP}
on master2,3
edit kubelet.conf file, replace ${HOST_IP} to current host's IP address
# vi /etc/kubernetes/kubelet.conf
server: https://${HOST_IP}:6443
on master2,3
edit admin.conf file, replace ${HOST_IP} to current host's IP address
# vi /etc/kubernetes/admin.conf
server: https://${HOST_IP}:6443
# cp /etc/kubernetes/admin.conf ~/.kube/config
on master2,3
edit controller-manager.conf file, replace ${HOST_IP} to current host's IP address
# vi /etc/kubernetes/controller-manager.conf
server: https://${HOST_IP}:6443
on master2,3
edit scheduler.conf file, replace ${HOST_IP} to current host's IP address
$ vi /etc/kubernetes/scheduler.conf
server: https://${HOST_IP}:6443
on master2,3
restart docker and kubelet services
# systemctl daemon-reload && systemctl restart docker kubelet
on master1
#[root@k8s-master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1.kubernates.com Ready master 1h v1.9.3
k8s-master2.kubernates.com Ready <none> 3m v1.9.3
k8s-master3.kubernates.com Ready <none> 3m v1.9.3
#[root@k8s-master1]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
#[root@k8s-master1 ~]# kubectl label nodes k8s-master2.kubernates.com node-role.kubernetes.io/master=
node "k8s-master2.kubernates.com" labeled
#[root@k8s-master1 ~]# kubectl label nodes k8s-master3.kubernates.com node-role.kubernetes.io/master=
node "k8s-master3.kubernates.com" labeled
#[root@k8s-master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1.kubernates.com Ready master 1h v1.9.3
k8s-master2.kubernates.com Ready master 18m v1.9.3
k8s-master3.kubernates.com Ready master 18m v1.9.3
on master1
check deployment
#[root@k8s-master1 ~]# kubectl get deploy --all-namespaces -o wide
NAMESPACE NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
kube-system calico-kube-controllers 1 1 1 1 1h calico-kube-controllers quay.io/calico/kube-controllers:v2.0.0 k8s-app=calico-kube-controllers
kube-system heapster 1 1 1 1 14m heapster gcr.io/google_containers/heapster-amd64:v1.4.2 k8s-app=heapster,task=monitoring
kube-system kube-dns 1 1 1 1 1h kubedns,dnsmasq,sidecar gcr.io/google_containers/k8s-dns-kube-dns-amd64:1.14.7,gcr.io/google_containers/k8s-dns-dnsmasq-nanny-amd64:1.14.7,gcr.io/google_containers/k8s-dns-sidecar-amd64:1.14.7 k8s-app=kube-dns
kube-system kubernetes-dashboard 1 1 1 1 43m kubernetes-dashboard gcr.io/google_containers/kubernetes-dashboard-amd64:v1.8.2 k8s-app=kubernetes-dashboard
kube-system monitoring-grafana 1 1 1 1 14m grafana gcr.io/google_containers/heapster-grafana-amd64:v4.4.3 k8s-app=grafana,task=monitoring
kube-system monitoring-influxdb 1 1 1 1 14m influxdb gcr.io/google_containers/heapster-influxdb-amd64:v1.3.3
on k8s-master1 or k8s-master2 or k8s-master3: scale up kube-dns, calico-kube-controllers, kubernetes-dashboard replicas to 3, make all master running kube-dns
#[root@k8s-master1 ~]# kubectl scale --replicas=3 -n kube-system deployment/kube-dns
deployment "kube-dns" scaled
#[root@k8s-master1 ~]# kubectl scale --replicas=3 -n kube-system deployment/calico-kube-controllers
deployment "calico-kube-controllers" scaled
#[root@k8s-master1 ~]# kubectl scale --replicas=3 -n kube-system deployment/kubernetes-dashboard
deployment "kubernetes-dashboard" scaled
#[root@k8s-master1 ~]# kubectl scale --replicas=3 -n kube-system deployment/heapster
deployment "heapster" scaled
#[root@k8s-master1 ~]# kubectl get deploy -n kube-system
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
calico-kube-controllers 3 3 3 3 1h
heapster 3 3 3 1 22m
kube-dns 3 3 3 3 1h
kubernetes-dashboard 3 3 3 3 52m
monitoring-grafana 1 1 1 1 22m
monitoring-influxdb 1 1 1 1 22m
#[root@k8s-master1 ~]# kubectl get pods --all-namespaces -o wide
The dns pod should be run on each of nodes.
