Update GPU docs #5515
Update GPU docs #5515
Conversation
Signed-off-by: davidmirror-ops <[email protected]>
Signed-off-by: davidmirror-ops <[email protected]>
Signed-off-by: davidmirror-ops <[email protected]>
Signed-off-by: davidmirror-ops <[email protected]>
Codecov ReportAll modified and coverable lines are covered by tests ✅
Additional details and impacted files@@ Coverage Diff @@
## master #5515 +/- ##
===========================================
- Coverage 61.00% 35.91% -25.10%
===========================================
Files 793 1301 +508
Lines 51378 109401 +58023
===========================================
+ Hits 31342 39287 +7945
- Misses 17149 66017 +48868
- Partials 2887 4097 +1210
Flags with carried forward coverage won't be shown. Click here to find out more. ☔ View full report in Codecov by Sentry. |
Signed-off-by: davidmirror-ops <[email protected]>
Signed-off-by: davidmirror-ops <[email protected]>
Signed-off-by: davidmirror-ops <[email protected]>
| image = ImageSpec( | ||
| base_image= "ghcr.io/flyteorg/flytekit:py3.10-1.10.2", | ||
| name="pytorch", | ||
| python_version="3.10", | ||
| packages=["torch"], | ||
| builder="envd", | ||
| registry="<YOUR_CONTAINER_REGISTRY>", | ||
| ) |
There was a problem hiding this comment.
I do not think this this works with the envd image builder. This should work tho:
image = ImageSpec(
name="pytorch",
python_version="3.10",
packages=["torch"],
builder="default",
registry=...
)| ```yaml | ||
| tolerations: nvidia.com/gpu:NoSchedule op=Exists | ||
| ``` | ||
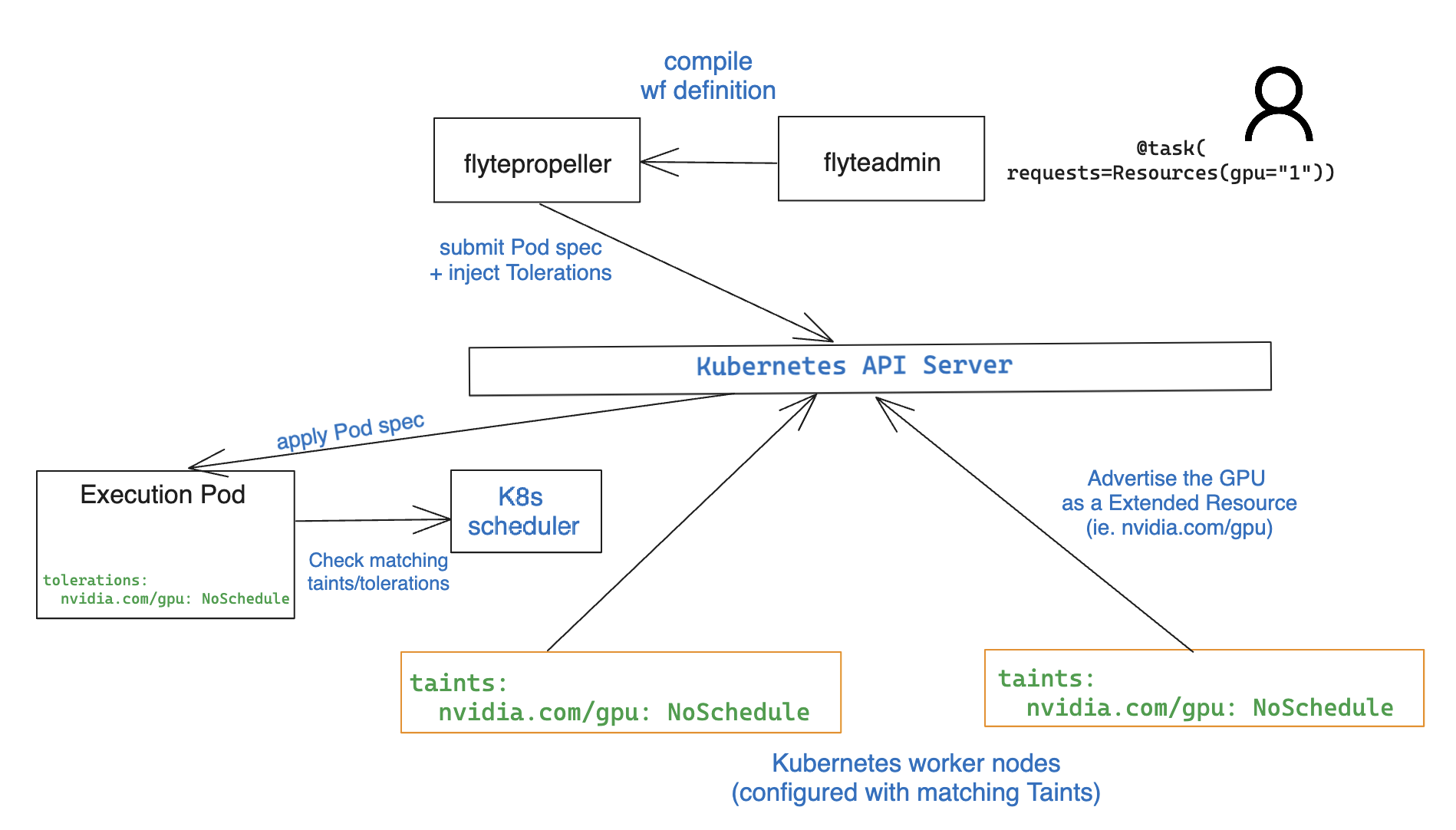
| The Kubernetes scheduler will admit the pod if there are worker nodes in the cluster with a matching taint and available resources. |
There was a problem hiding this comment.
When accelerator is not specified and there are multiple GPUs accelerator types configured, how does Kubernetes decide which accelerator to use?
There was a problem hiding this comment.
Great question. Currently K8s uses 3rd-party Device Driver plugins that advertise Extended Resources (this is, things other than CPU and memory) to the kubelet. In the case of NVIDIA, their GPU operator implements this approach using a DaemonSet that communicates with the K8s scheduler to let it know which devices are available. While it works, it's not great because there's a lot of coordination required between the K8s scheduler and this external driver, no good management of "distributed locking" for shared resources, and in consequence, Pods can be scheduled to a node but left in Pending state bc one of those Extended Resources is not ready.
