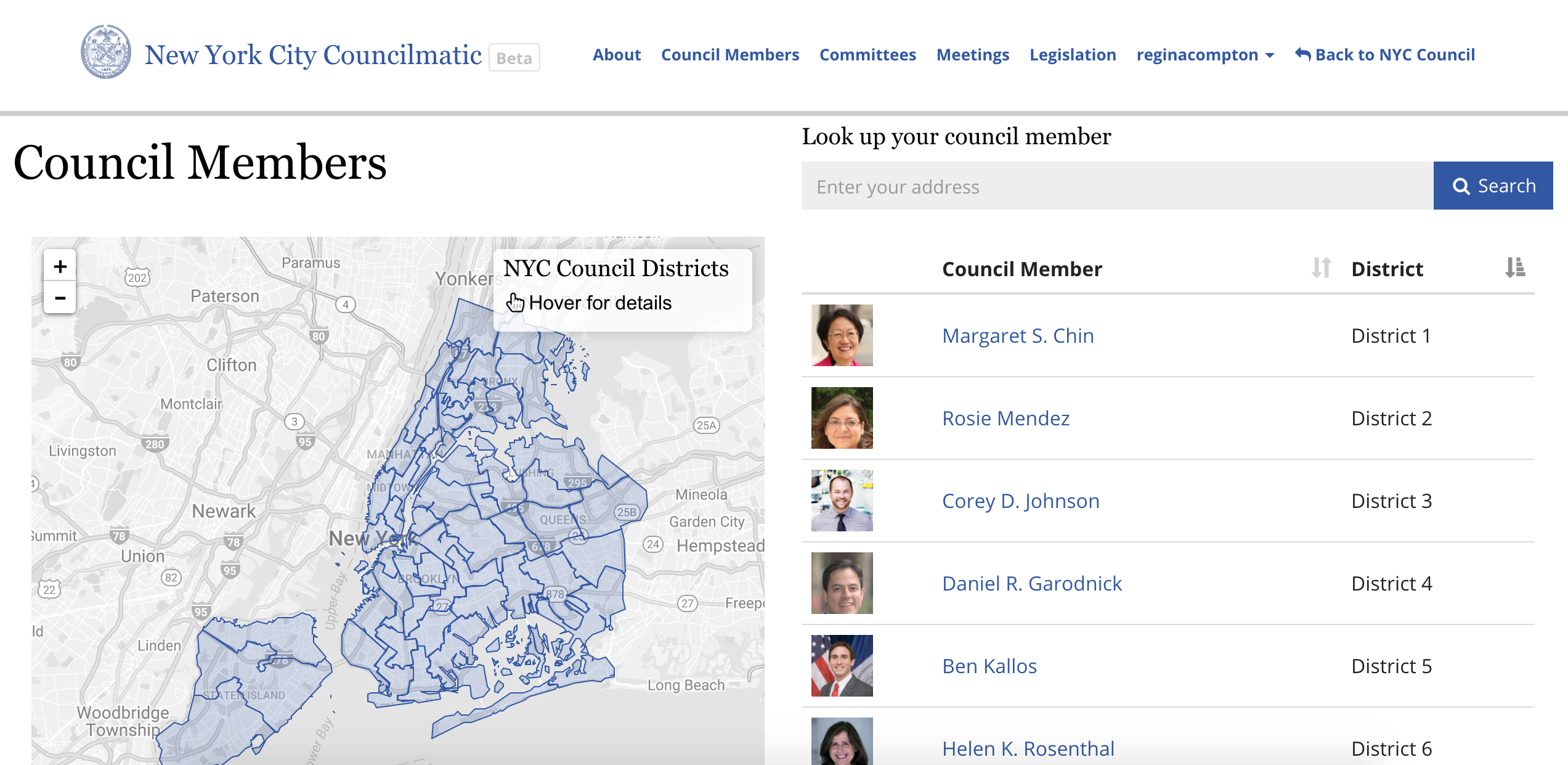
NYC Councilmatic is a tool for understanding and tracking what’s happening in New York City Council.
This site connects NYC residents to local city council offices, for greater online public dialogue about issues in their communities.
Councilmatic helps you:
- Keep up with what your local representatives is up to
- See the schedule of public events
- Track and comment on issues you care about
NYC Councilmatic is free, non-profit, and non-partisan and the easiest way to access official New York City Council information.
Part of the Councilmatic family.
Install OS level dependencies:
- Python 3.4
- PostgreSQL 9.4 +
Install app requirements
We recommend using virtualenv and virtualenvwrapper for working in a virtualized development environment. Read how to set up virtualenv.