on master1,2,3
# yum install -y keepalived
# vi /etc/keepalived/keepalived-k8s.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state ${STATE}
interface ${INTERFACE_NAME}
mcast_src_ip ${HOST_IP}
virtual_router_id ${VROUTER_ID}
priority ${PRIORITY}
advert_int 2
authentication {
auth_type PASS
auth_pass 4be37dc3b4c90194d1600c483e10ad1d
}
virtual_ipaddress {
${VIRTUAL_IP}
}
track_script {
chk_apiserver
}
}
Replace ${XXX} , where ${XXX} on k8s-master1,2,3 is:
| node | ${STATE} | ${INTERFACE_NAME} | ${HOST_IP} | ${PRIORITY} | ${VIRTUAL_IP} |
|---|---|---|---|---|---|
| master1 | MASTER | eth0 | 10.53.44.105 | 100 | 10.53.44.110 |
| master2 | BACKUP | eth0 | 10.53.44.106 | 90 | 10.53.44.110 |
| master3 | BACKUP | eth0 | 10.53.44.107 | 90 | 10.53.44.110 |
${VROUTER_ID} should be avoided when people are using the same network(10.53.44.0/24) For Example: virtual_router_id 178 ==> Tony virtual_router_id 168 ==> Robin virtual_router_id 180 ==> Zic virtual_router_id 181 ==> Jin virtual_router_id 182 ==> Alan
# vi /etc/keepalived/check_apiserver.sh
#!/bin/bash
err=0
for k in $( seq 1 10 )
do
check_code=$(ps -ef|grep kube-apiserver | wc -l)
if [ "$check_code" = "1" ]; then
err=$(expr $err + 1)
sleep 5
continue
else
err=0
break
fi
done
if [ "$err" != "0" ]; then
echo "systemctl stop keepalived"
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi
# chmod a+x /etc/keepalived/check_apiserver.sh
start-up keepalived with systemd
# echo 'KEEPALIVED_OPTIONS="-D -f /etc/keepalived/keepalived-k8s.conf -p /var/run/keepalived-k8s.pid -r /var/run/vrrp-k8s.pid -c /var/run/checkers-k8s.pid"' > /etc/sysconfig/keepalived-k8s
# vi /usr/lib/systemd/system/keepalived-k8s.service
[Unit]
Description=LVS and VRRP High Availability Monitor
After=syslog.target network.target
[Service]
Type=forking
KillMode=process
PIDFile=/var/run/keepalived-k8s.pid
EnvironmentFile=-/etc/sysconfig/keepalived-k8s
ExecStart=/usr/sbin/keepalived $KEEPALIVED_OPTIONS
ExecReload=/bin/kill -HUP $MAINPID
[Install]
WantedBy=multi-user.target
Start keepalived service
# systemctl daemon-reload; systemctl enable keepalived-k8s
# systemctl start keepalived-k8s
Check keepalived service and VIP is working or not
# systemctl status keepalived-k8s
# journalctl -xu keepalived-k8s |egrep 'MASTER|BACKUP'
#[root@k8s-master1 ~]# ip a|grep $(cat /etc/keepalived/keepalived-k8s.conf|grep -A1 virtual_ipaddress|tail -1|sed -e 's/^ *//')
inet 10.53.44.110/32 scope global eth0
ping VIP from your network
c:\> ping 10.53.44.110
nginx load balancer configuration
on master1,2,3 Edit nginx configration
# cat <<EOF > /root/kubeadm-ha/kubeadm-ha.conf
stream {
upstream apiserver {
server 10.53.44.105:6443 weight=5 max_fails=3 fail_timeout=30s;
server 10.53.44.106:6443 weight=5 max_fails=3 fail_timeout=30s;
server 10.53.44.107:6443 weight=5 max_fails=3 fail_timeout=30s;
}
server {
listen 8443;
proxy_connect_timeout 1s;
proxy_timeout 3s;
proxy_pass apiserver;
}
}
events {
worker_connections 1024;
}
EOF
Start Nginx Container:
# docker run -d -p 8443:8443 \
--name nginx-lb \
--restart always \
-v /root/kubeadm-ha/kubeadm-ha.conf:/etc/nginx/nginx.conf \
nginx
Check Nginx Container:
#[root@k8s-master3 ~]# docker ps -a|grep nginx-lb
ce77e117f710 nginx "nginx -g 'daemon of…" 2 minutes ago Up 2 minutes 80/tcp, 0.0.0.0:8443->8443/tcp nginx-lb
# docker logs
on master1
# kubectl get -n kube-system configmap
#[root@k8s-master1 ~]# kubectl get -n kube-system configmap
