The purpose of this project to build a web scraping script to obtain 100 pages of books (2000 books) related to Computer Science, and to do a statistical test to see does the number of pages lead to a higher average rating.
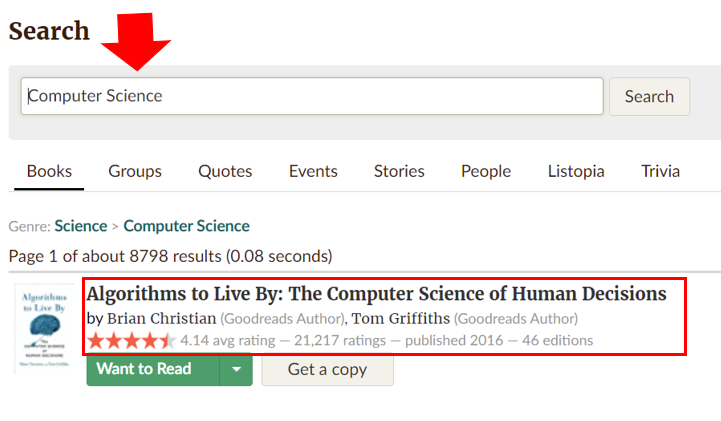
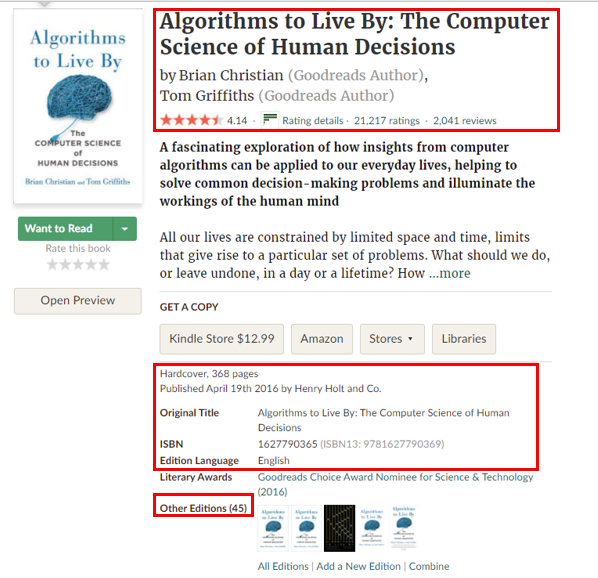
The dataset is obtained from Goodreads under the search bar page. We will be using the search bar to search books for Computer Science. The search pages only extended to 100 pages, which contains 2000 books of information (1 search page contains 20 books). Each book has a personalized web link that allows users to click in to check for book information. Each book must have a title, and may or may not have the following information:
- Book title (Must Have)
- Author
- Average rating
- Rating count
- Review count
- Number of Page
- Format
- Languages
- First Publish Year
- Editions
- ISBN
- Link
We will be using MongoDB to store our data during the Web Scraping process. That allows us to do Exploratory Data Analysis simultaneously without the Web Scraping process is complete.
As a result, you will need to install Docker, Docker Compose, and register a Docker Hub account. Then, we will pull the MongoDB image using Docker. Inside your terminal, you should already able to run Docker Hello World, then you should run the following command to pull MongoDB:
- Using Mongo:
$ docker run --name mongoserver -p 27017:27017 -v "$PWD":/Your-Working-Directory -d mongo
- Starting Mongo
$ docker start mongoserver
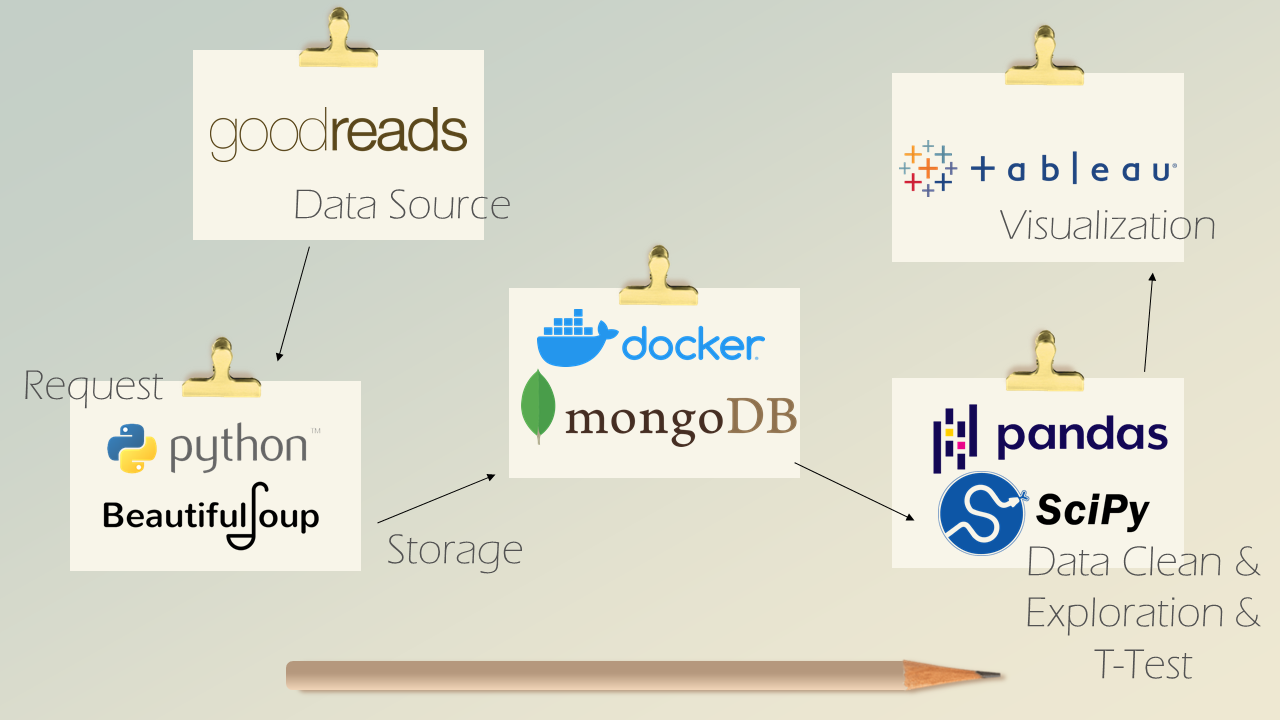
We will have two seperate juypter notebook, one for web scraping purpose call Goodreads Web Scraping Notebook.ipynb, and another is for EDA & Statistical Tests purpose callGoodreads Exploratory Data Analysis & Statistical Tests.ipynb.
