-
Hanhan_Data_Science_Resource 1: https://github.com/hanhanwu/Hanhan_Data_Science_Resources
-
Check Awesome Big Data when looking for new ways to solve data science problems: https://github.com/onurakpolat/awesome-bigdata
-
Categorized Resources for Machine Learning: https://www.analyticsvidhya.com/resources-machine-learning-deep-learning-neural-networks/
-
Summarized Tableau Learning Resources: https://www.analyticsvidhya.com/learning-paths-data-science-business-analytics-business-intelligence-big-data/tableau-learning-path/
-
Summarized Big Data Learning Resources: https://www.analyticsvidhya.com/resources-big-data/
-
Data Science Media Resources: https://www.analyticsvidhya.com/data-science-blogs-communities-books-podcasts-newsletters-follow/
-
This is a new UC Berkeley data science cousre, it serves for undergraduate and therefore everything is introductory, however it covers relative statistics, math, data visualization, I think it will be helpful, since sometimes if we only study statistics may still have difficulty to apply the knowledge in data science. This program has slides and video for each class online, available to the public immeddiately: http://www.ds100.org/sp17/
-
Microsoft DMTK (Distributed Machine Learning Toolkit)
- Official Website: http://www.dmtk.io/
- GitGub: https://github.com/Microsoft/DMTK
- Currently, they have:
- DMTK framework(Multiverso): The parameter server framework for distributed machine learning.
- LightLDA: Scalable, fast and lightweight system for large-scale topic modeling.
- LightGBM: LightGBM is a fast, distributed, high performance gradient boosting (GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
- Distributed word embedding: Distributed algorithm for word embedding implemented on multiverso.
- LightGBM
- What I am interested in is to run machine learning algorithms with GPU
- Features (include GPU tutorials): https://github.com/Microsoft/LightGBM/wiki/Features
- Experiment Results: https://github.com/Microsoft/LightGBM/wiki/Experiments#comparison-experiment
- GitHub: https://github.com/Microsoft/LightGBM/tree/d65f87b6f8c172ed441b1ad2a7bd83bd3268d447
- Installation Guide: https://github.com/Microsoft/LightGBM/wiki/Installation-Guide
- Params: https://lightgbm.readthedocs.io/en/latest/Parameters.html
- NOTE: after running above intallation commands successfully, type
cd LightGBM/python-package, then typepython setup.py install(for Python2.7),python3.5 setup.py install(for python3.5) - Parallel Learning Guide: https://github.com/Microsoft/LightGBM/wiki/Parallel-Learning-Guide
-
Google Tensorflow
- It seems that, it is not someting just for deep learning. You can do both deep learning and other machine learning here
- Tensorflow Paper: http://download.tensorflow.org/paper/whitepaper2015.pdf
- “TensorFlow is an open source software library for numerical computation using dataflow graphs. Nodes in the graph represents mathematical operations, while graph edges represent multi-dimensional data arrays (aka tensors) communicated between them. The flexible architecture allows you to deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device with a single API.”
- TensorFlow follows a lazy programming paradigm. It first builds a graph of all the operation to be done, and then when a “session” is called, it “runs” the graph. Building a computational graph can be considered as the main ingredient of TensorFlow.
- Tensorflow Playground
- It's showing you what does NN look like while it's training the data, and you can tune some params
- I really love this idea, because it's showing not only creativity but also passion! Data Science is an area that is full of passion!
- Tensorflow ecosystem: https://github.com/tensorflow
- Install: https://www.tensorflow.org/install/install_mac
- TensorBoard, the visualization and debug tool: https://www.tensorflow.org/get_started/summaries_and_tensorboard
- A basic introduction to TensorBoard (the author forgot to normalize the data before NN training, but anyway, he found TensorBorad to help): https://www.analyticsvidhya.com/blog/2017/07/debugging-neural-network-with-tensorboard/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
Summarized From Others
- 16 data science repositories (these may contain more statistical analysis, so it's good to learn): http://www.analyticbridge.datasciencecentral.com/profiles/blogs/16-data-science-repositories
- 21 articles about time series: http://www.datasciencecentral.com/profiles/blogs/21-great-articles-and-tutorials-on-time-series
- 13 articles about correlation: http://www.datasciencecentral.com/profiles/blogs/13-great-articles-and-tutorials-about-correlation
- 10 articles about outliers: http://www.datasciencecentral.com/profiles/blogs/11-articles-and-tutorials-about-outliers
- 14 articles clustering: http://www.datasciencecentral.com/profiles/blogs/14-great-articles-and-tutorials-on-clustering
- Hacks, tips for image, data manipulation
- Also include image manipulation
- There is a parallel method for pandas
apply. Although I think using list maybe still faster than using pandas apply.
- For more ensembling, check
ENSEMBLEsections and Experiences.md here: https://github.com/hanhanwu/Hanhan_Data_Science_Resources - Tree based models in detail with R & Python example: https://www.analyticsvidhya.com/blog/2016/04/complete-tutorial-tree-based-modeling-scratch-in-python/?utm_content=bufferade26&utm_medium=social&utm_source=facebook.com&utm_campaign=buffer
- [R Implementation] Choose models for ensemling: https://www.analyticsvidhya.com/blog/2015/10/trick-right-model-ensemble/?utm_content=buffer6b42d&utm_medium=social&utm_source=plus.google.com&utm_campaign=buffer
- The models are less correlated to each other.
- The code in this tutorial is trying to test the results made by multiple models and choose the model combination that gets the best result.
- When a categorical variable has very large number of categories, Gain Ratio is preferred over Information Gain.
- Won't be affected by the curse of dimentionality, because distance metric is not used in them.
- Reference: https://www.analyticsvidhya.com/blog/2017/06/which-algorithm-takes-the-crown-light-gbm-vs-xgboost/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Leaf-wise - Optimization in Accuracy: Other boosting algorithms use depth-wise or level-wise, while Light BGM is using leaf-wise. With this method, Light GBM becomes more complexity and has less info loss and therefore can be more accurate than other boosting methods.
- Sometimes, overfitting could happen, check LightGBM Parameter tuning here: https://lightgbm.readthedocs.io/en/latest/Parameters-Tuning.html
- Suggestions for faster speed.
- Suggestions for better accuracy.
- Suggestions for dealing with overfitting.
- Using Histogram Based Algorithms
- Many boosting tools as using pre-sorted based algorithms (default XGBoost algorithm) for decision tree learning, which makes optimization more difficult.
- LightGBM uses the histogram based algorithms, which bucketing continuous features into discrete bins, to speed up training procedure and reduce memory usage.
- Reduce Calculation Cost of Split Gain: pre-sorted based cost O(#data) to calculate; histogram based needs O(#data) to construcu histogram but O(#bins) to calculate Split Gain. #bins often smaller than #data, and this is why if you tune #bins to a smaller number, it will speed up the algorithm.
- Use histogram subtraction for further speed-up: To get one leaf's histograms in a binary tree, can use the histogram subtraction of its parent and its neighbor, only needs to construct histograms for one leaf (with smaller #data than its neighbor), then can get histograms of its neighbor by histogram subtraction with small cost( O(#bins) ).
- Reduce Memory usage: with small number of bins, can use smaller data type to store trainning data; no need to store extra info for pre-sorting features
- Sparse Optimization: Only need O(2 x #non_zero_data) to construct histogram for sparse features.
- Optimization in network communication: it implements Collective Communication Algorithms which can provide much better performance than Point-to-Point Communication.
- The way LGBM handles missing data is to ignore them and later allocate them to whiever side reduces the loss most
- Oprimization in Parallel Learning
- Feature Parallel - Different from traditional feature parallel, which partitions data vertically for each worker. In LightGBM, every worker holds the full data. Therefore, no need to communicate for split result of data since every worker know how to split data. Then Workers find local best split point{feature, threshold} on local feature set -> Communicate local best splits with each other and get the best one -> Perform best split
- Data Parallel - However, when data is huge, feature parallel will still be overhead. Use Data Parallel instead. Reduce communiation. Reduced communication cost from O(2 * #feature* #bin) to O(0.5 * #feature* #bin) for data parallel in LightGBM. Instead of "Merge global histograms from all local histograms", LightGBM use "Reduce Scatter" to merge histograms of different(non-overlapping) features for different workers. Then workers find local best split on local merged histograms and sync up global best split. LightGBM use histogram subtraction to speed up training. Based on this, it can communicate histograms only for one leaf, and get its neighbor's histograms by subtraction as well.
- Voting Parallel - Further reduce the communication cost in Data parallel to constant cost. It uses two stage voting to reduce the communication cost of feature Histograms.
- Advantages
- Faster Training - histogram method to bucket continuous features into discrete bins.
- Better Accuracy than other boosting methods, such as XGBoost.
- Performe on large dataset.
- Parallel Learning.
- More about LightGBM parameters: https://lightgbm.readthedocs.io/en/latest/Parameters.html
- Wow, it looks like a well developed package, in includes Python, R libraries and also StackOverflow tag.
- CatBoost GitHub: https://github.com/catboost
- CatBoost tutorials in IPython: https://github.com/catboost/catboost/tree/master/catboost/tutorials
- My basic code here: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/try_CatBoost_basics.ipynb
- [Python] Library: https://tech.yandex.com/catboost/doc/dg/concepts/python-installation-docpage/
- [R] Package: https://tech.yandex.com/catboost/doc/dg/concepts/r-installation-docpage/
- Param Tuning: https://tech.yandex.com/catboost/doc/dg/concepts/parameter-tuning-docpage/
- Categorical to Numerical automatically
- One of the advantage of CatBoost is, it converts categorical data into numerical data with statistical methods, automatically: https://tech.yandex.com/catboost/doc/dg/concepts/algorithm-main-stages_cat-to-numberic-docpage/
- Categorical feature values are transformed through this formula
avg_target = (countInClass + prior)/(totalCount + 1)
- Categorical feature values are transformed through this formula
- One of the advantage of CatBoost is, it converts categorical data into numerical data with statistical methods, automatically: https://tech.yandex.com/catboost/doc/dg/concepts/algorithm-main-stages_cat-to-numberic-docpage/
- The 2019 paper: https://arxiv.org/pdf/1809.04559.pdf
- When using GPU, XGBoost tend to appear to be the fastest in training (fixed set of params). It seems that at this moment, LightGBM GPU version still has some issue.
- When there are many features, XGBoost might run out of memory while CatBoost can converge into a good solution in the shortest time.
- For me, I will majorly use it to check whether the new dataset still can use current methods created from the previous dataset.
- For example, you are using online model (real time streaming), and you need to evaluate your model periodically to see whether it still can be applifed to the new data streaming. Or for time series, you want to check whether the model built for a certain time range applies to other time. And many other situations, that the current model may no longer apply to the new dataset
- Types of Data Shift
- Covariate Shift - Shift in features. Then for the new model, you may need to modify feature selection, or find those features may lead to data shift and don't use them as selected features.
- If the features in both the dataset belong to different distributions then, they should be able to separate the dataset into old and new sets significantly. These features are drifting features.
- Prior probability shift - Shift in label. For example, when you use Byesian model to predict multiple categories, then all the classes appeared in testing data has to appear in training, if not then it is Prior probability shift.
- Concept Shift - Shift in the relationship between features and the label. For example, in the old dataset, Feature1 could lead to Class 'Y', but in the new dataset, it could lead to Class 'N'.
- Covariate Shift - Shift in features. Then for the new model, you may need to modify feature selection, or find those features may lead to data shift and don't use them as selected features.
- My Code: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/deal_with_data_shifting.ipynb
- Reference: https://www.analyticsvidhya.com/blog/2017/07/covariate-shift-the-hidden-problem-of-real-world-data-science/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Reference (a pretty good one!): https://www.analyticsvidhya.com/blog/2017/01/t-sne-implementation-r-python/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- (t-SNE) t-Distributed Stochastic Neighbor Embedding is a non-linear dimensionality reduction algorithm used for exploring high-dimensional data, it considers nearest neighbours when reduce the data. It is a non-parametric mapping.
- The problem with linear dimensional reduction, is that they concentrate on placing dissimilar data points far apart in a lower dimension representation. However, it is also important to put similar data close together, linear dimensional reduction does not do this.
- In t-SNE, there are local approaches and global approaches. Local approaches seek to map nearby points on the manifold to nearby points in the low-dimensional representation. Global approaches on the other hand attempt to preserve geometry at all scales, i.e mapping nearby points to nearby points and far away points to far away points
- It is important to know that most of the nonlinear techniques other than t-SNE are not capable of retaining both the local and global structure of the data at the same time.
- In t-SNE, there are local approaches and global approaches. Local approaches seek to map nearby points on the manifold to nearby points in the low-dimensional representation. Global approaches on the other hand attempt to preserve geometry at all scales, i.e mapping nearby points to nearby points and far away points to far away points
- The algorithm computes pairwise conditional probabilities and tries to minimize the sum of the difference of the probabilities in higher and lower dimensions. This involves a lot of calculations and computations. So the algorithm is quite heavy on the system resources. t-SNE has a quadratic O(n^2) time and space complexity in the number of data points. This makes it particularly slow and resource draining while applying it to data sets comprising of more than 10,000 observations. Another drawback is, it doesn’t always provide a similar output on successive runs.
- How it works: it clusters similar data reocrds together, but it's not clustering because once the data has been mapped to lower dimensional, the original features are no longer recognizable.
- NOTE: t-SNE could also help to make semanticly similar words close to each other, which could help create text summary, text comparison.
- R practice code: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/t-SNE_practice.R
- Python practice code: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/t-SNE_Practice.ipynb
- For more Dimensional Reduction, check "DATA PREPROCESSING" section
- Some dimentional reduction methods
- My code using T-SNE for 2D, 3D visualization: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/Outliers_and_Clustering/dimensional_reduction_visualization.ipynb
- It projects multi-dimentional data into 2D or 3D, this is a type of dimensional reduction
- T-SNE works better for lower dimensional data
- My code using T-SNE for 2D, 3D visualization: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/Outliers_and_Clustering/dimensional_reduction_visualization.ipynb
- Fator Analysis is a variable reduction technique. It is used to determine factor structure or model. It also explains the maximum amount of variance in the model. Such as PCA.
- EFA (Exploratory Factor Analysis) – Identifies and summarizes the underlying correlation structure in a data set
- CFA (Confirmatory Factor Analysis) – Attempts to confirm hypothesis using the correlation structure and rate ‘goodness of fit’.