This is changing with the introduction of Dynamic Resource Allocation (soon to be in beta on K8s 1.31)
I just added a brief note about this but let me know if you think a better explanation is needed.
|
|
||
| You can also configure Flyte backend to apply specific tolerations. This configuration is controlled under generic k8s plugin configuration as can be found [here](https://github.com/flyteorg/flyteplugins/blob/5a00b19d88b93f9636410a41f81a73356a711482/go/tasks/pluginmachinery/flytek8s/config/config.go#L120). | ||
| >The examples in this section use [ImageSpec](https://docs.flyte.org/en/latest/user_guide/customizing_dependencies/imagespec.html#imagespec), a Flyte feature that builds a custom container image without a Dockerfile. Install it using `pip install flytekitplugins-envd`. |
There was a problem hiding this comment.
| >The examples in this section use [ImageSpec](https://docs.flyte.org/en/latest/user_guide/customizing_dependencies/imagespec.html#imagespec), a Flyte feature that builds a custom container image without a Dockerfile. Install it using `pip install flytekitplugins-envd`. | |
| The examples in this section use [ImageSpec](https://docs.flyte.org/en/latest/user_guide/customizing_dependencies/imagespec.html#imagespec), a Flyte feature that builds a custom container image without a Dockerfile. Install it using `pip install flytekitplugins-envd`. |
| adds the matching toleration for that resource (in this case, `gpu`) to the generated PodSpec. | ||
| As it follows here, you can configure it to access specific resources using the tolerations for all resources supported by | ||
| Kubernetes. | ||
| ## Requesting a GPU with no preference for device |
There was a problem hiding this comment.
| ## Requesting a GPU with no preference for device | |
| ## Requesting a GPU with no device preference |
| As it follows here, you can configure it to access specific resources using the tolerations for all resources supported by | ||
| Kubernetes. | ||
| ## Requesting a GPU with no preference for device | ||
| The goal in this example is to run the task on a single available GPU : |
There was a problem hiding this comment.