NAME DATA AGE
calico-config 6 20h
extension-apiserver-authentication 6 21h
kube-flannel-cfg 2 21h
kube-proxy 2 21h
kubeadm-config 1 21h
kubernetes-dashboard-settings 1 20h
#[root@k8s-master1 ~]# kubectl edit -n kube-system configmap/kube-proxy
Edit this line, replace this IP as VIP(10.53.44.110)
server: https://10.53.44.105:6443
to
server: https://10.53.44.110:8443
check configmap/kube-proxy setting:
#[root@k8s-master1 ~]# kubectl get -n kube-system configmap/kube-proxy -o yaml|grep 'server:'
server: https://10.53.44.110:8443
on master1
delete all kube-proxy pods, kube-proxy pods will re-create automatically
#[root@k8s-master1 ~]# kubectl get pods -n kube-system|grep kube-proxy
kube-proxy-2vqm5 1/1 Running 1 2h
kube-proxy-695nt 1/1 Running 1 53m
kube-proxy-d5nrp 1/1 Running 1 53m
#[root@k8s-master1 ~]# kubectl -n kube-system delete $(kubectl -n kube-system get pod -o name | grep kube-proxy)
pod "kube-proxy-2vqm5" deleted
pod "kube-proxy-695nt" deleted
pod "kube-proxy-d5nrp" deleted
waiting daemonset to rebuild
#[root@k8s-master1 ~]# kubectl get pods --all-namespaces |grep proxy
kube-system kube-proxy-7qkt5 1/1 Running 0 15s
kube-system kube-proxy-lbgsj 1/1 Running 0 4s
kube-system kube-proxy-qrnlt 1/1 Running 0 5s
on master1
#[root@k8s-master1 ~]# kubectl patch node k8s-master1.kubernates.com -p '{"spec":{"unschedulable":true}}'
node "k8s-master1.kubernates.com" patched
#[root@k8s-master1 ~]# kubectl patch node k8s-master2.kubernates.com -p '{"spec":{"unschedulable":true}}'
node "k8s-master2.kubernates.com" patched
#[root@k8s-master1 ~]# kubectl patch node k8s-master3.kubernates.com -p '{"spec":{"unschedulable":true}}'
node "k8s-master3.kubernates.com" patched
check if scheduling is disabled:
#[root@k8s-master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1.kubernates.com Ready,SchedulingDisabled master 2h v1.9.3
k8s-master2.kubernates.com Ready,SchedulingDisabled master 58m v1.9.3
k8s-master3.kubernates.com Ready,SchedulingDisabled master 58m v1.9.3
on master1
You DON'T need to do this step if kubeadm token is still unexpired (is existing) Create a new token if the old token is expired.
#[root@k8s-master ~]# kubeadm token create
#[root@k8s-master1 ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
dbc020.1186330e3b3f9573 21h 2018-02-22T18:44:45+05:30 authentication,signing The default bootstrap token generated by 'kubeadm init'. system:bootstrappers:kubeadm:default-node-token
on worker1,2
# mkdir ~/.kube
# scp root@k8s-master1:/etc/kubernetes/admin.conf ~/.kube/config
Change master1 IP to keepalived VIP:
# vi ~/.kube/config
server: https://10.53.44.105:6443
to
server: https://10.53.44.110:6443
Join worker nodes into cluster
# kubeadm join --token dbc020.1186330e3b3f9573 10.53.44.105:6443 --skip-preflight-checks --discovery-token-unsafe-skip-ca-verification
[discovery] Trying to connect to API Server "10.53.44.105:6443"
[discovery] Created cluster-info discovery client, requesting info from "https://10.53.44.105:6443"
[discovery] Cluster info signature and contents are valid and no TLS pinning was specified, will use API Server "10.53.44.105:6443"
[discovery] Successfully established connection with API Server "10.53.44.105:6443"
This node has joined the cluster:
* Certificate signing request was sent to master and a response
was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the master to see this node join the cluster.