- Reference: https://www.analyticsvidhya.com/blog/2017/03/questions-dimensionality-reduction-data-scientist/?utm_content=bufferc792d&utm_medium=social&utm_source=linkedin.com&utm_campaign=buffer
- Besides different algorithms to help reduce number of features, we can also use existing features to form less features as a dimensional reduction method. For example, we have features A, B, C, D, then we form E = 2A+B, F = 3C-D, then only choose E, F as the features for analysis
- Cost function of SNE is asymmetric in nature. Which makes it difficult to converge using gradient decent. A symmetric cost function is one of the major differences between SNE and t-SNE.
- For the perfect representations of higher dimensions to lower dimensions, the conditional probabilities for similarity of two points must remain unchanged in both higher and lower dimension, which means the similarity is unchanged.
- LDA aims to maximize the distance between class and minimize the within class distance. If the discriminatory information is not in the mean but in the variance of the data, LDA will fail.
- LDA is used in linearly seperated classification problems. For non-linear classes' relationship, can try kernel functions to convert to linear relationship first
- LDA doesn't work well when the number of features is larger than the number of observations
- Both LDA and PCA are linear transformation techniques. LDA is supervised whereas PCA is unsupervised. PCA maximize the variance of the data, whereas LDA maximize the separation between different classes.
- When eigen values are roughly equal, PCA will perform badly, because when all eigen vectors are same in such case you won’t be able to select the principal components because in that case all principal components are equal. When using PCA, it is better to scale data in the same unit.
- To make this concept simple, PCA is built on checking feature variance. So features with larger values and tend to have larger variance could misleading PCA results, and therefore we need to normalize the data before using PCA. I guess, maybe because some features have much larger variance, eigen tend to show roughly equal
- When using PCA, features will lose interpretability and they may not carry all the info of the data. You don’t need to initialize parameters in PCA, and PCA can’t be trapped into local minima problem. PCA is a deterministic algorithm which doesn’t have parameters to initialize. PCA can be used for lossy image compression, and it is not invariant to shadows.
- A deterministic algorithm has no param to initialize, and it gives the same result if we run again.
- Logistic Regression vs LDA:
- If the sample size is small and distribution of features are normal for each class. In such case, linear discriminant analysis (LDA) is more stable than logistic regression.
-
For my past notes on evaluation methods, check: https://github.com/hanhanwu/readings/blob/master/Evaluation_Metrics_Reading_Notes.pdf
-
7 important model evaluation metrics and cross validation: https://www.analyticsvidhya.com/blog/2016/02/7-important-model-evaluation-error-metrics/
-
11 important model evaluation metrics and corss validation: https://www.analyticsvidhya.com/blog/2019/08/11-important-model-evaluation-error-metrics/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
Confusion Matrix
-
F1 - the benefit of F1 score is to prevent all the records got predicted as positive or negative.
- Because
F1 = 2*precision*recall/(precision + recall), for example precision = 0, recall=1, F1 will only be 0.5.
- Because
-
Besides F Sccore, there is G measure (G mean)
- G mean1 -
GSP = sqrt(recall * precision)- While F score is the harmonic mean of precision and recall, GSP (G mean1) is the geometric mean.
- G mean2 -
GSS = sqrt(recall * sensitivity)
- G mean1 -
-
Lift / Gain charts are widely used in campaign targeting problems. This tells us till which decile can we target customers for an specific campaign. Also, it tells you how much response do you expect from the new target base.
- The diagonal shows random situation, and you should compare your model with this diagonal (similar to ROC logic). The graph tells you how well is your model segregating responders from non-responders
- The first decile means, at 10% population (x-axis), if you got 14% responders, it means you have 140% lift at first decile
- The very first step is to create this gain/lift chart, so that you can plot other charts:

- With graph Lift@Decile, you can figure out till which decile, your model still works well, so that later you will know to which level you can adjust your model
lift@decile = number of respindents at that decile/total number of respondents
-
Kolmogorov-Smirnov (K-S) chart is a measure of the degree of separation between the positive and negative distributions. The K-S is 100, the higher the value the better the model is at separating the positive from negative cases.
- It seems that, using this method you still need to calculate gain/lift chart which records the positive/negative count in each decile, and finally calculate KS. For each decile
KS = Cumulative Positive% - Cumulative Negative% - If the K-S statistic is small or the p-value is high, then we cannot reject the hypothesis that the distributions of the two samples are the same.: https://stackoverflow.com/questions/10884668/two-sample-kolmogorov-smirnov-test-in-python-scipy?utm_medium=organic&utm_source=google_rich_qa&utm_campaign=google_rich_qa
- It seems that, using this method you still need to calculate gain/lift chart which records the positive/negative count in each decile, and finally calculate KS. For each decile
-
The ROC curve is the plot between sensitivity and (1- specificity). (1- specificity) is also known as false positive rate and sensitivity is also known as True Positive rate. To bring ROC curve down to a single number, AUC, which is the ratio under the curve and the total area. .90-1 = excellent (A) ; .80-.90 = good (B) ; .70-.80 = fair (C) ; .60-.70 = poor (D) ; .50-.60 = fail (F). But this might simply be overfitting. In such cases it becomes very important to do in-time and out-of-time validations. For a model which gives class as output, will be represented as a single point in ROC plot. In case of probabilistic model, we were fortunate enough to get a single number which was AUC-ROC. But still, we need to look at the entire curve to make conclusive decisions.
Gini Coefficient = 2*AUC – 1. It indicates how large the ROC area is above the diagnoal.- Compared with Gain/Lift Chart, Lift is dependent on total response rate of the population. ROC curve on the other hand is almost independent of the response rate, because the numerator and denominator of both x and y axis will change on similar scale in case of response rate shift.
- When there is data imbalance problem, ROC may not work well, especially when positive class is very small, in this case try precision-recall curve (PR curve) might be better.
-
ROC-AUC vs AVP vs F1 vs Balanced Accuracy
- When data is imbalanced, AVP is more reliable than ROC and Balanced Accuracy. Because when data is imbalanced (much more negative than positive), TN can be high, and therefore balanced accuracy can be higher (TNR is higher) while ROC-AUC can be larger (FPR is smaller).
- Comparing with AVP, F1 sets precision and recall the same weight, while AVP is using increased recall (δ recall) from the previous threshold as the weight for current precision.
-
Logloss (binary cross-entropy)
- It takes the probability (certainty) of prediction into account.
log-loss = negative average of the log of corrected predicted probability, check details here- Check the curves of logloss, it penalizes more on false predicted results.
- Lower logloss value, the better.
- It takes the probability (certainty) of prediction into account.
-
RMSE: The power of ‘square root’ empowers this metric to show large number deviations. Often used as a metric for linear regression (convex function).
- RMSE is highly affected by outlier values. Hence, make sure you’ve removed outliers from your data set prior to using this metric. As compared to mean absolute error, RMSE gives higher weightage and punishes large errors.
- Tend to stuck at local minimum for non-convex function, such a logistic regression.
- Logloss is a better choice in this situation.
-
(RMSLE) Root Mean Squared Logarithmic Error
- RMSLE is usually used when we don’t want to penalize huge differences in the predicted and the actual values when both predicted and true values are huge numbers.
- If both predicted and actual values are small, RMSE and RMSLE are the same
- If actual value & predicted value are large values, RMSE will be larger than RMSLE
- sklearn implementation of RMSLE: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.mean_squared_log_error.html
-
k-fold cross validation is widely used to check whether a model is an overfit or not. If the performance metrics at each of the k times modelling are close to each other and the mean of metric is highest. For a small k, we have a higher selection bias but low variance in the performances. For a large k, we have a small selection bias but high variance in the performances. Generally a value of k = 10 is recommended for most purpose.
-
To measure linear regression, we could use Adjusted R² or F value.
-
Variance inflation factor (VIF) is used as an indicator of multicollinearity.
- Higher VIF, the feature is more likely to be highly correlated with other features.
- Normally VIF > 10 is very high correlation, VIF > 5 is risky.
-
To measure logistic regression:
- AUC-ROC curve along with confusion matrix to determine its performance.
- The analogous metric of adjusted R² in logistic regression is AIC. AIC is the measure of fit which penalizes model for the number of model coefficients. Therefore, we always prefer model with minimum AIC value.
- AIC vs BIC:
- https://methodology.psu.edu/AIC-vs-BIC
- http://www.differencebetween.net/miscellaneous/difference-between-aic-and-bic/
- AIC is an estimate of a constant + the relative distance between the unknown true likelihood function of the data and the fitted likelihood function of the model, so that a lower AIC means a model is considered to be closer to the truth.
- BIC is an estimate of a function of the posterior probability of a model being true, under a certain Bayesian setup, so that a lower BIC means that a model is considered to be more likely to be the true model.
- They both penalize model coefficients. They are similar, but BIC penalize complex models more.
- Null Deviance indicates the response predicted by a model with nothing but an intercept. Lower the value, better the model.
- Residual deviance indicates the response predicted by a model on adding independent variables. Lower the value, better the model.
- Regularization becomes necessary when the model begins to ovefit / underfit. This technique introduces a cost term for bringing in more features with the objective function. Hence, it tries to push the coefficients for many variables to zero and hence reduce cost term. This helps to reduce model complexity so that the model can become better at predicting (generalizing).
-
Probability vs Response
- Probability means predict continuous values (such as probability), Response means predict specific classes.
- Response Measures
- Confused Matrix >> Precision-Recall, F Score, Specificity & Sensitivity, ROC-AUC/Banalced Accuracy/G-Mean, Gini Coefficient
- Concordant & Discordant
- Probability Measures
- Logloss (often used by Kaggle) - it focuses on penalizing false classification. So the goal to improve your model is to minimize logloss.
- Adjusted R-square - used to reduce collineary problem (reduce correlated features) in regression. We can check both Adjusted R-Square and R-Square, if R-Square is much higher, it means we have unnecessary features that do not contribute much in the model.
adjusted R-square = 1 - (1-R-square)*(n-1)/(n-k-1)- n - number of samples
- k - number of features
- Expected Variance & Residual Variance
- R-Square = Expected Variance/Total Variance. It's the percentage of the response variable variation that is explained by the model.
- so higher expected variance can be better, although it can suffer simiar critics that RMSE got.
R-Square = 1- MSE(model)/MSE(baseline)- MSE(model): Mean Squared Error of the predictions against the actual values
- Mean Squared Error of average prediction against the actual values
- R-Square, RSS (residual sum of squares) = MSE*n, will increase when there are more features, but the test error may not drop. Therefore, R-Square, RSS should NOT be used for selecting models that have differernt number of features.
- Better to check residual plot with R square, if there is a pattern in the residual plot instead of the randomness, then even if R square is high, there is still unexplained pattern in the data
- Residual Variance (Unexplained Variance) = Total Variance - Expected Variance, lower the better.
- R-Square = Expected Variance/Total Variance. It's the percentage of the response variable variation that is explained by the model.
- RMSE, sensitive to large outliers, mean is not statistical robust
- Since mean is not statistical robust, we can try:
- Quantile of Errors
- Median Absolute Percentage =
median(|(yi_true - yi_forecast)/yi_true|)
- Brier Score
- It is calculated by Uncertainty, Resolution and Reliability scores
- You just need ground truth and the probability prediction results to do the calculation.
- Predictions that are further away from the expected probability are penalized, but less severely as in the case of log loss.
- Like the average log loss, the average Brier score will present optimistic scores on an imbalanced dataset, rewarding small prediction values that reduce error on the majority class.
- This is the best tutorial I have found from description to implementation: https://timvangelder.com/2015/05/18/brier-score-composition-a-mini-tutorial/
- Logloss vs MSE
- Logloss
- Each predicted probability is compared to the actual class output value (0 or 1) and a score is calculated that penalizes the probability based on the distance from the expected value. The penalty is logarithmic, offering a small score for small differences (0.1 or 0.2) and enormous score for a large difference (0.9 or 1.0).
- A model with perfect skill has a log loss score of 0.0. In order to summarize the skill of a model using log loss, the log loss is calculated for each predicted probability, and the average loss is reported.
- It can be misleading for largely imbalanced data, because when predicting 0 or smaller probabilities, the loss will be smaller.
- MSE (Squared Error) works better for continuous output while Logloss works better for numerical classification.
- Similar to MSE, logloss will increase when the predicted probability diverges from the actual value. At the same time, Logloss takes into account the uncertainty of the predictions based on how much it varies from the ground truth.
- MSE would be bad if we're aiming to have our model output discrete values (such as 0, 1), because the model would end up trying to keep values close to 0 or 1 (basically estimating the mean of the distribution) and wouldn't learn to do anything very sophisticated around distribution estimation. However when your targets are continuous, RMSE/MSE works fairly well - in other words, squared error is a good measure for regression but not for numerical classification.
- Logloss does maximum likelihood estimation of a multinomial distribution, it also punishes bad class labelling, but only when those labels have high confidence. So Logloss is better for numerical classification.
- Logloss
-
Data Validation
- Hold Out - Your dataset is seperated into Training, Validation and Holdout
- Training, Validation is used to train and tune the model. Results are used to select among different models.
- Holdout is to check how's the trained model work on another dataset.
- Holdout data should NEVER be used to select model or tune the model.
- When your dataset is small
- Cross Validation
- Leave One Out/JackKnife
- k-fold
- Repeated k-fold
- Stratified k-fold
- Adversarial Validation
- This method is special. It checks the similarity between training data and testing data by generating the probability of 'is_train' for all the training & testing data. With the generated probability, you sort training data in probability descending order, and chose the top x% as the validation set, the rest training data as training set.
- Time Series Cross Validation
- In each split, it adds one more new data as teting data, and all the previous data as training data.
- My code [Python]: https://github.com/hanhanwu/Hanhan_Data_Science_Resources2/blob/master/validation_methods_sumamry.ipynb
- reference: https://www.analyticsvidhya.com/blog/2018/05/improve-model-performance-cross-validation-in-python-r/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- My code is better, the reference code is missing a few code
- My code [R]: https://github.com/hanhanwu/Hanhan_Data_Science_Resources2/blob/master/validation_methods_summary.R
- Without using
mlrlibrary, if you just want to use Rtrainmethod to call different machine learning algorithms, check R - train models by tag - In stratify cross validation, it has the code for:
- Generating the label value distribution
- Do cross validation given just fold labels of each row
- In leave-one-out cross validation
- Better to use regression prediction results, because if it's classification with response results, how could you calculate metrics with 1 row validation set?
- Without using
- Bootstrap
- Resample with replacement
- UNIFORMALY random draw
- The advantage of draw with replacement is, the distribution of the data won't be changed when you are drawing
- Cross Validation
- Hold Out - Your dataset is seperated into Training, Validation and Holdout
-
Calibration
- We all know that we can predict classes with probability in classification. The return probability of the predicted classes can be overconfident or underconfident. Well calibrated classifiers can return probabilities that also serve as the confidence level of the prediction.