You will need to:
- search a genre you interested in
- click on the second page to obtain the url link
- replace the link of the search bar page in the jupyter notebook
For example:
- Page 1/Default Search Bar Page: https://www.goodreads.com/search?utf8=%E2%9C%93&q=Computer+Science&search_type=books
- Page 2: https://www.goodreads.com/search?page=2&q=Computer+Science&qid=A44Zff48B9&search_type=books&tab=books&utf8=%E2%9C%93
We noticed that the default, page 1, does not contain the number of pages page=2&q=Computer+Science. As a result, you will need to start on Page 2, copy the URL inside the for loop.
We can do simple EDA while the web scraping is still spinning and understand our dataset in advance. After all data (books) are being collected and stored in our MongoDB, then we can do statistical tests to answer our question.
Always remember to create a MongoDB first to store your data in Part 1.
client = MongoClient('localhost', 27017)
db = client['book']
book_info = db['book_info']
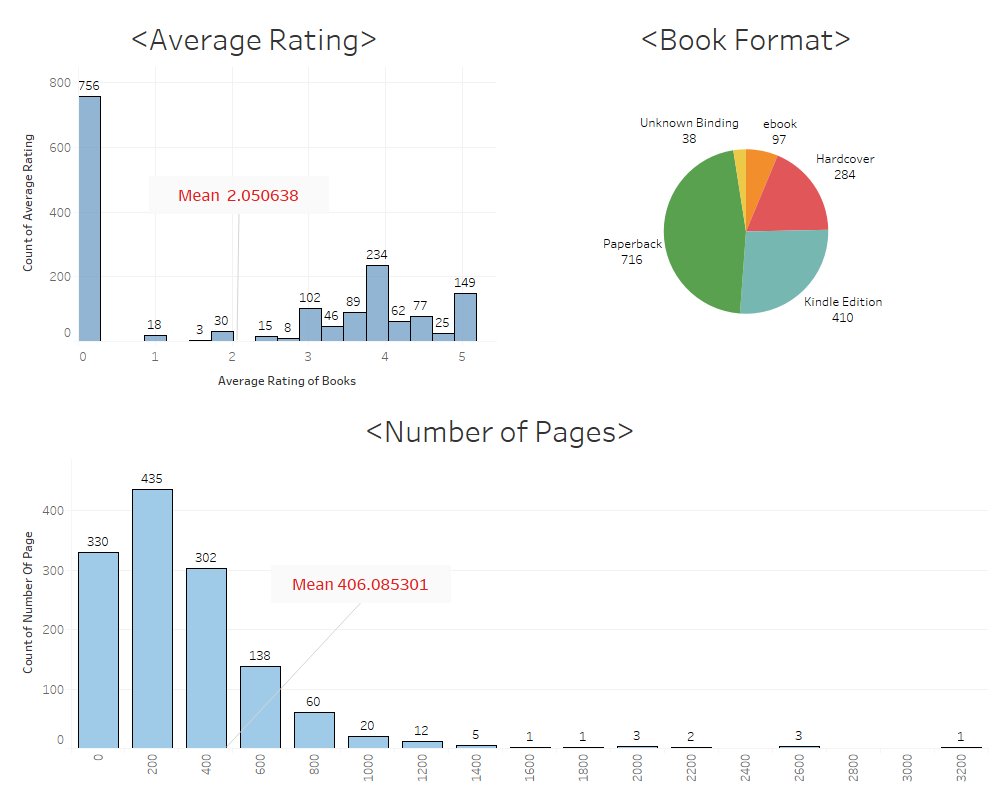
Not only answering our original question - Does the number of pages lead to a higher average rating? I further expand that to other aspects
- Average Rating (No signifcant difference between Books with longer number of pages of short number of number of pages)
- Review Count (No significant difference)
- Number of Book Editions (No significant difference)
- Rating Count (sigificant difference acorrding to the test!)

- A book with more pages DOES tend to be rated more often according to the Statistical T-Tests.
- A Book has long number of pages DOES NOT lead to a higher Average Rating, Reviews Count, and Editions according to the Statistical T-Tests.