#[root@k8s-node1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1.kubernates.com Ready,SchedulingDisabled master 16h v1.9.3
k8s-master2.kubernates.com Ready,SchedulingDisabled master 15h v1.9.3
k8s-master3.kubernates.com Ready,SchedulingDisabled master 15h v1.9.3
k8s-node1.kubernates.com Ready <none> 13h v1.9.3
k8s-node2.kubernates.com Ready <none> 13h v1.9.3
Change kubelet connection
# vi /etc/kubernetes/kubelet.conf
server: https://10.53.44.105:6443
to
server: https://10.53.44.110:8443
# systemctl restart kubelet
on any node (master1 or 2 or 3 or worker1 or 2)
- Check health status
#[root@k8s-node1 ~]# kubectl get pod --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-7749c84f4-cc8f8 1/1 Running 0 14h
kube-system calico-kube-controllers-7749c84f4-gcmck 1/1 Running 0 14h
kube-system calico-kube-controllers-7749c84f4-htk5p 1/1 Running 0 15h
kube-system calico-node-h2cqs 2/2 Running 2 15h
kube-system calico-node-nj8qs 2/2 Running 0 13h
kube-system calico-node-rwnrh 2/2 Running 0 15h
kube-system calico-node-svgvt 2/2 Running 2 15h
kube-system calico-node-xjzvc 2/2 Running 0 13h
kube-system heapster-698c5f45bd-bjnqr 1/1 Running 0 15h
kube-system heapster-698c5f45bd-gzlkd 1/1 Running 0 14h
kube-system heapster-698c5f45bd-kf26m 1/1 Running 0 14h
kube-system kube-apiserver-k8s-master1.kubernates.com 1/1 Running 1 16h
kube-system kube-apiserver-k8s-master2.kubernates.com 1/1 Running 0 14h
kube-system kube-apiserver-k8s-master3.kubernates.com 1/1 Running 0 14h
kube-system kube-controller-manager-k8s-master1.kubernates.com 1/1 Running 1 16h
kube-system kube-controller-manager-k8s-master2.kubernates.com 1/1 Running 1 15h
kube-system kube-controller-manager-k8s-master3.kubernates.com 1/1 Running 1 15h
kube-system kube-dns-6f4fd4bdf-545z4 3/3 Running 0 16h
kube-system kube-dns-6f4fd4bdf-bw792 3/3 Running 0 14h
kube-system kube-dns-6f4fd4bdf-jgp5q 3/3 Running 0 14h
kube-system kube-flannel-ds-bhv4m 2/2 Running 3 15h
kube-system kube-flannel-ds-dxvzt 2/2 Running 0 16h
kube-system kube-flannel-ds-gpb5m 2/2 Running 0 13h
kube-system kube-flannel-ds-m7j5r 2/2 Running 3 15h
kube-system kube-flannel-ds-mqsgr 2/2 Running 0 13h
kube-system kube-proxy-26vsm 1/1 Running 0 13h
kube-system kube-proxy-7qkt5 1/1 Running 0 14h
kube-system kube-proxy-lbgsj 1/1 Running 0 14h
kube-system kube-proxy-qrnlt 1/1 Running 0 14h
kube-system kube-proxy-zxz6j 1/1 Running 0 13h
kube-system kube-scheduler-k8s-master1.kubernates.com 1/1 Running 1 16h
kube-system kube-scheduler-k8s-master2.kubernates.com 1/1 Running 1 15h
kube-system kube-scheduler-k8s-master3.kubernates.com 1/1 Running 1 15h
kube-system kubernetes-dashboard-6f8bfb4cf6-2w86k 1/1 Running 0 15h
kube-system kubernetes-dashboard-6f8bfb4cf6-46j4c 1/1 Running 0 14h
kube-system kubernetes-dashboard-6f8bfb4cf6-np2vf 1/1 Running 0 14h
kube-system monitoring-grafana-5ffb49ff84-4w9f9 1/1 Running 0 15h
kube-system monitoring-influxdb-5b77d47fdd-xv8t4 1/1 Running 0 15h
#[root@k8s-node1 ~]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
on any node (master1 or 2 or 3 or worker1 or 2)
- Create one deployment without crash
#[root@k8s-node1 ~]# kubectl run nginx --image=nginx --port=80
deployment "nginx" created
#[root@k8s-node1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-7587c6fdb6-wrmhx 1/1 Running 0 17s
on master1
- Power-off master1 node
#[root@k8s-master1 ~]# poweroff
on master2 or 3
- Check the node where VIP is binding
#[root@k8s-master2 ~]# ip a|grep $(cat /etc/keepalived/keepalived-k8s.conf|grep -A1 virtual_ipaddress|tail -1|sed -e 's/^ *//')
inet 10.53.44.110/32 scope global eth0
on any node (master2 or 3 or worker1 or 2)
- Check health status when master1 is crashed
#[root@k8s-master2 ~]# kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-2 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}
etcd-0 Unhealthy Get http://10.53.44.105:2379/health: dial tcp 10.53.44.105:2379: getsockopt: no route to host
#[root@k8s-master2 ~]# docker exec -ti $(docker ps -a|grep etcd|awk '{print $1}') ash
/ # etcdctl cluster-health
failed to check the health of member 2daaf7000079d672 on http://10.53.44.105:2379: Get http://10.53.44.105:2379/health: dial tcp 10.53.44.105:2379: getsockopt: no route to host
member 2daaf7000079d672 is unreachable: [http://10.53.44.105:2379] are all unreachable
member 5b48d88ad920b750 is healthy: got healthy result from http://10.53.44.106:2379
member f831bcb90f445493 is healthy: got healthy result from http://10.53.44.107:2379
cluster is healthy
/ # exit
#[root@k8s-master2 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1.kubernates.com NotReady,SchedulingDisabled master 16h v1.9.3
k8s-master2.kubernates.com Ready,SchedulingDisabled master 15h v1.9.3
k8s-master3.kubernates.com Ready,SchedulingDisabled master 15h v1.9.3
k8s-node1.kubernates.com Ready <none> 13h v1.9.3
k8s-node2.kubernates.com Ready <none> 13h v1.9.3
* Create one deployment when master1 is crashed
# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-7cbc4b4d9c-654rh 1/1 Running 0 2h 10.244.4.2 k8s-worker1
nginx2-7895f859bf-z6s7c 1/1 Running 0 2h 10.244.4.4 k8s-worker1
- Create 100 deployments when master1 is crashed You can check the scheduler which should create 100 deployments on worker1,2 separately. Also, the memory usage is very cost saving (less than 1GB) when mass deployments created.