- Also because of the biased probability some classifiers can return, calibration also serve as a postprocessing method after classification to reduce the prediction bias.
- My code & description: https://github.com/hanhanwu/Hanhan_Data_Science_Resources2/blob/master/about_calibration.ipynb
- Part 1 - Compare the calibration of multiple classifiers
- If the plot is closer to the diagonal, the higher accuracy the model has. Sometimes you cannot tell which model is better through plot so added Brier score in the code.
- We use Brier score as the evaluation, lower Brier, more accurate, better calibrated predictions. We can also see whether each classifier push the values towards to 0 or 1, or push away from them.
- Part 2 - Calibration as classification post-processing
- The purpose of post-processing is to improve the calibration results of the classification models.
- We use naive bayesian as the base model, comapred without calibration, with sigmoid calibration and with non-paramatric isotonic calibration.
- Part 1 - Compare the calibration of multiple classifiers
- To learn more about calibration: http://www.analyticsvidhya.com/blog/2016/07/platt-scaling-isotonic-regression-minimize-logloss-error/?utm_content=buffer2f3d5&utm_medium=social&utm_source=facebook.com&utm_campaign=buffer

-
[Python & R] Sklearn vs R Label Encoding
- Sklearn Label Encoding that converts categorical data into numerical data, can be risky, as most models will treat these values as continuous input, and would interpret the categories as being ordered, which is often not desired. Here are some solutions in python sklearn:
- One-hot encoding before feature selection, because one-hot encoding can deal with this issue but will also create too much features
- Just use that label encoding, with solid model evaluation methods.
- Use R
- It has
as.numeric(as.factor())which will avoid the problem
- It has
- Sklearn Label Encoding that converts categorical data into numerical data, can be risky, as most models will treat these values as continuous input, and would interpret the categories as being ordered, which is often not desired. Here are some solutions in python sklearn:
-
[Python] Feature Selection & Param Tuning & Model Selection
- sklearn tend to have many functions and can have overlaps with each other. I want to simplify these 3 steps and try to make them form a pipeline.
- Feature Selection
- Recursive Feature Elimination: http://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.RFECV.html#sklearn.feature_selection.RFECV
- Methods such as backward selection
- It also allows you to do cross validation in it
- Chi2 Feature Selection: http://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.chi2.html#sklearn.feature_selection.chi2
- chi-square test measures the dependence between stochastic variables (non-deterministic variables). So this method uses chi-square to remove features that are independent from the label and therefore does not contribute to the prediction
- Boruta All Relevant Feature Selection
- I think it has similar concept as chi-square feature selection. Instead of removing features that are independent from the class label, all relevant feature selection is trying to find features that contribute to the class prediction and which features contribute to which class value: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/classification_for_imbalanced_data/boruta_all_relevant_feature_selection.pdf
- https://github.com/scikit-learn-contrib/boruta_py
- Mutual Info Estimation
- Also similar to all relevant feature selection, this method measures the mutual info between each feature and the target. When the value is 0, the 2 are independent from each other; higher the value, higher the dependency.
- It relies on nonparametric methods based on entropy estimation from k-nearest neighbors distances.
- For discrete label: http://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.mutual_info_classif.html#sklearn.feature_selection.mutual_info_classif
- For continuous label: http://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.mutual_info_regression.html#sklearn.feature_selection.mutual_info_regression
- Variance Threshold Feature Selection
- This is the basic one that can be used in preprocessing step. It removes all low-variance features. Sounds quite like PCA.
- http://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.VarianceThreshold.html#sklearn.feature_selection.VarianceThreshold
- Drop Highly Correlated Features
- Recursive Feature Elimination: http://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.RFECV.html#sklearn.feature_selection.RFECV
- Model Selection
- http://scikit-learn.org/stable/model_selection.html
- Calibration should also be considered in model selection method, it's based on prediction confidence: https://scikit-learn.org/stable/modules/calibration.html
-
[R] Caret package for data imputing, feature selection, model training (I will show my experience of using caret with detailed code in Hanhan_Data_Science_Practice): https://www.analyticsvidhya.com/blog/2016/12/practical-guide-to-implement-machine-learning-with-caret-package-in-r-with-practice-problem/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
[Python & R] A brief classified summary of Python Scikit-Learn and R Caret: https://www.analyticsvidhya.com/blog/2016/12/cheatsheet-scikit-learn-caret-package-for-python-r-respectively/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
[Python] What to pay attention to when you are using Naive Bayesian with Scikit-Learn: https://www.analyticsvidhya.com/blog/2015/09/naive-bayes-explained/?utm_content=bufferaa6aa&utm_medium=social&utm_source=linkedin.com&utm_campaign=buffer
-
[R] Cluster Analysis: https://rstudio-pubs-static.s3.amazonaws.com/33876_1d7794d9a86647ca90c4f182df93f0e8.html
-
[Java] SPMF, it contains many Pattern Mining algorithms that cannot be found in R/Scikit-Learn/Spark, especailly algorithms about Pattern Mining: http://www.philippe-fournier-viger.com/spmf/index.php?link=algorithms.php
-
[Python] Scikit-Learn algorithms map and Estimators
- sklearn Estimator map: http://scikit-learn.org/stable/tutorial/machine_learning_map/
- I'm sure that I have copied this before, but today I have learned something new about this map! Those green squares are clickable, and they are the estimators
- An estimator is used to help tune parameters and estimate the model
- This map also helps you find some algorithms in Scikit-Learn based on data size, data type
-
[Python] TPOT - Automated Model Selection with Param Optimization
- TPOT documentation: http://rhiever.github.io/tpot/
- TPOT Python API: http://rhiever.github.io/tpot/api/
- It automatically does feature preprocessing, feature construction, feature selection, model selection and optimization
- For optimization, it is using Genetic Algorithm
- TPOT is built upon Scikit-Learn, so those models, methods you can find in TPOT can be found in scikit-learn too. This is what I really like. For example, in Scikit-Learn, classification will use stratfied cross validation while regression will use k-fold. TPOT does the same, and it helps you find the best model with optimized params in its pipeline
-
[Python] MLBox - Automated Model Selection with Param Optimization
- MLBox GitHub: https://github.com/AxeldeRomblay/MLBox
- It does some data cleanning and preprocessing for you, but better to do things on your own before using it.
- It also does model selction and param optimization like TPOT, what makes MLBox looks good is, each step of work, it ourputs some info to give you more insights of its performance.
- MLBox Data Cleaning, in
train_test_split()- Delete unnamed cols
- Remove duplicates
- Extract month, year and day of the week from a Date column
- Remove Shifting Data automatically,
Drift_thresholder().fit_transform(data)- But it may be differ from manually removing shifting data, check my code here: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/deal_with_data_shifting.ipynb
- Only deals with covariate shifting (shifting in fetures)
- Details for how data shifting checking in MLBox works: https://www.analyticsvidhya.com/blog/2017/07/mlbox-library-automated-machine-learning/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- It uses Entity Embeding to encode categorical data
- It seems that, with
Entity Encoding, you can link similar/relavant categorical values together
- It seems that, with
- Model Selection and Param Optimization
- It uses hyperopt library which is fast, below are the param categories you can set:
- Check params can be set in
optimize(): http://mlbox.readthedocs.io/en/latest/features.html#optimisation - Also check my code sample: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/try_mlbox.ipynb
- Shortages:
- Still in development, also some libraries used now can be out of dated in the next version
- No support to unsupervised learning for now
-
[Python]Deploy Machine Learning Model as an API, using Flask: https://www.analyticsvidhya.com/blog/2017/09/machine-learning-models-as-apis-using-flask/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
Python MapReduce
- With this tool, you can run your python code in map reduce way, so that it's much faster, and when you are not using this map reduce, the same python code can be running as single thread
- Install
mrjob: https://pythonhosted.org/mrjob/guides/quickstart.html - Write a python file that contains map reduce job: https://pythonhosted.org/mrjob/guides/quickstart.html, let's call this file mr_job.py
- Your real python logic is in another file, let's call it my_python_main.py
- Create a python virtual environment
- run your map reduce job with your logic, read input and create output:
python my_python_main.py < test_data/test_file.test > outfile.new- The input, output can be whatever format readable, in your mapper, you can do some data preprocessing to format the data
- In your code, you can write
printto help debug, the printed output will be in your output file, won't be shown through terminal
-
Python Param Tuning Tools
- How to use Hyperopt: http://steventhornton.ca/hyperparameter-tuning-with-hyperopt-in-python/
- "Hyperopt package provides algorithms that are able to outperform randomized search and can find results comparable to a grid search while fitting substantially less models"
- tutorial: http://steventhornton.ca/hyperparameter-tuning-with-hyperopt-in-python/
- code: https://github.com/steventhornton/Hyperparameter-Tuning-with-hyperopt-in-Python
- Scikit-Learn param turning methods: http://scikit-learn.org/stable/modules/classes.html#hyper-parameter-optimizers
- My code - Random Search vs Grid Search: https://github.com/hanhanwu/Basic_But_Useful/blob/master/RandomSearch_vs_GridSearch_cv.ipynb
- Here I used hyperopt implemented in sklearn, it is random search. I also used sklearn grid search, random search
- TPOT is using Genetic Algorithm for param tuning: https://medium.com/cindicator/genetic-algorithms-and-hyperparameters-weekend-of-a-data-scientist-8f069669015e
scipy.optimizehas many optimization functions- Find them all, seach for "optimize": https://docs.scipy.org/doc/scipy-0.15.1/reference/generated/
- More math about these functions: https://docs.scipy.org/doc/scipy/reference/optimize.html
- It seems that this list does include all
- How to use Hyperopt: http://steventhornton.ca/hyperparameter-tuning-with-hyperopt-in-python/
-
Learn Rough Sets (RST) & Fuzzy Rough Sets (FRST)
- They are pattern mining methods. What is Rough Set: https://www.geeksforgeeks.org/rough-set-theory-an-introduction/
- Learning Code about basic data analysis with RST & FRST: https://github.com/hanhanwu/Hanhan_Data_Science_Resources2/blob/master/RoughSets_FuzzyRoughSets.R
- With Rough Sets and Fuzzy Rough Sets in this library, you do use rule induction for classification
- The library also allows you to do instance selection, which removes noisy, unnecessary or inconsistent instances
- reference: https://cran.r-project.org/web/packages/RoughSets/RoughSets.pdf
-
Learn Markov Chain
- Learning Code about Markov Chain: https://github.com/hanhanwu/Hanhan_Data_Science_Resources2/blob/master/learn_markov_chain.R
- To visualize a transition system, we can use DiagrammeR: http://rich-iannone.github.io/DiagrammeR/graphviz_and_mermaid.html
- A transition from 0 to 1 means an item was not in previous state but in current state; a transition from 1 to 1 means an item was in previous state and also in current state. With Markov Chain, we can calculate the conditional probabilities of transitioning from state to state. For example P10 = [Pk+1=1 | Pk=0] means, given kth state as 0, what's the probability of (k+1)th state as 1. For each state, its previous state will only have 1 or 0, therefore:
P00 + P01 = 1P10 + P11 = 1- So we only need to calculate 2 probabilities and will get the other 2
- reference: https://www.kaggle.com/mmotoki/markov-chain-tutorial/notebook
- The main idea is to calculate the probability of transition between previous and current states
- You can generate product list by order_id or user_id
- it's majorly using bin drop count methods to count transitions, very easy to be confused. Till now, I'm not very clear about reasons for the last step +1, +2
- Learning Code about Markov Chain: https://github.com/hanhanwu/Hanhan_Data_Science_Resources2/blob/master/learn_markov_chain.R
-
Learn Hidden Markov Model (HMM)
- The model is hidden but we have historical data and maximum likelihood estimation
- maximum likelihood estimation (ME): it produces distributional parameters that maximize the probability of observing the data at hand
- Problems it deals with
- Given a sequence of observed values, provide a probability that this sequence was generated by the specified HMM
- Forward algorithm - it stores the summed probabilities, so that they can be re-use
- Backward algorithm - it expresses a probability of being in state
iat timetand moving to statejat timet+1
- Given a sequence of observed values, provide the sequence of states the HMM most likely has been in to generate such values sequence
- Viterbi Algorithm - find the path that maximizes each state probability, and the path is valid
- Given a sequence of observed values we should be able to adjust/correct our model parameters
- Baum-Welch algorithm * Either the initial model defines the optimal point of the likelihood function and λ * Or the converged solution provides model parameters that are more likely for a given sequence of observations
- Given a sequence of observed values, provide a probability that this sequence was generated by the specified HMM
- References
- The author provided her detailed mathematical description: https://codefying.com/2016/09/15/a-tutorial-on-hidden-markov-model-with-a-stock-price-example/
- The code: https://github.com/elena-sharova/HiddenMarkovModel
- I just tried
yahoo-finance, it had 2 major class for Currency and Share. But at least Share no longer works, the YQL has been disabled. Although this is not the first time I saw yql discontinued services, when you are seeing a past giant company is reducing its services more and more, while in fact many of the services were great, the feeling is complex - But we can download some sample data here: https://github.com/matplotlib/mpl_finance/tree/master/examples/data
- I just tried
- The code: https://github.com/elena-sharova/HiddenMarkovModel
- The author's evaluation results: https://codefying.com/2016/09/19/a-tutorial-on-hidden-markov-model-with-a-stock-price-example-part-2/
- Lessons learned from here, only using End of Day share time series to predict didn't work well. So maybe better sequence predictions requires more granular data
- The author provided her detailed mathematical description: https://codefying.com/2016/09/15/a-tutorial-on-hidden-markov-model-with-a-stock-price-example/
- Deprecated in hmmlearn and scikit-learn for now
- I tried both hmmlearn and scikit-learn, in hmmlearn, I tried both Gaussian hmm and Gaussian Mixture hmm. All got deprecation errors. hmmlearn is showing one of the function is deprecated, I checked the solution in open source, they pointed to scikit-learn hmm, but it has been deprecated started from scikit-learn 0.17, the version contains it was too old. I think deprecation did have reasons. Maybe at this moment, R is the best solution.
