4.1 爬虫转换器
之所以要先介绍这一部分,因为Hawk的核心定位是爬虫,因此数据清洗首先是为了爬虫服务的。本节首先介绍爬虫中使用的转换器,是数据清洗中最重要的模块。因此我们对其专门进行讨论。
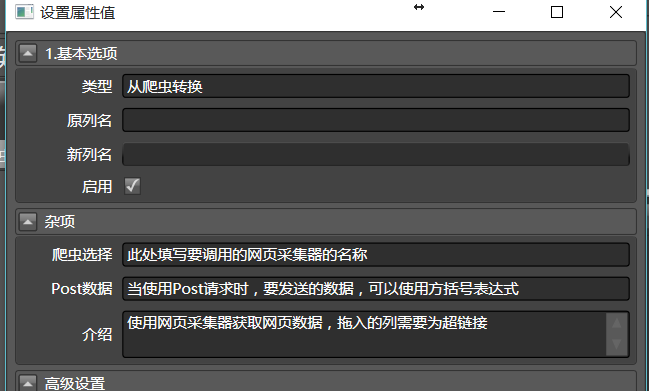
一般情况下, 将从爬虫转换拖入到对应的URL列中,通过下拉菜单选择要调用的爬虫名称,即可完成所有的配置:
它是沟通网页采集器和数据清洗的桥梁。本质上说,网页采集器是针对获取网页而特别定制的数据清洗模块。
你需要填写爬虫选择,告诉它要调用哪个采集器。早期版本的HawK,会默认选择在算法模块的第一个网页采集器,但实践证明这样会导致问题,后来就取消了功能。
重试次数和错误后延时时间(单位为毫秒),可以指定采集器在发生失败时的行为。不过,网站一旦封锁,即使重试可能也不会带来什么效果。
而任务队列卷展栏的内容,可以让网页采集器抓取的内容插入到任务队列中,从而执行后续抓取。这能够构造出广度优先遍历抓取,但是,Hawk的这项功能是不完备的。不建议除了设计者本人的其他任何人使用(那你说个屁啊)。
我们重点介绍如何实现Post请求。
web请求中,有两种主要的请求类型,分别是post和get。一般默认都是get。用post的情况,能支持传输更多的数据。更多的细节,可以参考http协议的相关文档,网上汗牛充栋,这里就不多说了。
post请求时,给服务器需要传递两个参数:url 和post。一般来说,在执行post请求时,url是稳定的,post值是动态改变的。
首先要配置调用的网页采集器为post模式(打开网页采集器,请求详情,模式下拉菜单)。
之后,需要将从爬虫转换拖到要调用的url列上。如果没有url列,可以通过添加新列,生成一个url列。
之后,我们要将post数据传递到网页采集器中。你总是可以通过合并多列拼接或各种手段,生成要Post的数据列。之后,可以在从爬虫转换中的post数据中,填写[post列], 而post列就是包含post数据的列名。
post当然要比get麻烦一点点啦,但也没有麻烦多少。
当输入的单元格内容为html文档,而又想提取其部分数据,用网页采集器又杀鸡用牛刀过重,则可以考虑使用它。Hawk3中,本转换器还能支持
XPath语法可参考网上其他教程。选择List模式,则处在UDAF模式, 如果不勾选,则只会提取满足条件的第一个数据。
- 路径: 可编写XPath或CSS选择器的路径
- 选择器: 选择是XPath或CSS模式
当页面包含HTML时,一些字符可能已经被转义了,例如空格成了nsbp%
,就需要HTML字符转义,拖入到对应的列,将其解码,当然也可以编码。
URL字符转义也是一样的道理,只是会将其转换为URL编码。C#的HttpClient比python更加智能,默认对带特殊符号和中文的URL进行编码,所以这个模块用的并不多。
//怎么写?