# for ((i=3;i<=100;i++)); do kubectl run nginx$i --image=nginx --port=80; done
# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-7cbc4b4d9c-654rh 1/1 Running 0 3h 10.244.4.2 k8s-worker1
nginx1-6ff498c98f-stjmc 1/1 Running 0 4m 10.244.3.2 k8s-worker2
nginx10-7f6c7c8487-v4ncb 1/1 Running 0 4m 10.244.3.7 k8s-worker2
nginx100-fc8966b57-prtn8 1/1 Running 0 3m 10.244.3.52 k8s-worker2
nginx11-77bc64c7df-zhwfh 1/1 Running 0 4m 10.244.4.8 k8s-worker1
nginx12-5b65fbffc5-hncr4 1/1 Running 0 4m 10.244.3.8 k8s-worker2
nginx13-64955ccd5c-f78cb 1/1 Running 0 4m 10.244.4.9 k8s-worker1
nginx14-7c69b69b5f-sn54c 1/1 Running 0 4m 10.244.3.9 k8s-worker2
nginx15-89cb6777-jrvtm 1/1 Running 0 4m 10.244.4.10 k8s-worker1
nginx16-57c48cb567-gs5xn 1/1 Running 0 4m 10.244.3.10 k8s-worker2
nginx17-644c59d4f-vptc5 1/1 Running 0 4m 10.244.3.12 k8s-worker2
nginx18-76bf57c895-dj6gx 1/1 Running 0 4m 10.244.3.11 k8s-worker2
nginx19-6bcdb9c6b5-ccc7l 1/1 Running 0 4m 10.244.3.13 k8s-worker2
nginx2-7895f859bf-z6s7c 1/1 Running 0 2h 10.244.4.4 k8s-worker1
nginx20-846f6897f7-nt5t9 1/1 Running 0 4m 10.244.3.14 k8s-worker2
nginx21-6c9cb64c67-sx82j 1/1 Running 0 4m 10.244.4.11 k8s-worker1
nginx22-5b595b8789-dlft6 1/1 Running 0 4m 10.244.4.12 k8s-worker1
nginx23-7d94fdd5bc-w5hr4 1/1 Running 0 3m 10.244.4.13 k8s-worker1
nginx24-58fd9648b9-gpmfd 1/1 Running 0 3m 10.244.3.15 k8s-worker2
nginx25-7b667bb447-xt2vq 1/1 Running 0 3m 10.244.4.14 k8s-worker1
nginx26-76d6ff9cd9-kcwz8 1/1 Running 0 3m 10.244.3.16 k8s-worker2
nginx27-fd649dbdc-bzv6f 1/1 Running 0 3m 10.244.4.15 k8s-worker1
nginx28-5fdc6f4dfc-h8qrk 1/1 Running 0 3m 10.244.3.17 k8s-worker2
nginx29-6d8df9f4c9-fbljf 1/1 Running 0 3m 10.244.4.16 k8s-worker1
nginx3-9f8849c9c-jkn6w 1/1 Running 0 4m 10.244.3.3 k8s-worker2
nginx30-85b77fb579-4c7kz 1/1 Running 0 3m 10.244.3.18 k8s-worker2
nginx31-994ffc9b5-zgq72 1/1 Running 0 3m 10.244.4.17 k8s-worker1
nginx32-66b64549c9-2qw8h 1/1 Running 0 3m 10.244.3.19 k8s-worker2
nginx33-77f5cfdf7-qqd2j 1/1 Running 0 3m 10.244.4.18 k8s-worker1
nginx34-6d7c6cb56c-nb62x 1/1 Running 0 3m 10.244.3.20 k8s-worker2
nginx35-6c8f57c669-h5zsm 1/1 Running 0 3m 10.244.3.21 k8s-worker2
nginx36-84cc9559f-rtchv 1/1 Running 0 3m 10.244.3.22 k8s-worker2
nginx37-5f5945d9df-pchhj 1/1 Running 0 3m 10.244.4.19 k8s-worker1
nginx38-67f4df56c5-cnhnm 1/1 Running 0 3m 10.244.4.20 k8s-worker1
nginx39-67c4b47dd5-mnr6h 1/1 Running 0 3m 10.244.4.21 k8s-worker1
nginx4-69bd456789-p4h47 1/1 Running 0 4m 10.244.3.4 k8s-worker2
nginx40-85d45df957-4hzh5 1/1 Running 0 3m 10.244.4.22 k8s-worker1
nginx41-6867957b95-ps7d9 1/1 Running 0 3m 10.244.4.23 k8s-worker1
nginx42-b65ffdf89-287qn 1/1 Running 0 3m 10.244.3.23 k8s-worker2
nginx43-5b5cdfb979-52h2h 1/1 Running 0 3m 10.244.4.24 k8s-worker1
nginx44-74d9bc86d5-q54ss 1/1 Running 0 3m 10.244.3.24 k8s-worker2