- My code (the sklearn deprecation made this code not useful!): https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/sequencial_analysis/try_hidden_markov.ipynb
- I have also found the sample data used in hmmlearn tutorial: https://github.com/hmmlearn/hmmlearn/blob/master/examples/plot_hmm_stock_analysis.py
- For More about my Markov Chain & Sequnetial Analysis practice, check: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/tree/master/sequencial_analysis
- The model is hidden but we have historical data and maximum likelihood estimation
-
Bayesian

- Bayesian Models (Naive Bayesian, GaussianNB, etc.) has priori for you to set. In this python sklearn example, you will see how to set priori: https://stackoverflow.com/questions/30896367/how-to-specify-the-prior-probability-for-scikit-learns-naive-bayes?utm_medium=organic&utm_source=google_rich_qa&utm_campaign=google_rich_qa
- It seems that the priori here indicates which class do you want to focus on the prediction, the the priori you set is more like the weights of the classes
- Bayesian Method can also be used for model comparison, check page 20 here: http://www.mpia.de/homes/calj/astrostats2013/astrostats2013_bayes.pdf
- Here's the description about how to use Bayesian Method to compare models: https://stats.stackexchange.com/questions/342605/how-to-use-bayesian-evidence-to-compare-models
- Here's more description from PyMC3 on Bayes Factors and Marginal Likelihood: http://docs.pymc.io/notebooks/Bayes_factor.html
- Bayesian Models (Naive Bayesian, GaussianNB, etc.) has priori for you to set. In this python sklearn example, you will see how to set priori: https://stackoverflow.com/questions/30896367/how-to-specify-the-prior-probability-for-scikit-learns-naive-bayes?utm_medium=organic&utm_source=google_rich_qa&utm_campaign=google_rich_qa

- My Applied Statistics: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/Applied_Statistics/ReadMe.md
- Stats dictionary - Some basic formulas: http://mtweb.mtsu.edu/stats/dictionary/formula.htm
- Applied Linear Algebra: https://www.analyticsvidhya.com/blog/2019/07/10-applications-linear-algebra-data-science/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Overall
- The expected value of any distribution is the mean of the distribution
- Bernoulli Distribution
- only 2 possible outcomes.
- The expected value for a random variable X in this distributioon is
p(probability) - The variance for a random variable X in this distributioon is
p(1-p)
- Uniform Distribution
- The probability of all the N number of outcomes are equally likely.
a is min of uniform distribution,b is max of uniform distribution, the probability of a random variable in X is1/(b-a); the probability of a range (x1,x2) is(x2-x1)/(b-a)mean = (a+b)/2variance = (b-a)^2/12- Standard Uniform Distribution has
a=0, b=1, if x in [0,1] range, probability is 1, otherwise 0
- Binomial Distribution
* 2 outcomes, the probability for each is p, 1-p. In each trail, the probability of each outcome is the same.
- Each trail is independent.
nis the number of trails,pis the probability of success in each trail =>mean=n*p,variance=n*p*(1-p)- If the probability of 2 outcomes p, 1-p are the same, then the distribution is normal distribution.
- Odds: Odds are defined as the ratio of the probability of success and the probability of failure. For example, a fair coin has probability of success is 1/2 and the probability of failure is 1/2 so odd would be 1.
odds = # of event happen / # of event not happenodds ratio = odds of event happend / odds of event not happen, usually used to compare the outcome of 2 eventslog odds = log(odds),log odds ratio = log(odds ratio), applying log is to normalze the values, since the value range of odds is between 0 and infinite, the gaps between the odds of event happen and the odds of event not happen can be huge. Log can reduce the gap, and also make the distribution of the odds symmetric
- Normal Distribution
- The mean, median and mode of the distribution coincide.
- The curve of the distribution is bell-shaped and symmetrical about the line x=μ.
- The total area under the curve is 1.
- Standard normal distribution has mean 0 and standard deviation 1
- More about normal distribution: https://www.analyticsvidhya.com/blog/2020/04/statistics-data-science-normal-distribution/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Skewness
- Q-Q Plot (quantile-quantile plot) - it's the quantiles of observed data comparing with normal distribution quantiles.
- Kurtosis - Majorly indicates the distribution along the tails.
- Mesokurtic distribution
- Leptokurtic Distribution
- Platykurtic Distribution
- Poisson Distribution
- Example of how to apply poisson: https://www.analyticsvidhya.com/blog/2022/06/predicting-the-scoreline-of-a-football-match-using-poisson-distribution/?utm_source=feedburner&utm_medium=email
- Estimate the probability of something could happen in an event
- It is applicable in situations where events occur at random points of time and space where in our interest lies only in the number of occurrences of the event.
- e.g number of times of have ice-cream in a year; number of flowers in a garden. etc
- Events are independent from each other.
- The probability of success over a short interval must equal to the probability of success over a longer interval.
- The probability of success in an interval approaches zero as the interval becomes smaller.
λis the rate at which an event occurs,tis the length of a time interval, andXis the number of events in that time interval.mean = λ*t.
- Example of how to apply poisson: https://www.analyticsvidhya.com/blog/2022/06/predicting-the-scoreline-of-a-football-match-using-poisson-distribution/?utm_source=feedburner&utm_medium=email
- Exponential Distribution
- Compared with poisson distribution, exponential distribution means the time interval between 2 events.
- e.g the time interval between eating 2 ice-creams
- It is widely used in survival analysis.
λis called the failure rate of a device at any timet, given that it has survived up to t. For a random variable X,mean=1/λ,variance=(1/λ)^2. The greater the rate, the faster the curve drops and the lower the rate, flatter the curve.
- Compared with poisson distribution, exponential distribution means the time interval between 2 events.
- Relationship between distributions
- Bernoulli Distribution is a special case of Binomial Distribution with a single trial
- Poisson Distribution is a limiting case of binomial distribution under the following conditions:
- The number of trials is indefinitely large or n → ∞.
- The probability of success for each trial is same and indefinitely small or p →0.
- np = λ, is finite
- Normal distribution is another limiting form of binomial distribution under the following conditions:
- The number of trials is indefinitely large, n → ∞
- Both p and q are NOT indefinitely small, and p=q
- Normal distribution is also a limiting case of Poisson distribution with the parameter λ →∞
- If the times between random events follow exponential distribution with rate λ, then the total number of events in a time period of length t follows the Poisson distribution with parameter λt.
- Skewness List for Distributions: https://mathworld.wolfram.com/Skewness.html
- With this method, it can check whether a distribution is skewed
- Positive value means right skewed (positively skewed)
- Negative value means left skewed (negatively skewed)
- 0 means not skewed
- reference: https://www.analyticsvidhya.com/blog/2017/09/6-probability-distributions-data-science/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- With Maximum Likelihood, you can estimate population parameters from sample data such that the probability (likelihood) of obtaining the observed data is maximized.
- How to calculate maximum likelihood: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/Applied_Statistics/Learning_Notes/point_estimation.md#maximum-likelihood-estimation
- It's a type of point estimation, meaning just to estimate a single value. By comparison, confidence interval is a method to estimate a value range.
- However, sometimes deviations won't give direct help and people can still use other ways to find the maximum - Optimization Algorithms
- From an arbitrary starting point, may end up in local maximum , but can be fast
- When the model is assumed to be Gaussian, the MLE estimates are equivalent to the ordinary least squares method.
- My Practice Code: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/Applied_Statistics/try_maximum_likelihood_estimation.R
- Detailed description: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/Applied_Statistics/ReadMe.md#maximum-likelihood-estimation
- Reference: https://www.analyticsvidhya.com/blog/2016/06/bayesian-statistics-beginners-simple-english/
- Frequentist Statistics
- Frequentist Statistics tests whether an event (hypothesis) occurs or not. It calculates the probability of an event in the long run of the experiment (i.e the experiment is repeated under the same conditions to obtain the outcome).
- Drawback 1 - p-value changes when sample size and stop intention change
- Drawback 2 - confidence level (C.L) also heavily depends on sample size like p-value
- Drawback 3 - confidence level (C.L) are not probability distributions therefore they do not provide the most probable value for a parameter and the most probable values
- Frequentist Statistics vs Bayesian Hypothesis: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/Applied_Statistics/Learning_Notes/bayesian_analysis/NHST_vs_Bayesian.md
Find All Calculators here
- 🌟 Terminology glossary for statistics in machine learning: https://www.analyticsvidhya.com/glossary-of-common-statistics-and-machine-learning-terms/
- It's a great summary!
- Something to correct
- "Multivariate Regression": is the regression has multiple INDEPENDENT variables, NOT multiple dependent variable.
- Statistics behind Boruta feature selection: https://github.com/hanhanwu/Hanhan_Data_Science_Resources2/blob/master/boruta_statistics.pdf
- It finds all relevant variables, and removes features proved by a statistical test to be less relevant than random probes.
- The importance of anattribute is obtained as the loss of accuracy of classification caused by randomly permutation of attribute values between objects.
- How the laws of group theory provide a practical lessons of building efficient distributed and real-time aggregation systems (from 22:00, he started to talk about HyperLog and other approximation data structures): https://www.infoq.com/presentations/abstract-algebra-analytics
- Confounding Variable vs Interaction
- Confounding variable is the variable that will affect both dependent and independent variables. I will increase the variance and introduce bias in the model results.
- For example, gaining weight is the dependent variable, lack of exercise is an independent variable, age is the confounding variable that will affect both of these variables.
- Better to control some the variable values used in data sample and experiments, such as limit the age within 1 group for the experiment.
- Interaction indicates how variable A affects the dependent variable differs when variable B changes among different levels.
- In some model output, we will output the interaction between features to uderstand further about the data.
- Confounding variable is the variable that will affect both dependent and independent variables. I will increase the variance and introduce bias in the model results.
- Errors and Residuals: https://en.wikipedia.org/wiki/Errors_and_residuals
- Statistical Error is the amount by which an observation differs from its expected value (population mean). Since the mean of the population is not observable in most of the cases, error is not an observable either.
- Residual is observable, it is an observable estimate of the unobservable statistical error. Residual is the amount by which an observation differs from its sample mean (not population mean).
- Explained Variation vs Residual Variation
- Residual Variation is unobservable.... It indicates the variance around the regression line.
- This video is good: https://www.coursera.org/learn/regression-models/lecture/WMAET/residual-variance

Residual Variance = Total Variance - Explained VarianceR-Squared = Explained Variance/Total Variance, so explained variance higher, the better, although it will get similar criticism as R-Square for not be able to handle multicolineary
- Heteroskedasticity: led by non-constant variance in error terms. Usually, non-constant variance is caused by outliers or extreme values.
- Coefficient and p-value/t-statistics: coefficient measures the strength of the relationship of 2 variables, while p-value/t-statistics measures how strong the evidence that there is non-zero association
- Anscombe's quartet comprises four datasets that have nearly identical simple statistical properties, yet appear very different when graphed: https://en.wikipedia.org/wiki/Anscombe's_quartet
- Same mean, variance, different distributions.
- Correlation & Covariance: In probability theory and statistics, correlation and covariance are two similar measures for assessing how much two attributes change together.
- Covariance indicates the direction of linear relationship between 2 variables. Correlation indicates both direction and strength of the linear relationship between 2 variables.
correlation(A, B) = covariance(A, B)/(std(A)*std(B))covariance(A, B) = sum((xi - avg(Y)) * (yi - avg(Y)))/N- Correlation is between [-1, 1], covariance is between (-infinity, +infinity)
- Rate vs Proportion: A rate differs from a proportion in that the numerator and the denominator need not be of the same kind and that the numerator may exceed the denominator. For example, the rate of pressure ulcers may be expressed as the number of pressure ulcers per 1000 patient days.
- Bias is the error due to the over-simplicity of the model, tends to lead to underfitting and hard to get high predictive accuracy. Variance is the error due to the over-complex of the model, tends to be highly sensitive to high degrees of variation in the training data and leads to overfitting, could also bring in more noise.
- The total error is lower when both bias and variance are lower. So during parameter tuning, better to find that sweet spot when bias, variance and the error are all lower.
- About variance here, according to above description, if we check multiple models on the same set of data, the difference is called variance. Meanwhile there is model variance, which means the same model showing different results because of the randomness in different data input. These 2 variance can be differentiated by, whether it's same model or multiple model, whether it's multiple dataset or same dataset.


- OLS and Maximum likelihood are the methods used by the respective regression methods to approximate the unknown parameter (coefficient) value. OLS is to linear regression. Maximum likelihood is to logistic regression. Ordinary least square(OLS) is a method used in linear regression which approximates the parameters resulting in minimum distance between actual and predicted values. Maximum Likelihood helps in choosing the the values of parameters which maximizes the likelihood that the parameters are most likely to produce observed data.
- The plot here to compare how OLS and PCA work is also very good: https://stats.stackexchange.com/questions/2691/making-sense-of-principal-component-analysis-eigenvectors-eigenvalues/2700#2700
- OLS minimizes the error between the predicted value and the observations
- PCA minimizes the error orthogonal (perpendicular) to the model line
- Here's more details from the blog post: http://www.cerebralmastication.com/2010/09/principal-component-analysis-pca-vs-ordinary-least-squares-ols-a-visual-explination/
- The plot here to compare how OLS and PCA work is also very good: https://stats.stackexchange.com/questions/2691/making-sense-of-principal-component-analysis-eigenvectors-eigenvalues/2700#2700
- Standard Deviation – It is the amount of variation in the population data. It is given by σ. Standard Error – It is the amount of variation in the sample data. It is related to Standard Deviation as σ/√n, where, n is the sample size, σ is the standandard deviation of the population. A low standard deviation indicates that the data points tend to be close to the mean (also called the expected value) of the set, while a high standard deviation indicates that the data points are spread out over a wider range of values. The standard deviation is the square root of the variance.
- 95% confidence interval does not mean the probability of a population mean to lie in an interval is 95%. Instead, 95% C.I means that 95% of the Interval estimates will contain the population statistic.
- "Margin of Error" is the half width of confidence interval.
- Larger the dataset, narrower the confidence interval is.
- If a sample mean lies in the margin of error range then, it might be possible that its actual value is equal to the population mean and the difference is occurring by chance.
- Difference between z-scores and t-values are that t-values are dependent on Degree of Freedom of a sample, and t-values use sample standard deviation while z-scores use population standard deviation.
- The Degree of Freedom – It is the number of variables that have the choice of having more than one arbitrary value. For example, in a sample of size 10 with mean 10, 9 values can be arbitrary but the 10th value is forced by the sample mean.
- Residual Sum of Squares (RSS) - It can be interpreted as the amount by which the predicted values deviated from the actual values. Large deviation would indicate that the model failed at predicting the correct values for the dependent variable. Regression (Explained) Sum of Squares (ESS) – It can be interpreted as the amount by which the predicted values deviated from the the mean of actual values.