Once you have virtualenvwrapper set up,
mkvirtualenv nyc-councilmatic
git clone https://github.com/datamade/nyc-councilmatic.git
cd nyc-councilmatic
pip install -r requirements.txtAfterwards, whenever you want to use this virtual environment to work on nyc-councilmatic, run workon nyc-councilmatic
Create your settings file
cp councilmatic/settings_deployment.py.example councilmatic/settings_deployment.pyThen edit councilmatic/settings_deployment.py:
USERshould be your username
Setup your database
Before we can run the website, we need to create a database.
createdb nyc_councilmaticThen, run migrations
python manage.py migrate --no-initial-dataCreate an admin user - set a username & password when prompted
python manage.py createsuperuserRun the loaddata management command. This will take a while, depending on volume (probably around half an hour ish for NYC)
python manage.py loaddataBy default, the loaddata command is smart about what it looks at on the OCD API. If you already have bills loaded, it won't look at everything on the API - it'll look at the most recently updated bill in your database, see when that bill was last updated on the OCD API, & then look through everything on the API that was updated after that point. If you'd like to load things that are older than what you currently have loaded, you can run the loaddata management command with a --delete option, which removes everything from your database before loading.
The loaddata command has some more nuance than the description above, for the different types of data it loads. If you have any questions, open up an issue and pester us to write better documentation.
python manage.py runservernavigate to http://localhost:8000/
Install Open JDK or update Java
On Ubuntu:
$ sudo apt-get update
$ sudo apt-get install openjdk-7-jre-headlessOn OS X:
-
Download latest Java from http://java.com/en/download/mac_download.jsp?locale=en
-
Follow normal install procedure
-
Change system Java to use the version you just installed:
sudo mv /usr/bin/java /usr/bin/java16 sudo ln -s /Library/Internet\ Plug-Ins/JavaAppletPlugin.plugin/Contents/Home/bin/java /usr/bin/java
Download & setup Solr
wget http://mirror.sdunix.com/apache/lucene/solr/4.10.4/solr-4.10.4.tgz
tar -xvf solr-4.10.4.tgz
sudo cp -R solr-4.10.4/example /opt/solr
# Copy schema.xml for this app to solr directory
sudo cp solr_scripts/schema.xml /opt/solr/solr/collection1/conf/schema.xmlRun Solr
# Next, start the java application that runs solr
# Do this in another terminal window & keep it running
# If you see error output, somethings wrong
cd /opt/solr
sudo java -jar start.jarIndex the database
# back in the nyc-councilmatic directory:
python manage.py rebuild_indexOPTIONAL: Install and configure Jetty for Solr
Just running Solr as described above is probably OK in a development setting. To deploy Solr in production, you'll want to use something like Jetty. Here's how you'd do that on Ubuntu:
sudo apt-get install jetty
# Backup stock init.d script
sudo mv /etc/init.d/jetty ~/jetty.orig
# Get init.d script suggested by Solr docs
sudo cp solr_scripts/jetty.sh /etc/init.d/jetty
sudo chown root.root /etc/init.d/jetty
sudo chmod 755 /etc/init.d/jetty
# Add Solr specific configs to /etc/default/jetty
sudo cp solr_scripts/jetty.conf /etc/default/jetty
# Change ownership of the Solr directory so Jetty can get at it
sudo chown -R jetty.jetty /opt/solr
# Start up Solr
sudo service jetty start
# Solr should now be running on port 8983Regenerate Solr schema
While developing, if you need to make changes to the fields that are getting indexed or how they are getting indexed, you'll need to regenerate the schema.xml file that Solr uses to make it's magic. Here's how that works:
python manage.py build_solr_schema > solr_scripts/schema.xml
cp solr_scripts/schema.xml /opt/solr/solr/collection1/conf/schema.xml
In order for Solr to use the new schema file, you'll need to restart it.
Using Solr for more than one Councilmatic on the same server
If you intend to run more than one instance of Councilmatic on the same server, you'll need to take a look at this README to make sure you're configuring things properly.
- David Moore, Participatory Politics Foundation - project manager
- Forest Gregg, DataMade - Open Civic Data (OCD) and Legistar scraping
- Cathy Deng, DataMade - data models, front end
- Derek Eder, DataMade - front end
- Eric van Zanten, DataMade - search and dev ops
- Regina Compton, DataMade - developer
If something is not behaving intuitively, it is a bug, and should be reported. Report it here: https://github.com/datamade/nyc-councilmatic/issues
- Fork the project.
- Make your feature addition or bug fix.
- Commit, do not mess with rakefile, version, or history.
- Send a pull request. Bonus points for topic branches.
Copyright (c) 2015 Participatory Politics Foundation and DataMade. Released under the MIT License.