nginx45-67df9c7599-77q4l 1/1 Running 0 3m 10.244.4.25 k8s-worker1
nginx46-c5c584dd5-246w2 1/1 Running 0 3m 10.244.3.25 k8s-worker2
nginx47-5f4d7d7995-pt2w5 1/1 Running 0 3m 10.244.4.26 k8s-worker1
nginx48-754f7fddc7-vd6bl 1/1 Running 0 3m 10.244.3.26 k8s-worker2
nginx49-679fb86879-j5lh7 1/1 Running 0 3m 10.244.3.28 k8s-worker2
nginx5-5db796d7fc-kppr5 1/1 Running 0 4m 10.244.3.5 k8s-worker2
nginx50-6968885495-nwzfp 1/1 Running 0 3m 10.244.3.27 k8s-worker2
nginx51-795f64d4d9-dgd5n 1/1 Running 0 3m 10.244.3.29 k8s-worker2
nginx52-8454dc957f-gzjvr 1/1 Running 0 3m 10.244.3.30 k8s-worker2
nginx53-8668cdbd5c-lpddc 1/1 Running 0 3m 10.244.4.27 k8s-worker1
nginx54-7cc55c76ff-v7894 1/1 Running 0 3m 10.244.4.28 k8s-worker1
nginx55-6497d6d769-g2k8m 1/1 Running 0 3m 10.244.4.29 k8s-worker1
nginx56-5ddd45c895-t8fbx 1/1 Running 0 3m 10.244.3.31 k8s-worker2
nginx57-8cb77d57c-gndwn 1/1 Running 0 3m 10.244.4.30 k8s-worker1
nginx58-6f94b548c9-p6c24 1/1 Running 0 3m 10.244.3.32 k8s-worker2
nginx59-75d487ddbf-fb99k 1/1 Running 0 3m 10.244.4.31 k8s-worker1
nginx6-678844d4df-r8mcj 1/1 Running 0 4m 10.244.3.6 k8s-worker2
nginx60-7d7bf4f5d9-jpwtn 1/1 Running 0 3m 10.244.3.33 k8s-worker2
nginx61-7dc45f5447-6q55n 1/1 Running 0 3m 10.244.4.32 k8s-worker1
nginx62-cc77fbbfc-2jx9j 1/1 Running 0 3m 10.244.3.34 k8s-worker2
nginx63-d5564475f-wffpb 1/1 Running 0 3m 10.244.4.33 k8s-worker1
nginx64-78798548d5-gn8kg 1/1 Running 0 3m 10.244.3.35 k8s-worker2
nginx65-79df496f67-thrfb 1/1 Running 0 3m 10.244.4.34 k8s-worker1
nginx66-6958544cb5-vkttn 1/1 Running 0 3m 10.244.3.36 k8s-worker2
nginx67-6cfc467f9f-794qv 1/1 Running 0 3m 10.244.3.37 k8s-worker2
nginx68-855d47fd69-2z4td 1/1 Running 0 3m 10.244.4.35 k8s-worker1
nginx69-7fff6d5959-lt8g6 1/1 Running 0 3m 10.244.4.36 k8s-worker1
nginx7-fb4f8974f-q4jlw 1/1 Running 0 4m 10.244.4.5 k8s-worker1
nginx70-c65668b7-lng8r 1/1 Running 0 3m 10.244.3.38 k8s-worker2
nginx71-686b468cf7-sfvbp 1/1 Running 0 3m 10.244.4.37 k8s-worker1
nginx72-86d8c9447f-wz559 1/1 Running 0 3m 10.244.3.39 k8s-worker2
nginx73-86fc88865-6zq6x 1/1 Running 0 3m 10.244.4.38 k8s-worker1
nginx74-7dd569ff-656qh 1/1 Running 0 3m 10.244.3.40 k8s-worker2
nginx75-78bfb56ddf-hgck6 1/1 Running 0 3m 10.244.4.39 k8s-worker1
nginx76-557c895f47-n4v4b 1/1 Running 0 3m 10.244.3.41 k8s-worker2
nginx77-795bfff5b9-s6xxv 1/1 Running 0 3m 10.244.4.40 k8s-worker1
nginx78-7877788cbc-pwxbk 1/1 Running 0 3m 10.244.3.42 k8s-worker2
nginx79-775668d5d9-xmqqh 1/1 Running 0 3m 10.244.4.41 k8s-worker1
nginx8-8f657d6df-4zqn5 1/1 Running 0 4m 10.244.4.6 k8s-worker1
nginx80-6cdcb96469-v752m 1/1 Running 0 3m 10.244.3.43 k8s-worker2
nginx81-66d8dcdd6c-5wgkp 1/1 Running 0 3m 10.244.4.42 k8s-worker1
nginx82-676bcf68d5-fnk94 1/1 Running 0 3m 10.244.3.44 k8s-worker2