- Residuals is also known as the prediction error, they are vertical distance of points from the regression line
- Co-efficient of Determination = ESS/(ESS + RSS). It represents the strength of correlation between two variables. Correlation Coefficient = sqrt(Co-efficient of Determination), also represents the strength of correlation between two variables, ranges between [-1,1]. 0 means no correlation, 1 means strong positive correlation, -1 means strong neagtive correlation.
-
Probability sampling can be representative, non-probability sampling may not
-
Probability Sampling
- Random sample. (I guess R
sample()is random sampling by default, so that each feature has the same weight) - Stratified sample
- Clustering Sampling - When it's difficult to study the target population spread across a wide area and random sampling won't work well, we divide the data into different clusters. Such as you sample the data in each grade/city/geneder/etc.
- Systematic Sampling - it starts from a random position but choose data sample in certain intervals and the selection is in circular manner, which means once reached to the end of the list, it will go back to the top to do further selection.
- Equal probability method - fixed interval when selecting the next data point.
- Random sample. (I guess R
-
Nonprobability Sampling
- Quota sample
- Purposive sample
- Convenience sample
-
Bias that can occur during sampling
- Selection Bias - sample not representative of the population
- Undercoverage Bias - Some groups of the population are inadquately represented in the sample
- Survivorship Bias - It's a logic error that only choose the sample that supports the conclusion and skip those didn't work. this tend to conclusion error.
-
References
-
Comprehensive and Practical Statistics Guide for Data Science - A real good one!
- Sample Distribution and Population Distribution, Central Limit Theorem, Confidence Interval
- Hypothesis Testing
- ANOVA (Analysis of Variance), continuous and categorical variables, ANOVA also requires data from approximately normally distributed populations with equal variances between factor levels.
- Chi-square test, categorical variables
- Regression and ANOVA, it is important to know the degree to which your model is successful in explaining the trend (variance) in dependent variable. ANOVA helps finding the effectiveness of regression models.
- An example of hypothesis test with chi-square:
- chi-square tests the hypothesis that A and B are independent, that is, there is no correlation between them. Chi-square is used to calculate the correlation between categorical variables
- In this example, you have already calculated chi-square value as 507.93
- B feature has 2 levels, "science-fiction", "history"; A feature has 2 levels, "female", "male". So we can form a 2x2 table. The degree of freedom = (2-1)*(2-1) = 1
- Use the calculator here to calculate significant level, type degree of freedom as 1, probability as 0.001 (you can choose a probability you'd like). The calculated significant level is 10.82756617
- chi-square value 507.93 is much larger than the significant level, so we reject the hypothesis that A, B are independent and not correlated
-
Hypothesis Testing
- https://www.analyticsvidhya.com/blog/2017/01/comprehensive-practical-guide-inferential-statistics-data-science/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- When we want to get more accuracy results from data samples, we often try to:
- Increase sample size
- Test more other random samples
- But what if you don't have time/money/computer memory to do above methods, we can try to calculate random chance probability
- Relevant Basics First
- z-value/z-score: It tells how many standard deviation the observed value is away from mean. For example, z-score = 1.7 indicates that the observed value is 1.7 standard deviation away from mean. Associated with the standard normal distribution only.
z-score = (observed_value - mean)/standard_deviation - p-value: it tells the probability that observed value is away from mean. Therefore, in order to get p-value, you check z-table with the z-score you got. Associated with the standard normal distribution only.
standard deviation of sample means = population standard deviation/sqrt(N), N is the sample size. This is knows as standard error of means. You check this satdard error of means to tell how accurate your random samples that can determind population mean.- Greater the sample size, lower standard error of means, and more accuracy to use the sample mean to determine the population mean. Sample size should be NOT more than 10% of the population when sampling is done without replacement.
- All the samples should be fixed size
- Sample size must be sufficient, >= 30. When the population is skewed or asymmetric, the sample size should be large. If the population is symmetric, then we can draw small samples as well.
- For other distributions,
z-score = (sample_mean - population mean)/sample_standard_deviation = (sample_mean - population mean)/population standard deviation/sqrt(N), therefore you can also get p-value to show the probability. But the precondition is, you know the population standard deviation, population mean
- Significant Level & Confidence - no matter what distribution, finally you get a probability (p-value) of how much the sample mean is higher than population mean (because you use sample mean minus population mean). High probability shows the acceptance of randomness, while low probabilty shows the behaviour differences. With Significant Level, we can decide what is high probability and what is low probability
- For example, with significant level 5%, also known as α level, if the probability you got is less than 5%, it means there is behaviour of difference between 2 population. Then we can say, we have 95% confidence that the sample mean is not driven by randomness, but driven by behaviour difference.
- z-value/z-score: It tells how many standard deviation the observed value is away from mean. For example, z-score = 1.7 indicates that the observed value is 1.7 standard deviation away from mean. Associated with the standard normal distribution only.
- Steps to do Hypothesis Testing
- NULL HYPOTHESIS (H0) - The difference between sample and population mean is due to randomness (also means there is no difference between sample and population)
- ALTERNATIVE HYPOTHESIS (H1)
- After you got the p-value, if it's higher than significant level (say, 5%), reject NULL Hypothesis
- The decision to reject the null hypothesis could be incorrect, it is known as Type I error.
- The decision to retain the null hypothesis could be incorrect, it is know as Type II error.
- One Tail Test - your alternate hypothesis is greater or less than the population mean so it is also known as Directional Hypothesis test
- If you are not sure, it's Two Tail Test/Non Directional Hypothesis. In two tail test,
real significant level for each direction = significant level/2 - In one tail test, we reject the Null hypothesis if the sample mean is either positive or negative extreme any one of them. But, in case of two tail test we can reject the Null hypothesis in any direction (positive or negative).
- reference: https://www.analyticsvidhya.com/blog/2015/09/hypothesis-testing-explained/
-
Non-Parametric Tests
- Parametric tests are used when the information about the population parameters is completely known whereas non-parametric tests are used when there is no or few information available about the population parameters. That is to say, non-parametric tests make no assumption about the data.
- But, if there is a parametric solution to the problem, using non-parametric tests could lead to much lower accuracy
- Pros for non-parametric tests:
- When there is no parametric test solution, using non-parametric test is better, and it works even when the data sample is small
- It also works for all data types, such as categorical, ordinal, interval or data with outliers
- Cons for non-parametric tests:
- Because non-parametric methods won't reduce the problem of estimating f to a small number of params as parametric methods do, so in order to achieve higher accuracy, non-parametric methods need much larger number of observations
- Critical value tables for non-parametric tests are not inlcuded in many software packages...
- Steps to do Hypothesis Testing with non-parametric tests
- H0 (NULL Hypothesis): There is no significant difference between sample mean and population mean
- H1 (ALTERNATIVE Hypothesis): There is a significant difference between sample mean and population mean
- Set significant level, decide it's one-tail or two-tail problem. Decide decision rule (when t reject null hypothsis)
- Test Statistics - In non-parametric tests, the sample is converted into ranks and then ranks are treated as a test statistic
- Compare test statistics and decision rule, to decide reject/accept null hypothesis
- Different Types of non-parametric tests
- Mann Whitney U test/Mann Whitney Wilcoxon test/Wilcoxon rank sum test
- It is an alternative to independent sample t-test
- You have 2 samples, sample one has size n1, sample two has size n2. R1, R2 are the sum of ranks for each sample respectively.
- In order to calculate R1, R2, you arrange the values of both samples together, in ascending order (from left to right), and you give them 1,2,3...,(n1+n2) index.
- For those values such as X that appeared multiple times, say p times, you use the sum of index of X values devided by p (
sum(index_of_this_same_value)/p) as the new index for each X, in this way, you can make sure the sum of all the final idex equals ton*(n+1)/2, it also equals to (1+2+3+...+n)
- For those values such as X that appeared multiple times, say p times, you use the sum of index of X values devided by p (
- In order to calculate R1, R2, you arrange the values of both samples together, in ascending order (from left to right), and you give them 1,2,3...,(n1+n2) index.
U1 = n1*n2 + n1*(n1+1)/2 - R1,U2 = n1*n2 + n2*(n2+1)/2 - R2U = min(U1, U2), U1+U2 = n1n2. U lies in range (0, n1n2). 0 means the 2 samples are totally different from each other, while n1*n2 indicates some relationship between the 2 groups.- Find critical value here: http://ocw.umb.edu/psychology/psych-270/other-materials/RelativeResourceManager.pdf
- If
U <= critical value, reject H0, else accept H0
- Wilcoxon Sign-Rank Test
- There are n values in each group. You calculate the difference between the 2 values that share the same index in both groups
- Then order the difference by ignoring their positive/neagtive sign. Ranking them, using the same method used in Mann Whitney U test, that for same absolute value, the rank is the average of their initial ranks
- Now add their original positive/negative sign to the ranks
W1 = sum(positive ranks),W2 = abs(sum(neagtive ranks))W = min(W1, W2)- Choose critical value based on α and one-tail/two-tail here: http://www.stat.ufl.edu/~winner/tables/wilcox_signrank.pdf
- If
W <= critical valuereject H0, else accept H0
- Sign Test
- This method is quite similar to Wilcoxon Sign-Rank Test. The difference is, after you got signed ranks, you ignore the values, but only focus on +, - signs.
W1 = number of + sign,W2 = number of - signW = min(W1, W2)- Still choose critical value based on α and one-tail/two-tail here: http://www.stat.ufl.edu/~winner/tables/wilcox_signrank.pdf
- If
W <= critical valuereject H0, else accept H0
- Kruskal-Wallis Test
- This test is extremely useful when you are dealing with more than 2 independent groups and it compares median among k populations
- This test is an alternative to One way ANOVA when the data violates the assumptions of normal distribution and when the sample size is too small.
- The way you do rankings is almost the same as the above methods
H = (12/n*(n+1) * sum(pow(R1, 2)/n1 + pow(R2, 2)/n2 +... + pow(Rk, 2)/nk)) - 3*(n-1), n is the total sample size, k is the number of samples, Ri is the sum of ranks of ith sample, ni is the sample size of ith sample- Table of critical values: http://webspace.ship.edu/pgmarr/Geo441/Tables/Kruskal-Wallis%20H%20Table.pdf
- If
H >= critical value, reject H0, else accept H0
- Spearman Rank Correlation
- If there is correlation between 2 datasets, use this method
- H0: There is no relation between the 2 groups; H1: there is relation between the 2 groups
- Spearman Rank Correlation should be used to check the strength and direction of the correlation. Spearman rank correlation is a non-parametric alternative to Pearson correlation coefficient.
- I will use built-in packages or online tools to calculate this value...
- Check critical value here: http://webspace.ship.edu/pgmarr/Geo441/Tables/Spearman%20Ranked%20Correlation%20Table.pdf
degree of freedom = n-2, n is the sample size. If yourcalculated result >= critical value, reject H0, else accept
- Mann Whitney U test/Mann Whitney Wilcoxon test/Wilcoxon rank sum test
- reference: https://www.analyticsvidhya.com/blog/2017/11/a-guide-to-conduct-analysis-using-non-parametric-tests/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- For Spearman Rank Correlation, it seems that the critical value at freedom of degree 8 with α = 0.025 (2 tail) is larger than 0.67, so it should accept the null hypothesis
-
Probability cheat sheet: http://www.cs.elte.hu/~mesti/valszam/kepletek
-
Likelihood vs Probability: http://mathworld.wolfram.com/Likelihood.html
- Likelihood is the hypothetical probability that a past event would yield a specific outcome.
- Probability refers to the occurrence of future events, while Likelihood refers to past events with known outcomes.
-
Probability basics with examples
- binonial distribution: a binomial distribution is the discrete probability distribution of the number of success in a sequence of n independent Bernoulli trials (having only yes/no or true/false outcomes).
- The normal distribution is perfectly symmetrical about the mean. The probabilities move similarly in both directions around the mean. The total area under the curve is 1, since summing up all the possible probabilities would give 1.
- Area Under the Normal Distribution
- Z score: The distance in terms of number of standard deviations, the observed value is away from the mean, is the standard score or the Z score. Observed value = µ+zσ [µ is the mean and σ is the standard deviation]
- Find Z Table here
-
Very Basic Conditional Probability and Bayes Theorem
- Independent, Exclusive, Exhaustive events
- Each time, when it's something about statistics pr probability, I will still read all the content to guarantee that I won't miss anything useful. This one is basic but I like the way it starts from simple concepts, using real life examples and finally leads to how does Bayes Theorem work. Although, there is an error in formula
P (no cancer and +) = P (no cancer) * P(+) = 0.99852*0.99, it should be0.99852*0.01 - There are some major formulas here are important to Bayes Theorem:
*
P(A|B) = P(A AND B)/P(B)P(A|B) = P(B|A)*P(A)/P(B)P(A AND B) = P(B|A)*P(A) = P(A|B)*P(B)P(b1|A) + P(b2|A) + .... + P(bn|A) = P(A)
-
Dispersion - In statistics, dispersion (also called variability, scatter, or spread) is the extent to which a distribution is stretched or squeezed. Common examples of measures of statistical dispersion are the variance, standard deviation, and interquartile range.
-
Common Formulas
- Examples: https://www.analyticsvidhya.com/blog/2017/05/41-questions-on-statisitics-data-scientists-analysts/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- About z-score
- When looking for probability, calculate z score first and check the value in the Z table, that value is the probability
- Observed value = µ+zσ [µ is the mean and σ is the standard deviation]
- Standard Error = σ/√N, [N is the number of Sample]; z = (Sample Mean - Population Mean)/Standard Error
- Find Z Table, t-distribution, chi-distribution here
- About t-score
- When compare 2 groups, calculate t-score
- t-statistic = (group1 Mean - group2 Mean)/Standard Error
- degree of freedom (df), if there are n sample, df=n-1 * t table with df, 1-tail, 2-tails and confidence level, compare your t-statistic with the relative value in this table, and decide whether to reject null hypothesis
- percentage of variability = t-statistic^2/(t-statistic^2 + degree of freedom) = correlation_coefficient ^2, so coefficient of determination equals to "percentage of variability"
- About F-statistic
- F-statistic is the value we receive when we run an ANOVA test on different groups to understand the differences between them.
- F-statistic = (sum of squared error for between group/degree of freedom for between group)/(sum of squared error for within group/degree of freedom for within group), as you can see from this formula, it cannot be negative
- Correlation
- Methods to calculate correlations between different data types: https://www.analyticsvidhya.com/blog/2016/01/guide-data-exploration/
- Formula to calculate correlation between 2 numerical variables (Question 28): https://www.analyticsvidhya.com/blog/2017/05/41-questions-on-statisitics-data-scientists-analysts/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Correlation between the features won’t change if you add or subtract a constant value in the features.
