For this project, we are tasked with provisioning a few Lambda functions to generate near real time finance data records for downstream processing and interactive querying.
This project consists of three major infrastructure elements that work in tandem:
- A lambda function that collects our data (DataCollector)
- A lambda function that transforms and places data into S3 (DataTransformer)
- A serverless process that allows us to query our s3 data (DataAnalyzer)
AWS Firehose -> AWS Lambda Functions -> Docker Deployment Package -> AWS Glue -> AWS Athena -> Jupyter Notebook Analysis
- Setup Kinesis Firehose Delivery Stream with Lambda Function. It will transform our record and streams it into an S3 bucket. (DataTransformer)
- Setup Another Lambda Function, triggered from a simple URL call. On trigger, it will grab stock price data and place it into the delivery defined in the DataTransformer. (DataCollector)
- Configure AWS Glue, pointing it to the AWS S3 Bucket we created in our DataTransformer.
- Using AWS Athena to interactively query the S3 files generated by the DataTransformer to gain insight into our streamed data. (DataAnaylzer)
Data Collector Lambda Function URL:
https://eb9iumoz0b.execute-api.us-east-2.amazonaws.com/default/STA9760-project3-data-collector
Configuration Page
We can use docker to install necessary packges where we don't have to install the yfinance module via subprocess. We can actually create our dependency package via docker.
In order to run lambda functions that also manage dependencies, we must leverage a "deployment package", basically a zip file containing our lambda code and all the dependencies it needs all packaged into a single artifact. For more details we can find it here.
STA9760 Simple Deployment Package By Professor Taq
After we have created our deployment packages, we can simply upload the file to AWS Lambda Function and create a test to test if the function can be executed successfully. If it does, data will be generated and pushed to the AWS S3 bucket.
Stream Monitoring
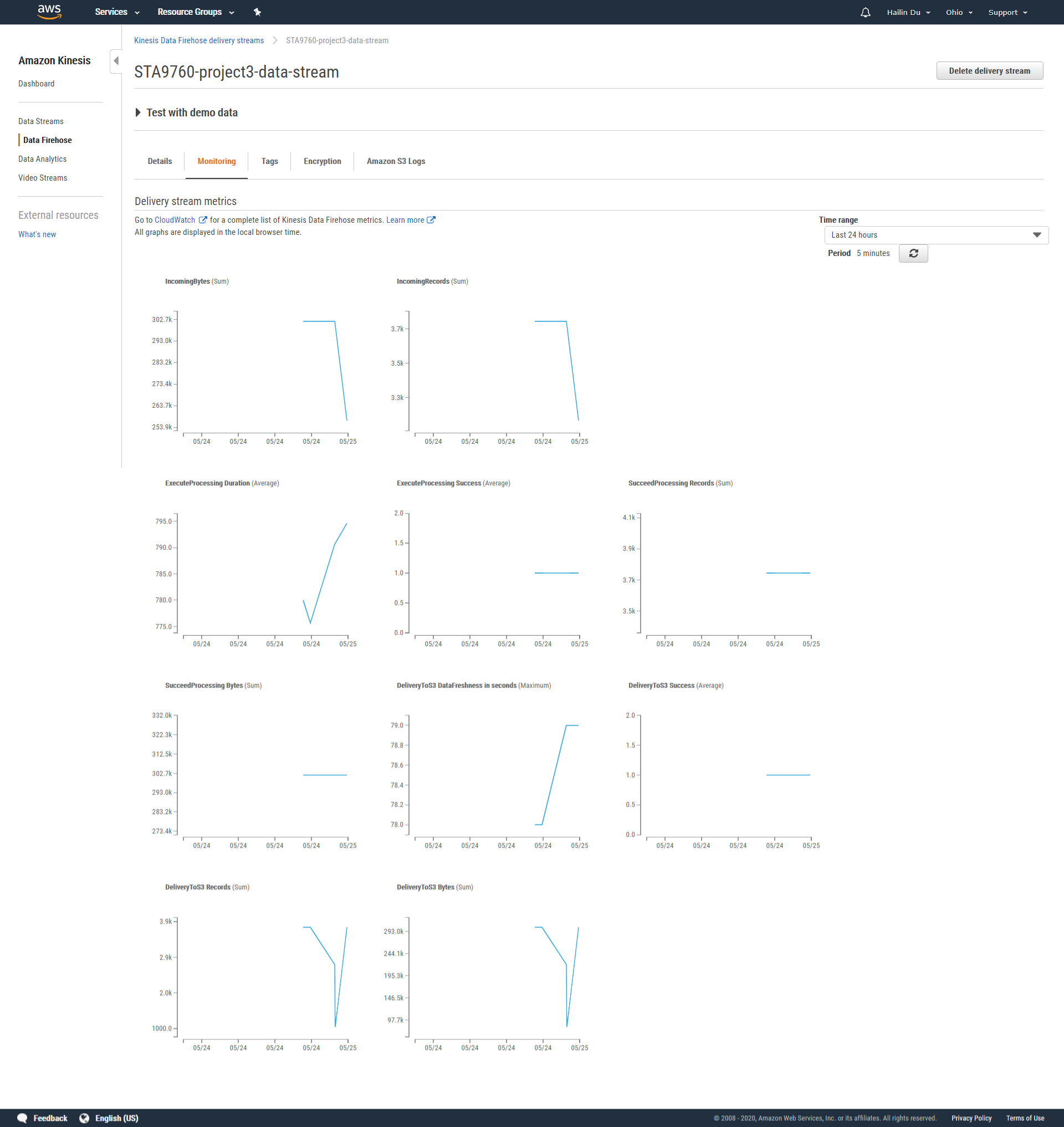
We will then configure AWS Glue, pointing it to the S3 Bucket we created in our DataTransformer. This will allow us to now interactively query the S3 files generated by the DataTransformer using AWS Athena to gain insight into our streamed data. This process is also known as DataAnalyzer.
After we have generated our output, we can download the CSV file. Then, we can upload the file to Jupyter Notebook, using Python packages to create data visualizations.