nginx83-698f4dfd99-rqjm2 1/1 Running 0 3m 10.244.4.43 k8s-worker1
nginx84-649d56d469-bdcd5 1/1 Running 0 3m 10.244.3.45 k8s-worker2
nginx85-849d4f5dbc-92dxg 1/1 Running 0 3m 10.244.4.44 k8s-worker1
nginx86-69d9784589-xws9b 1/1 Running 0 3m 10.244.4.45 k8s-worker1
nginx87-67655554cf-pc2lt 1/1 Running 0 3m 10.244.4.46 k8s-worker1
nginx88-c5d86bd4f-4xp5j 1/1 Running 0 3m 10.244.3.46 k8s-worker2
nginx89-7ff879cd95-9n5vh 1/1 Running 0 3m 10.244.4.48 k8s-worker1
nginx9-78c466bd57-ltrb8 1/1 Running 0 4m 10.244.4.7 k8s-worker1
nginx90-68898fc895-mp4gn 1/1 Running 0 3m 10.244.3.47 k8s-worker2
nginx91-7c4f485785-vb9l8 1/1 Running 0 3m 10.244.4.47 k8s-worker1
nginx92-fbcc54495-rrjnz 1/1 Running 0 3m 10.244.3.48 k8s-worker2
nginx93-84cc9948df-h27jn 1/1 Running 0 3m 10.244.4.49 k8s-worker1
nginx94-f657d655-q9jd4 1/1 Running 0 3m 10.244.3.49 k8s-worker2
nginx95-7488d7b6f-xkjxr 1/1 Running 0 3m 10.244.4.50 k8s-worker1
nginx96-6555b5f77f-wpjrs 1/1 Running 0 3m 10.244.3.50 k8s-worker2
nginx97-5484785869-8njl7 1/1 Running 0 3m 10.244.4.51 k8s-worker1
nginx98-74bfc4b7b7-cgzlv 1/1 Running 0 3m 10.244.3.51 k8s-worker2
nginx99-5dc897865-jm9k9 1/1 Running 0 3m 10.244.4.52 k8s-worker1
- While master1 node is recovered, what will happed ? Power on master1
on master1 , Power-on this node
on master1,2,3 check which node the VIP is binding with.
[root@k8s-master3 ~]# journalctl -xeu keepalived-k8s|grep STATE
Nov 02 14:23:21 k8s-master3 Keepalived_vrrp[18733]: VRRP_Instance(VI_1) Entering BACKUP STATE
Nov 02 15:17:01 k8s-master3 Keepalived_vrrp[18733]: VRRP_Instance(VI_1) Transition to MASTER STATE
Nov 02 15:17:03 k8s-master3 Keepalived_vrrp[18733]: VRRP_Instance(VI_1) Entering MASTER STATE
Nov 02 16:18:03 k8s-master3 Keepalived_vrrp[18733]: VRRP_Instance(VI_1) Entering BACKUP STATE
[root@k8s-master2 ~]# journalctl -xeu keepalived-k8s|grep STATE
Nov 02 14:23:19 k8s-master2 Keepalived_vrrp[18062]: VRRP_Instance(VI_1) Entering BACKUP STATE
Nov 02 15:17:01 k8s-master2 Keepalived_vrrp[18062]: VRRP_Instance(VI_1) Transition to MASTER STATE
Nov 02 15:17:01 k8s-master2 Keepalived_vrrp[18062]: VRRP_Instance(VI_1) Entering BACKUP STATE
Nov 02 15:49:04 k8s-master2 Keepalived_vrrp[18062]: VRRP_Instance(VI_1) Transition to MASTER STATE
Nov 02 15:49:06 k8s-master2 Keepalived_vrrp[18062]: VRRP_Instance(VI_1) Entering MASTER STATE
Nov 02 15:49:13 k8s-master2 Keepalived_vrrp[18062]: VRRP_Instance(VI_1) Entering BACKUP STATE
[root@k8s-master1 ~]# journalctl -xeu keepalived-k8s|grep STATE
Nov 03 02:02:39 k8s-master1 Keepalived_vrrp[8837]: VRRP_Instance(VI_1) Transition to MASTER STATE
Nov 03 02:02:41 k8s-master1 Keepalived_vrrp[8837]: VRRP_Instance(VI_1) Entering MASTER STATE
[root@k8s-master1 ~]# ip a|grep $(cat /etc/keepalived/keepalived-k8s.conf|grep -A1 virtual_ipaddress|tail -1|sed -e 's/^ *//')