- Significance level = 1- Confidence level
- Mean Absolute Error = the mean of absolute errors
- Normalization Methods
- min-max normalization = (x - min)/(max - min)
- z-score normalization = (x - mean)/standard deviation
- decimal scaling = x/1000, x/100, etc (depends on how could you make the values into [0,1] range)
-
Linear regression line attempts to minimize the squared distance between the points and the regression line. By definition the ordinary least squares (OLS) regression tries to have the minimum sum of squared errors. This means that the sum of squared residuals should be minimized. This may or may not be achieved by passing through the maximum points in the data. The most common case of not passing through all points and reducing the error is when the data has a lot of outliers or is not very strongly linear.
-
Person vs Spearman: Pearson correlation evaluated the linear relationship between two continuous variables. A relationship is linear when a change in one variable is associated with a proportional change in the other variable. Spearman evaluates a monotonic relationship. A monotonic relationship is one where the variables change together but not necessarily at a constant rate.
-
Coefficient
- Does similar work as correlation
- Tutorial to use it in Linear Regression: https://www.analyticsvidhya.com/blog/2017/06/a-comprehensive-guide-for-linear-ridge-and-lasso-regression/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
Linear Algebra with Python calculations
- reference: https://www.analyticsvidhya.com/blog/2017/05/comprehensive-guide-to-linear-algebra/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- It talkes about those planes in linear algebra, matrix calculation
- What I like most is Eigenvalues and Eigenvectors part, because it's talking about how they related to machine learning. So Eigenvalues and Eigenvectors can be used in dimensional reduction such as PCA and reduce info loss.
- Singular Value Decomposition (SVD), used in removig redundant features, can be considered as a type of dimensional reduction too, but doesn't change the rest data as PCA does
-
To comapre the similarity between 2 curves
- Try to compare from these perspectives:
- Distance
- Shape
- Size of the Area in between
- Kolmogorov–Smirnov test - distance based
- its null hypothesis this, the smaple is drawn from the reference graph
- So, if the generated p-value is smaller than the threshold, reject null hypothesis, which means the 2 curves are not similar
- Dynamic Time Wrapping (DTW) - distance based
- Check the consistency of Peak and non-peak points of the 2 curves - shape based
- Try to compare from these perspectives:
-
Simulation Methods
- Monte Carlo Simulation: http://www.palisade.com/risk/monte_carlo_simulation.asp
- It can simulate all types of possible outcomes and probability of each outcome
- Monte Carlo Simulation: http://www.palisade.com/risk/monte_carlo_simulation.asp
-
Saddle Points
- The saddle point will always occur at a relative minimum along one axial direction (between peaks) and at a relative maximum along the crossing axis. Saddle Point Wiki
- How to Escape Saddle Point Efficiently
- Strict saddle points vs Non-strict saddle points: non-strict saddle points can be flat in the valley, strict saddle points require that there is at least one direction along which the curvature is strictly negative
- GD with only random initialization can be significantly slowed by saddle points, taking exponential time to escape. The behavior of PGD (projected GD) is strikingingly different — it can generically escape saddle points in polynomial time.
- Difference between Projected Gradient Descent (PGD) and Gradient Descent (GD)
-
How to calculate Confidence: http://www.stat.yale.edu/Courses/1997-98/101/confint.htm
- For Unknown Population Mean and Known Standard Deviation
- For Unknown Population Mean and Unknown Standard Deviation - t-distribution, standard error (SE)
- Both assumes the distribution is bell shape (normal distribution or t-distribution)
- When there are only 2 datasets to compre, we can use t-distribution, but when there are more than 2, t-distribution won't handle it. Try ANOVA.
-
ANOVA
- It compares samples based on means. It can handle 2+ samples. By comparing the means, ANOVA checks the impact of one or more factors.
- When there are just 2 samples, t-distribution and ANOVA get same results
- Terminology
- Grand Mean µ: The mean of all sample means
- Null Hypothesis in ANOVA is valid, when all the sample means are equal, or they don't have any significant difference
- Alternative Hypothesis is valid when at least one of the sample mean is different from others. But you ay need to use other methods to tell which is the different sample mean
- Between-group variability
- It tells the variation between the distributions of samples. If the distributions are close or overlap, the grand mean will be similar to sample means; but if the distributions are further away, the difference between the grand mean and the sample means can be large
(n1*pow(µ1-µG,2) + n2*pow(µ2-µG,2) + n3*pow(µ3-µG,2) + .... + nk*pow(µk-µG,2))/(k-1) = SSbetween/(k-1)- To calculate Between-group variability, is quite similar to calculate standard deviation/variance
- How to calculate standard deviation: https://www.youtube.com/watch?v=pFGcMIL2NVo
- Variance = pow(standard deviation, 2)
- The difference between calculating standard deviation and Between-group variability
- There are weights for each pow((µi-µG),2), and the weight is ni, the sample size of group i. µi is the sample mean for group i, and µG is the grand mean
- The sum of those squared sample mean difference are divided by degrees of freedom. If there are k (µi-µG), then the degree of freedom is
k-1 - Finally, you don't need to calculate squared root
- Within-group variability
- It's about the variation in each sample, and sum them up. This is because a group of samples that overlap a lot and can have the same sample mean & grand mean with another group of samples which have no oberlap. Between-group variability cannot help, we need within-group variability too.
sum(pow(xij-µj, 2))/(N-k) = SSwithin/(N-k), µj is the sample mean of sample j, xij is the ith value in sample j.N-kis the degree of freedom, N is the sum of sizes, k is the number of samples. You can think it's minus 1 from each sample, so that's k
- F-Ratio/F-Statistics
- It measures whether the means of different samples are significantly different or not. Lower F-Ration indicates more similar the samples and we cannot reject the null hypothesis
F = Between group variability / Within group variability- This tells us, the larger the between-group variability, the more likely those samples are different
- When
F-Ratio > F-critical α, which means it's lands in the critical region, we reject null hypothesis, and say the differences between samples are significant. Also, when you are using tools such as Excel, it generates p-value at the same time, if this p-value is lower than α, we reject null hypothesis too - For different α, F-critical value can be found here: http://www.socr.ucla.edu/applets.dir/f_table.html
- df means degree of freedom here. df1 is between group degree of freedom, df2 is within group degree of freedom
- Unlike z-distribution, t-distribution, F-distribution does not have any negative values
- One-way ANOVA
- The limitation of one-way ANOVA: cannot tell which sample is different
- To find the different group, you compare each pair of the groups
eta square = SSbetween/SStotal,SStotoal = SSwithin * (N-k)/(N-1), eta square is used to measure how much between group difference contributes to the variability. It also helps tell whether the independent variablies really have an impact on dependent variable- Make sure there is only one variable affects the results
- Two-Way ANOVA
- When there can be 2 factors/variables affect the results, this ANOVA method measures which variable affects more
- 2 null hypothesis, each for one variable, 1 alternative hypothesis
- You compare F-ratio & F-critical value or p-value & α value, to decide whether to reject the 2 null hypothesis
- There is also F-ratio and F-critical value for interaction, to measure whether there is combined effect from the 2 variables. When F-ratio < F-critical value, no combined effect
- Multi-variate ANOVA (MANOVA)
- Works when there are multiple variables
- It cannot tell which variable affects the results, so you need multiple one-way ANOVA summary to figure out the variable that affects the result
- Bonferroni approach: Methods used to find samples that represent the population
- Tukey’s HSD : https://www.sfu.ca/~jackd/Stat302/Wk04-2_Full.pdf
- Least significant difference test (LSD): https://www.utd.edu/~herve/abdi-LSD2010-pretty.pdf
- Reference: https://www.analyticsvidhya.com/blog/2018/01/anova-analysis-of-variance/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- The author is giving detailed Excel methods
- In its one-way ANOVA, finally the author found group A is quite different from group B, C. But I don't think this difference could prove constant music can really improve the performance. If students in group A are much better students then group B, C, group A can still be quite different. I think the final result only indicates group A is quite different from group B, C. If they want to prove constant music could really improve performance, how about ask the same group, say group A, to test under variable music/no sound situation first, then test in constant music situation and check how different the results are. In a word, try to make sure there is only one variable
Machine Learning Algorithms
-
KNN with R example: https://www.analyticsvidhya.com/blog/2015/08/learning-concept-knn-algorithms-programming/
- KNN unbiased and no prior assumption, fast
- It needs good data preprocessing such as missing data imputing, categorical to numerical
- k normally choose the square root of total data observations
- It is also known as lazy learner because it involves minimal training of model. Hence, it doesn’t use training data to make generalization on unseen data set.
- Distance Methods used in KNN: https://github.com/hanhanwu/readings/blob/master/knn_distance_algs.pdf
- There are definitions of 11 distance methods
- They have compared 8 datasets with 11 distance methods and found:
- Hamming and Jaccard perform worst since these 2 methods will be affected by the ratio of the members of each class, while other methods won't be affected
- The top 6 distance methods a they tried in KNN are: City-block, Chebychev, Euclidean, Mahalanobis, Minkowski, Standardized Enuclidean techniques
- Besides, there is also Manhattan distance, scaled Manhattan distance. The paper here, page 10: https://github.com/hanhanwu/readings/blob/master/I%20can%20be%20You-%20Questioning%20the%20use%20of%20Keystroke%20Dynamics%20as%20Biometrics.pdf
- Python SciPy distance methods: https://docs.scipy.org/doc/scipy-0.15.1/reference/generated/scipy.spatial.distance.cdist.html
- Check my code here: https://github.com/hanhanwu/Basic_But_Useful/blob/master/python_dataframe.py
get_scaled_dist()
- The distance methods can help calculate the consistency, the paper above 10, 11
- When it comes to information retrieval, KNN could help classification, but can be slow. KDTree can be faster, if it's not the worst case.
-
SVM with Python example: https://www.analyticsvidhya.com/blog/2015/10/understaing-support-vector-machine-example-code/?utm_content=buffer02b8d&utm_medium=social&utm_source=facebook.com&utm_campaign=buffer
-
Basic Essentials of Some Popular Machine Learning Algorithms with R & Python Examples: https://www.analyticsvidhya.com/blog/2015/08/common-machine-learning-algorithms/?utm_content=buffer00918&utm_medium=social&utm_source=facebook.com&utm_campaign=buffer
- Linear Regression: Y = aX + b, a is slope, b is intercept. The intercept term shows model prediction without any independent variable. When there is only 1 independent variable, it is Simple Linear Regression, when there are multiple independent variables, it is Multiple Linear Regression. For Multiple Linear Regression, we can fit Polynomial Courvilinear Regression.
- When to use Ridge or Lasso: In presence of few variables with medium / large sized effect, use lasso regression. In presence of many variables with small / medium sized effect, use ridge regression. Lasso regression does both variable selection and parameter shrinkage, whereas Ridge regression only does parameter shrinkage and end up including all the coefficients in the model. In presence of correlated variables, ridge regression might be the preferred choice. Also, ridge regression works best in situations where the least square estimates have higher variance.
- Logistic Regression: it is classification, predicting the probability of discrete values. It chooses parameters that maximize the likelihood of observing the sample values rather than that minimize the sum of squared errors (like in ordinary regression).
- Decision Tree: serves for both categorical and numerical data. Split with the most significant variable each time to make as distinct groups as possible, using various techniques like Gini Gain, Information Gain, Chi-square. A decision tree algorithm is known to work best to detect non – linear interactions. The reason why decision tree failed to provide robust predictions because it couldn’t map the linear relationship as good as a regression model did.
- Gini Gain vs Information Gain vs Gain Ratio
- They are all attribute selection methods in decision tree
- Gini Gain forces the resulting tree to be binary
Gini Impurity = sum(P(i) * (1 - P(i))), i is class i- Gini impurity is the probability of a random sample being classified correctly if you randomly pick a label according to the distribution in the branch.
Gini Gain = Gini_Impurity_All - Gini_Impurity_AttributeGini_Impurity_Allcalculates gini impurity at dependent variable level without checking any attributeGini_Impurity_Attributecalculates gini impurity for that attribute, so the dependent variable counts are counted under each value group of the attribute
- When the split is pure, it's 0 Gini Impurity
- Information Gain allows multiway splits.
Entropy = -sum(P(i)*log(P(i), 2)), i is class i- Entropy calculates how lack of purity the labels are after the split. Information gain is the opposite, it represents the purity of labels after the split.
Information Gain = Entropy_All - Entropy_Attribute = 1 - EntropyEntropy_Allcalculates entropy at dependent variable level without checking any attributeEntropy_Atributecalculates entropy for that attribute, so the dependent variable counts are counted under each value group of the attribute
- Information Gain has bias towards the attributes that have larger amount of different values, since this will lead to higher number of branches and each branch is pure. This could make the algorithm useless. To overcome this problem, Gain Ratio has been used.
Gain Ratio = Information Gain of attribute/ Split Entropy of attribute- Comparing Entropy for attribute A and Split Entropy for attribute A:
Entropy(A) = -sum(P(Dj|D)*log(P(D), 2))Split_Entropy(A) = -sum((Dj|D)*log(P(Dj|D), 2))
- About Entropy
- We all know that formula,
-sum(p(i)*log(p(i), 2)), and this is calculated for each group/category/etc. in the whole dataset - Sometimes, we need to compare entropy for different datasets, and in each dataset, we have multiple groups, then here comes normalized entropy, for each group,
-sum(p(xi)*log(p(xi), 2)/log(n, 2)), n means the total records in this group, NOT overall records of the dataset
- We all know that formula,
- Besides entropy and gini can be used to split decision trees, chi square can be used for the split of the categorical variables in the decision tree. Higher chi square, higher the different between partent and child node and higher homogeneity.
- Gini Gain vs Information Gain vs Gain Ratio
- SVM: seperate groups with a line and maximize the margin distance. Good for small dataset, especially those with large number of features
- The effectiveness of SVM depends on Selection of Kernel, Kernel Parameters and Soft Margin Parameter C, they can also help reduce errors and overfitting
- The larger C parameter, the heavier penality for misclassification. So when C param is set to infinite, no room for error, optimal hyperplane (if exists) should seperate the data completely
- Gamma value indicates how far the influence points to the hyperplane. Higher the Gamma value is, closer the influence points are
- Naive Bayes: the assumption of equally importance and the independence between predictors. Very simple and good for large dataset, also majorly used in text classification and multi-class classification. Likelihood is the probability of classifying a given observation as 1 in presence of some other variable. For example: The probability that the word ‘FREE’ is used in previous spam message is likelihood. Marginal likelihood is, the probability that the word ‘FREE’ is used in any message.