| The goal in this example is to run the task on a single available GPU : | |
| In this example, we run a task on a single available GPU: |
| def gpu_available() -> bool: | ||
| return torch.cuda.is_available() # returns True if CUDA (provided by a GPU) is available | ||
| ``` | ||
| ### How it works? |
There was a problem hiding this comment.
| ### How it works? | |
| ### How it works |
|
|
||
|  | ||
|
|
||
| When this task is evaluated, `flyteproller` injects a [toleration](https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/) in the pod spec: |
There was a problem hiding this comment.
| When this task is evaluated, `flyteproller` injects a [toleration](https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/) in the pod spec: | |
| When this task is evaluated, `flytepropeller` injects a [toleration](https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/) in the pod spec: |
There was a problem hiding this comment.
oh my , good catch, thanks!
| return torch.cuda.is_available() | ||
| ``` | ||
|
|
||
| #### How it works? |
There was a problem hiding this comment.
| #### How it works? | |
| #### How it works |
|
|
||
|
|
||
| ### Request an unpartitioned A100 device | ||
| The goal is to run the task using the resources of the entire A100 GPU: |
There was a problem hiding this comment.
| The goal is to run the task using the resources of the entire A100 GPU: | |
| In the following example, we run a task using the resources of the entire A100 GPU: |
| return torch.cuda.is_available() | ||
| ``` | ||
|
|
||
| #### How it works? |
There was a problem hiding this comment.
| #### How it works? | |
| #### How it works |
|
|
||
| #### How it works? | ||
|
|
||
| When this task is evaluated `flytepropeller` injects a node selector expression that only matches nodes where the label specifying a partition size is **not** present: |
There was a problem hiding this comment.
| When this task is evaluated `flytepropeller` injects a node selector expression that only matches nodes where the label specifying a partition size is **not** present: | |
| When this task is evaluated, `flytepropeller` injects a node selector expression that only matches nodes where the label specifying a partition size is **not** present: |
| ``` | ||
|
|
||
|
|
||
| Scheduling can be further controlled by setting in the Helm chart a toleration that `flytepropeller` injects into the task pods: |
There was a problem hiding this comment.
| Scheduling can be further controlled by setting in the Helm chart a toleration that `flytepropeller` injects into the task pods: | |
| Scheduling can be further controlled by setting a toleration in the Helm chart that `flytepropeller` injects into the task pods: |
There was a problem hiding this comment.
Maybe it's because English is not my native tongue :) but I read the suggestion as if it's the Helm chart that is injected
There was a problem hiding this comment.
Oh, I see what you mean -- you can disregard my suggestion, then, the original text is much clearer!
Signed-off-by: davidmirror-ops <[email protected]>
Signed-off-by: davidmirror-ops <[email protected]>
Signed-off-by: davidmirror-ops <[email protected]>
* Introduce 3 levels Signed-off-by: davidmirror-ops <[email protected]> * Fix ImageSpec config Signed-off-by: davidmirror-ops <[email protected]> * Rephrase 1st section and prereqs Signed-off-by: davidmirror-ops <[email protected]> * Expand 2nd section up to nodeSelector key Signed-off-by: davidmirror-ops <[email protected]> * Add partition scheduling info Signed-off-by: davidmirror-ops <[email protected]> * Reorganize instructions Signed-off-by: davidmirror-ops <[email protected]> * Improve clarity Signed-off-by: davidmirror-ops <[email protected]> * Apply reviews pt1 Signed-off-by: davidmirror-ops <[email protected]> * Add note on default scheduling behavior Signed-off-by: davidmirror-ops <[email protected]> * Add missing YAML and rephrase full A100 behavior Signed-off-by: davidmirror-ops <[email protected]> --------- Signed-off-by: davidmirror-ops <[email protected]> Signed-off-by: Vladyslav Libov <[email protected]>
The purpose is to bring the information contained in the original flytekit accelerators PR (#4172) and complement with learnings from testing the feature on a live environment with access to GPU devices.
The "How it works" section for each use case, should speak to the platform engineers tasked with preparing the infrastructure so Flyte users can request accelerators from Python decorators.
How was this patch tested?
Tested on AKS using both V100 and A100 GPUs.
Setup process
Screenshots
Check all the applicable boxes
Related PRs
Docs link