inet 10.53.44.110/32 scope global eno16777984
[root@k8s-node1 ~]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1.kubernates.com Ready,SchedulingDisabled master 17h v1.9.3
k8s-master2.kubernates.com Ready,SchedulingDisabled master 15h v1.9.3
k8s-master3.kubernates.com Ready,SchedulingDisabled master 15h v1.9.3
k8s-node1.kubernates.com Ready <none> 14h v1.9.3
k8s-node2.kubernates.com Ready <none> 14h v1.9.3
- master1 is power-off during pods are creating
on master1
Consider this - You can power-off master1 again during mass pods are still in creating status (e.g. 200 pods). See what will happened
# for ((i=101;i<=200;i++)); do kubectl run nginx$i --image=nginx --port=80; done
# poweroff
on master2 or 3
Some pods status are still in 'ContainerCreating', and try to get pods again until all pods status are in 'Running':
# kubectl get pods
default nginx181-666f6dbcd9-k99m7 0/1 ContainerCreating 0 2m <none> k8s-worker1
default nginx182-7596df954f-wmfvs 1/1 Running 0 2m 10.244.3.93 k8s-worker2
default nginx183-7fdd94b4d5-vc5q9 0/1 ContainerCreating 0 2m <none> k8s-worker1
default nginx184-56975d6465-vm5gp 1/1 Running 0 2m 10.244.3.94 k8s-worker2
default nginx185-5d984cf9b5-gtcbk 0/1 ContainerCreating 0 2m <none> k8s-worker1
default nginx186-7c6b5bfb65-rdns4 1/1 Running 0 2m 10.244.3.95 k8s-worker2
default nginx187-796c98d9c-cjqxp 0/1 ContainerCreating 0 2m <none> k8s-worker1
default nginx188-c6f7c959c-wq6rw 1/1 Running 0 2m 10.244.3.96 k8s-worker2
default nginx189-6c74cf45cc-mlhhg 0/1 ContainerCreating 0 2m <none> k8s-worker1
default nginx19-6bcdb9c6b5-ccc7l 1/1 Running 0 49m 10.244.3.13 k8s-worker2
default nginx190-5d9d5fc8b9-ck4zk 1/1 Running 0 2m 10.244.3.97 k8s-worker2
default nginx191-66586bdb69-nrr5d 0/1 ContainerCreating 0 2m <none> k8s-worker1
default nginx192-7696889fd5-rfpb8 1/1 Running 0 2m 10.244.3.98 k8s-worker2
default nginx193-6b9dbc65fc-tq7p8 0/1 ContainerCreating 0 2m <none> k8s-worker1
default nginx194-5459df6b5c-44d95 1/1 Running 0 2m 10.244.3.99 k8s-worker2
default nginx195-6565859485-xvt52 0/1 ContainerCreating 0 2m <none> k8s-worker1
default nginx196-86d45f8865-q4zcs 0/1 ContainerCreating 0 2m <none> k8s-worker2
default nginx197-7ff7f67f5c-t8htk 0/1 ContainerCreating 0 2m <none> k8s-worker1
default nginx198-6cbf78cdb9-z8w62 0/1 ContainerCreating 0 2m <none> k8s-worker2
default nginx199-779d6654df-znkdj 0/1 ContainerCreating 0 2m <none> k8s-worker1
default nginx2-7895f859bf-z6s7c 1/1 Running 0 2h 10.244.4.4 k8s-worker1
default nginx20-846f6897f7-nt5t9 1/1 Running 0 49m 10.244.3.14 k8s-worker2
default nginx200-6f786654df-g8xdq 0/1 ContainerCreating 0 2m <none> k8s-worker2
default nginx21-6c9cb64c67-sx82j 1/1 Running 0 49m 10.244.4.11 k8s-worker1
default nginx22-5b595b8789-dlft6 1/1 Running 0 49m 10.244.4.12 k8s-worker1
**Validation Completed!**