- KNN: can be used for both classification and regression. Computationally expensive since it stores all the cases. Variables should be normalized else higher range variables can bias it. Data preprocessing before using KNN, such as dealing with outliers, missing data, noise
- K-Means
- Random Forest: bagging, which means if the number of cases in the training set is N, then sample of N cases is taken at random but with replacement. This sample will be the training set for growing the tree. If there are M input variables, a number m<<M is specified such that at each node, m variables are selected at random out of the M and the best split on these m is used to split the node. The value of m is held constant during the forest growing. Each tree is grown to the largest extent possible. There is no pruning. Random Forest has to go with cross validation, otherwise overfitting could happen.
- PCA: Dimensional Reduction, it selects fewer components (than features) which can explain the maximum variance in the data set, using Rotation. Personally, I like Boruta Feature Selection. Filter Methods for feature selection are my second choice. Remove highly correlated variables before using PCA
- GBM (try C50, XgBoost at the same time in practice)
- Difference between Random Forest and GBM: Random Forest is bagging while GBM is boosting. In bagging technique, a data set is divided into n samples using randomized sampling. Then, using a single learning algorithm a model is build on all samples. Later, the resultant predictions are combined using voting or averaging. Bagging is done is parallel. In boosting, after the first round of predictions, the algorithm weighs misclassified predictions higher, such that they can be corrected in the succeeding round. This sequential process of giving higher weights to misclassified predictions continue until a stopping criterion is reached.Random forest improves model accuracy by reducing variance (mainly). The trees grown are uncorrelated to maximize the decrease in variance. On the other hand, GBM improves accuracy my reducing both bias and variance in a model.
-
Online Learning vs Batch Learning: https://www.analyticsvidhya.com/blog/2015/01/introduction-online-machine-learning-simplified-2/
-
Optimization - Genetic Algorithm
- More about Crossover and Mutation: https://www.researchgate.net/post/What_is_the_role_of_mutation_and_crossover_probability_in_Genetic_algorithms
-
Survey of Optimization
- Page 10, strength and weakness of each optimization method: https://github.com/hanhanwu/readings/blob/master/SurveyOfOptimization.pdf
-
Optimization - Gradient Descent
- Reference: https://www.analyticsvidhya.com/blog/2017/03/introduction-to-gradient-descent-algorithm-along-its-variants/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Challenges for gradient descent
- data challenge: cannot be used on non-convex optimization problem; may end up at local optimum instead of global optimum; may even not an optimal point when gradient is 0 (saddle point)
- gradient challenge: when gradient is too small or too large, vanishing gradient or exploding gradient could happen
- implementation chanllenge: memory, hardware/software limitations
- Type 1 - Vanilla Gradient Descent
- "Vanilla" means pure here
update = learning_rate * gradient_of_parametersparameters = parameters - update
- Type 2 - Gradient Descent with Momentum
update = learning_rate * gradientvelocity = previous_update * momentumparameter = parameter + velocity – update- With
velocity, it considers the previous update
- Type 3 - ADAGRAD
- ADAGRAD uses adaptive technique for learning rate updation.
grad_component = previous_grad_component + (gradient * gradient)rate_change = square_root(grad_component) + epsilonadapted_learning_rate = learning_rate * rate_changeupdate = adapted_learning_rate * gradientparameter = parameter – updateepsilonis a constant which is used to keep rate of change of learning rate
- Type 4 - ADAM
- ADAM is one more adaptive technique which builds on adagrad and further reduces it downside. In other words, you can consider this as momentum + ADAGRAD.
adapted_gradient = previous_gradient + ((gradient – previous_gradient) * (1 – beta1))gradient_component = (gradient_change – previous_learning_rate)adapted_learning_rate = previous_learning_rate + (gradient_component * (1 – beta2))update = adapted_learning_rate * adapted_gradientparameter = parameter – update
- Tips for choose models
- For rapid prototyping, use adaptive techniques like Adam/Adagrad. These help in getting quicker results with much less efforts. As here, you don’t require much hyper-parameter tuning.
- To get the best results, you should use vanilla gradient descent or momentum. gradient descent is slow to get the desired results, but these results are mostly better than adaptive techniques.
- If your data is small and can be fit in a single iteration, you can use 2nd order techniques like l-BFGS. This is because 2nd order techniques are extremely fast and accurate, but are only feasible when data is small enough
-
Factorization Machines
- Large dataset can be sparse, with Factorization, you can extract important or hidden features
- With a lower dimension dense matrix, factorization could represent a similar relationship between the target and the predictors
- The drawback of linear regression and logistic regression is, they only learn the effects of all features individually, instead of in combination
- For example, you have
FieldsColor, Category, Temperature, andFeaturesPink, Ice-cream, Cold, each feature have different values- Linear regression:
w0 + wPink * xPink + wCold * xCold + wIce-cream * xIce-cream - Factorization Machines (FMs):
w0 + wPink * xPink + wCold * xCold + wIce-cream * xIce-cream + dot_product(Pink, Cold) + dot_product(Pink, Ice-cream) + dot_product(Cold, Ice-cream)- dot-product:
a.b = |a|*|b|cosθ, when θ=0, cosθ=1 and the dot product reaches to the highest value. In FMs, dor product is used to measure the similarity dot_product(Pink, Cold) = v(Pink1)*v(Cold1) + v(Pink2)*v(Cold2) + v(Pink3)*v(Cold3), here k=3. This formula means dot product for 2 features in size 3
- dot-product:
- Field-aware factorization Machines (FFMs)
- Not quite sure what does "latent effects" meantioned in the tutorial so far, but FFMs has awared the fields, instead of using
dot_product(Pink, Cold) + dot_product(Pink, Ice-cream) + dot_product(Cold, Ice-cream), it's using Fields here,dot_product(Color_Pink, Temperature_Cold) + dot_product(Color_Pink, Category_Ice-cream) + dot_product(Temperature_Cold, Category_Ice-cream), Color & Temperature, Color & category, Temperature & Category
- Not quite sure what does "latent effects" meantioned in the tutorial so far, but FFMs has awared the fields, instead of using
- Linear regression:
xLearnlibrary- Sample input (has to be this format, libsvm format): https://github.com/aksnzhy/xlearn/blob/master/demo/classification/criteo_ctr/small_train.txt
- Detailed documentation about parameters, functions: http://xlearn-doc.readthedocs.io/en/latest/python_api.html
- Personally, I think this library is a little bit funny. First of all, you have to do all the work to convert sparse data into dense format (libsvm format), then ffm will do the work, such as extract important features and do the prediction. Not only how it works is in the blackbox, but also it creates many output files during validation and testing stages. You's better run evrything through terminal, so that you can see more information during the execution. I was using IPython, totally didin't know what happened.
- But it's fast! You can also set multi-threading in a very easy way. Check its documentation.
- My code: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/Factorization_Machines.ipynb
- My code is better than reference
- Reference: https://www.analyticsvidhya.com/blog/2018/01/factorization-machines/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
Data Visualization
-
Previous Visualization collections, check "VISUALIZATION" section: https://github.com/hanhanwu/Hanhan_Data_Science_Resources/blob/master/README.md
-
Readings
- Psychology of Intelligence Analysis: https://www.cia.gov/library/center-for-the-study-of-intelligence/csi-publications/books-and-monographs/psychology-of-intelligence-analysis/PsychofIntelNew.pdf
- How to lie with Statistics: http://www.horace.org/blog/wp-content/uploads/2012/05/How-to-Lie-With-Statistics-1954-Huff.pdf
- The Signal and the Noise (to respect the author): https://www.amazon.com/Signal-Noise-Many-Predictions-Fail-but/dp/0143125087/ref=sr_1_1?ie=UTF8&qid=1488403387&sr=8-1&keywords=signal+and+the+noise
- Non-designer's design book: https://diegopiovesan.files.wordpress.com/2010/07/livro_-_the_non-designers_desi.pdf
-
Python LIME - make machine learning models more readable
- The tool can be used for both classification and regression. The reason I put it here is because it can show feature importance even for blackbox models. In industry, the interpretability can always finally influence whether you can apply the more complex methods that can bring higher accuracy. Too many situations that finally the intustry went with the most simple models or even just intuitive math models. This tool may help better intrepretation for those better models.
- Open source: https://github.com/marcotcr/lime
- My code: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/Better4Industry/lime_interpretable_ML.ipynb It seems that GitHub cannot show those visualization I have created in IPython. But you can check LIME GitHub Examples LIME requires data input to be numpy array, it doesn't support pandas dataframe yet. So that's why you can see in my code, I was converting the dataframe, lists all to numpy arraies.
-
NLP Visualization
- On Jan 20, 2017, SFU Linguistics Lab invited an UBC researcher to show NLP data visualization, which is very interesting. By doing topic modeling, graph base clustering, they are able to categorize large amount of comments and opinions into groups, by using interactive visualization, the tools they developed will help readers read online comments in a more efficient way.
- ConVis: https://www.cs.ubc.ca/cs-research/lci/research-groups/natural-language-processing/ConVis.html
- MultiConVis: https://www.cs.ubc.ca/cs-research/lci/research-groups/natural-language-processing/MultiConVis.html
-
Python Bokeh, an open source data visualization tool (its presentation target is web browser, but I think Tableau and d3 all could do this): https://www.analyticsvidhya.com/blog/2015/08/interactive-data-visualization-library-python-bokeh/?utm_content=buffer58668&utm_medium=social&utm_source=plus.google.com&utm_campaign=buffer
-
Tableau Resources
- Reference Guide: http://www.dataplusscience.com/TableauReferenceGuide/
- How to use Tablea "Pages" to create animation: https://www.analyticsvidhya.com/blog/2020/06/animated-data-visualization-tableau-5-minutes/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- How to show a single value in the value range: https://www.analyticsvidhya.com/blog/2020/07/visualize-a-single-value-against-others-in-tableau/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Having multiple data sources
- If current sheet needs only 1 table but you have multiple tables shown as the data source, then edit variables under the table you need for this sheet, tableau will recognize which table you need for current sheet
- How to create drill down from one sheet to another: https://community.tableau.com/ideas/4119
- Under "Dashboard", click "Actions"
- Advanced Highlight: http://onlinehelp.tableau.com/current/pro/desktop/en-us/actions_highlight_advanced.html
- Top N within the Group: https://kb.tableau.com/articles/howto/finding-the-top-n-within-a-category
- Having 1+ pills in Color: http://drawingwithnumbers.artisart.org/measure-names-on-the-color-shel/
- Mark Labels: http://onlinehelp.tableau.com/current/pro/desktop/en-us/annotations_marklabels_showhideindividual.html
- Show or hide labels: http://paintbynumbersblog.blogspot.ca/2013/08/a-quick-tableau-tip-showing-and-hiding.html
- Filter and parameter: https://www.quora.com/What-is-the-difference-between-filters-and-parameters-in-a-tableau-What-is-an-explanation-of-this-scenario
- Tableau detailed user guide on parameter: http://onlinehelp.tableau.com/current/pro/desktop/en-us/help.html#parameters_swap.html
- Logincal function: http://onlinehelp.tableau.com/current/pro/desktop/en-us/functions_functions_logical.html
- Tableau functions: http://onlinehelp.tableau.com/current/pro/desktop/en-us/functions.html
- Combine lines in one axis
- Right click one of the values and choose "Dual Axis"
- Right click one of the axis, and choose "Synchronize Axis"
- If this one got disabled, convert the data format into the same format
- Some Guidance: https://www.analyticsvidhya.com/blog/2018/01/tableau-for-intermediate-data-science/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Dual Axis
- Create sets and combined sets
- Aggregate + Group by + Clustering + Clustering Distribution + Coloring clusters
- For example, you need to generate the average prices group by product categories, then you want to generate multiple groups using the price range, finally check the distribution of each group
- In the first sheet, you put product_category as ROWS, price as Columns and get AVG. Then click Analytics tab form the left bar, select clustering, Tableau will use k-means, and you can define the number of clusters you want. It works very well each time I tried.
- Drag your clusters to Dimensions (categorical data in tableau).
- In your second sheet, now you have that clusters as a piece of data, you know how to create distribution
- To color your clusters, you can create group or create calculation field, then put this new variable in Color
- Add a clustering tutorial here: https://www.youtube.com/watch?v=um-puo3jeVU
- One thing I noticed about Tableau clustering is, even when you can use 2+ features to do the clustering, but the plot will just be 2D there, you cannot see how other features affact the clusters, however you may realize for some dots, they are affected by other features not shown in the plot.
- Motion Chart: https://www.analyticsvidhya.com/blog/2018/03/tableau-for-advanced-users-easy-expertise-in-data-visualisation/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
Jigsaw - Data Visualization for text data
- Tutorial Videos (each video is very short, good): http://www.cc.gatech.edu/gvu/ii/jigsaw/tutorial/
- Jigsaw manual: http://www.cc.gatech.edu/gvu/ii/jigsaw/tutorial/manual/#initiating-session
-
Gephi
- It create interactive graph-network visualization
- Tutorials: https://gephi.org/users/
- This is a sample data input, showing what kind of data structure you need for visualizing network in Grphi, normally, 2 files, one for Nodes one for Edges: https://github.com/hanhanwu/Hanhan_Data_Science_Resources2/blob/master/gephi%20data%20set.zip
- With the dataset I give you here, you will be able to find girls dinning group at school and make assumptions about how rumor spreaded (network is so scary, right?)
- Here is what I listed about the advantages of using Gephi for network visualization, compared with writing python visualization: https://github.com/hanhanwu/Hanhan_Data_Science_Resources2/blob/master/gephi.png
- But something is wrong with the Gephi on my machine.. I don't have partition or ranking settings and cannot choose dirested graph and so on...
- However, seeing the changes of those vosualization with different graph algorithm is interesting, for example, Force Atlas 2: https://github.com/gephi/gephi/wiki/Force-Atlas-2
-
MicrosoStrategy - Visual Analytics Course List: https://www.microstrategy.com/us/services/education/course-list#filter-role:path=default|filter-platform:path=default|filter-version:path=._10_5|filter-certification:path=default|sort-course-number:path~type~order=.card-corner~text~asc
-
Python Elastic Search & Kibana for data visualization: https://www.analyticsvidhya.com/blog/2017/05/beginners-guide-to-data-exploration-using-elastic-search-and-kibana/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- I still prefer R or Spark for visualized data exploration, if you care about the speed. otherwise, tableau
- "Elastic Search is an open source, RESTful distributed and scalable search engine. Elastic search is extremely fast in fetching results for simple or complex queries on large amounts of data (Petabytes) because of it’s simple design and distributed nature. It is also much easier to work with than a conventional database constrained by schemas, tables."
- The tutorial prevides the method to indexing the data for Elastic Search
-
My d3 Practice
- Dask - Machine Learning in Parallel
- It copies many functions from numpy, sklearn, pandas and even Spark, aiming at allow you to do parallel data science work.
- Dask Documentation; http://dask.pydata.org/en/latest/
- My code: https://github.com/hanhanwu/Hanhan_Data_Science_Practice/blob/master/try_dask.ipynb
- Cannot say I'm a big fan of Dask now.
- For data preprocessing, it's no better than using pandas and numpy, since they are much faster than dask and have more functions. I tried, it took me so much time and finally decided to change back to numpy & pandas. However, sometimes the data file can be too large for pandas to load, Dask will help you manage the memory into chunks, so you can use Dask to load the giant data file.
- But you can convert the preprocessed data into dask dataframe
- The parallel processing for machine learning didn't make me feel it's much faster than sklearn.
- Although dask-ml mentioned it supports both sklearn grid search and dask-ml grid search, but when I was using sklearn grid search, it gave large amount of error and could not tell what caused the error.
- I think for larger dataset, Spark must be faster if its machine learning supports the methods. We can also convert pandas dataframe to Saprk dataframe to overcome the shortage of data preprocessing functions.

- Pig vs Hive: https://upxacademy.com/pig-vs-hive/
- Spark 2.0, SparkSession (can be used for both Spark SQL Context and Hive Context, Spark SQL is based on Haive but has its own strength): http://cdn2.hubspot.net/hubfs/438089/notebooks/spark2.0/SparkSession.html
- Mastering Spark 2.0: https://github.com/hanhanwu/Hanhan_Data_Science_Resources2/blob/master/Mastering-Apache-Spark-2.0.pdf
- Spark Definitive Guide: https://github.com/hanhanwu/readings/blob/master/Apache-Spark-The-Definitive-Guide-Excerpts-R1%20copy.pdf
- Spark Session - supports both SQL Context and Hive Context
- Structured Streaming - just write batch computation and let Spark deal with streaming with you. I’m waiting to see its better integration with MLLib and other machine learning libraries
- HyperLogLog - the story is interesting
val ds = spark.read.json("/databricks-public-datasets/data/iot/iot_devices.json").as[DeviceIoTData]- Choice of Spark DataFrame, DataSets and RDD, P35
- Structured Streaming, P57-59
- Lessons from large scale machine learning deployment on Spark, 2.0: https://github.com/hanhanwu/Hanhan_Data_Science_Resources2/blob/master/Lessons_from_Large-Scale_Machine_Learning_Deployments_on_Spark.pdf
- Hadoop 10 years: https://upxacademy.com/hadoop-10-years/
- Why Cloud Service is better than HDFS: https://databricks.com/blog/2017/05/31/top-5-reasons-for-choosing-s3-over-hdfs.html?utm_campaign=Company%20Blog&utm_content=55155959&utm_medium=social&utm_source=linkedin
- Hive function cheat sheet: https://www.qubole.com/resources/cheatsheet/hive-function-cheat-sheet/
- Distributing System
- Spack New Physical Plan: https://databricks.com/blog/2017/04/01/next-generation-physical-planning-in-apache-spark.html?utm_campaign=Databricks&utm_content=51844317&utm_medium=social&utm_source=linkedin
- CAP Theorem: https://en.wikipedia.org/wiki/CAP_theorem
- CAPP: https://drive.google.com/file/d/0B3Um1hpy8q7gVjhVT3dGUWFxRm8/view
- S survey summary on NoSQL: https://www.linkedin.com/pulse/survey-nosql-key-value-pair-databases-uzma-ali-pmp?trk=v-feed&lipi=urn%3Ali%3Apage%3Ad_flagship3_feed%3BspSXDtIY3PN6lbk4C%2FTwTg%3D%3D
- I like the summary table in this poster
- They did survey on Cassandra, Redis, DynamoDB, Riak, HBASE, Voldemort (among them, I have only used HBASE so far...)
- A book - I Heart Logs
- The book: https://github.com/hanhanwu/readings/blob/master/I_Heart_Logs.pdf
- It talks about how powerful logs can be in distributing systems, streaming processing, etc, each section has a real-life example. I like the streaming processing part in this book most.
- It is a great book that has broaden and deepen the concepts we have heard many time times but may has misunderstanding, such as "logs", "streaming processing" and even "ETL".
- Google Caffeine: https://googleblog.blogspot.ca/2010/06/our-new-search-index-caffeine.html
- It rebuilt its web crawling, processing, and indexing pipeline—what has to be one of the most complex, largest scale data processing systems on the planet —on top of a stream processing system.
- NoSQL
- CAP theorem (could only choose 2)
- Consistency: all clients always have the same view of data
- Avability: client can always read and write
- Partition tolerance means that the system works well across physical network partitions
- There are different types of NoSql databases
- Column oriented
- Documented oriented
- Graph database
- Key-value oriented
- NoSql visual guide: http://blog.nahurst.com/visual-guide-to-nosql-systems
- Some other description: http://stackoverflow.com/questions/2798251/whats-the-difference-been-nosql-and-a-column-oriented-database
- Amazon DynamoDB vs. Amazon Redshift vs. Oracle NoSQL: https://db-engines.com/en/system/Amazon+DynamoDB%3BAmazon+Redshift
- It seems that DynamoDB is NoSql while Redshift is a data warehouse based on psql
- CAP theorem (could only choose 2)
Build Machine Learning Platform
-
AWS Sagemaker
- How it works: https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works.html
- "Amazon SageMaker is a fully managed service that enables you to quickly and easily integrate machine learning-based models into your applications"

- It also allows the code, data to be shared within the team. With Sagemaker, you can create an EC2 instance and run the code that can takes long time to execute on your local machine. It also helps to connect to many other AWS resources such as S3, Glue, AWS visualization, etc.
- Sagemaker and Step Functions
- Fuzzy Matching and Deduplicating Data with ML Transforms for AWS Lake Formation
-
AWS Quicksight
- 10 mins demo of Quicksight, interactive, allows you to build dashboard with multiple charts, allows you to share, similar to tableau
-
Uber Engineering - Machine Learning Platform they built
- https://eng.uber.com/michelangelo/
- I like the name, Michelangelo
-
Uber Machine Learning Blog
- https://eng.uber.com/tag/machine-learning/
- Uber is really doing lots of researches, maybe we can borrow some ideas
-
A Well Summarized Production Level Machine Learning Pipeline
- I provided suggested tools/platform in each stag of production development, I think it can be used not only in deep learning, but also in other machine learning.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
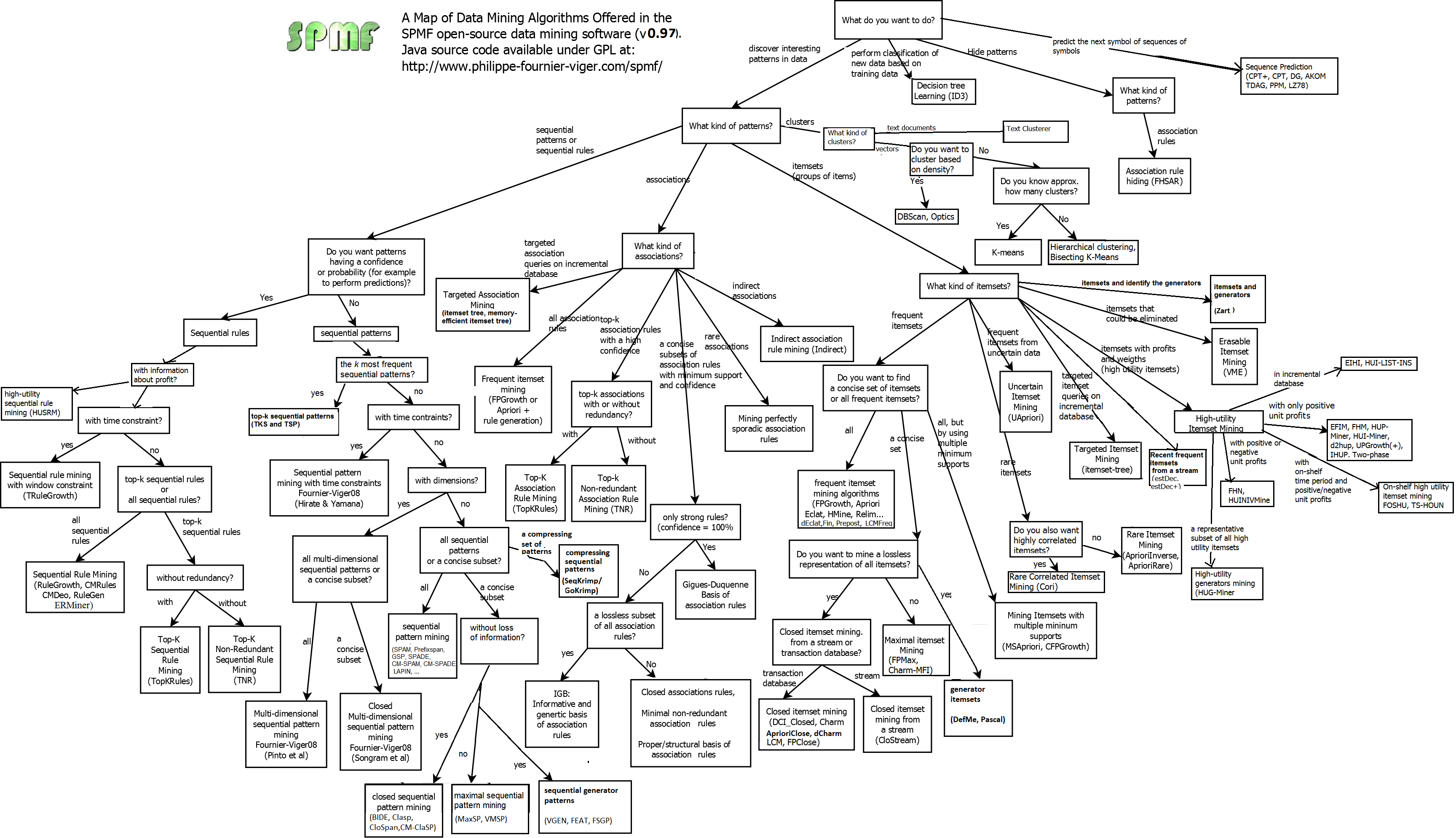{kind=link}
{kind=link}
Cloud
-
For Cloud Machine Learning in Spark, AWS and Azure Machine Learning, check my previous summary here: https://github.com/hanhanwu/Hanhan_Data_Science_Resources
-
AWS Machine Learning
- The white paper about overall infrastructure: https://d1.awsstatic.com/whitepapers/machine-learning-foundations.pdf
- AWS whitepapers: https://aws.amazon.com/whitepapers/
- My AWS practice and notes: https://github.com/hanhanwu/Hanhan_AWS
- AWS Anomalies Detection Streaming: https://towardsdatascience.com/real-time-streaming-and-anomaly-detection-pipeline-on-aws-cbd0bef6f20e
- It uses Robust Random Cut Forest (RRCF), it's an unsupervised learning but works similar to bagging, by calculating anomaly score in each tree and finally aggregate the scores to detect anomaly.
- In this article, it also mentioned all the details about how this algorithm works
- Amazon Ground Truth
- To sum up, it's the extended merchanic turk, besides mechanic turk functions, it also allows you to use private group or third party vendors to help data labeling. Also similar to mechanic turk, if you need to collect data with customized website or app, still need to build them yourself.
-
Compute Canada & West Grid
- How to apply for an account: https://www.computecanada.ca/research-portal/account-management/apply-for-an-account/
- login West Grid cloud through terminal: https://www.westgrid.ca//support/quickstart/new_users#about
- Note: the GUI the above guidance mentioned means the graphical tool, not interactive user interface...
- Run X11 in Mac OS X with XQuartz: http://osxdaily.com/2012/12/02/x11-mac-os-x-xquartz/
- When you are using XQuartz, once xterm appeared, loggin into Canada Computer with SSH X forwarding through xterm: https://www.westgrid.ca/support/visualization/remote_visualization/x11
- Creat Computer Canada Cloud (it seems that Computer Canada Cloud and West Grid are different cloud, but you apply for West Grid through Compute Canada account): https://www.computecanada.ca/research-portal/national-services/compute-canada-cloud/create-a-cloud-account/
- Tutorial for creating Compute Canada cloud (the video at the bottom): https://www.computecanada.ca/research-portal/national-services/compute-canada-cloud/
- Cloud Canada Quick Start: https://docs.computecanada.ca/wiki/Cloud_Quick_Start
- Command lines: https://github.com/hanhanwu/Hanhan_Data_Science_Resources2/blob/master/WestGrid_commands.md
TEXT ANALYSIS
- Text data preprocessing basic steps: https://www.analyticsvidhya.com/blog/2015/06/quick-guide-text-data-cleaning-python/
- My NLP practice: https://github.com/hanhanwu/Hanhan_NLP
- Jigsaw - Data Visualization for text data
- Tutorial Videos (each video is very short, good): http://www.cc.gatech.edu/gvu/ii/jigsaw/tutorial/
- Jigsaw manual: http://www.cc.gatech.edu/gvu/ii/jigsaw/tutorial/manual/#initiating-session
Non-Machine Learning Data Analysis Examples
- Analysis with data visualization: https://www.analyticsvidhya.com/blog/2016/12/who-is-the-superhero-of-cricket-battlefield-an-in-depth-analysis/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
AI
-
BOOK - Fundamentals of Deep Learning: https://github.com/hanhanwu/readings/blob/master/fundamentals-of-deep-learning-sampler.pdf
- I found the full book in school library, it should be able to be found at Microsoft library too :)
-
Course - Standford Convolutional Network for Visual Recognition: http://cs231n.github.io/convolutional-networks/
- Younger kids are so lucky nowadays! I found the notes are pretty good to review important concepts that will be used in neural network implemention. Now let me review some courses here, otherwise it really gives me lots of difficulties in debugging CNN
- Demo architecture, 10 class classification: http://cs.stanford.edu/people/karpathy/convnetjs/demo/cifar10.html
- My notes: https://github.com/hanhanwu/Hanhan_Data_Science_Resources2/blob/master/Standford_CNN_Notes1.pdf
-
Neural Network is an Universal Approximators. Besides, Kernel SVM and Boosted Decision Trees are also universal approximators
-
Deep Learning basic concepts (it's a real good one!): https://www.analyticsvidhya.com/blog/2017/05/25-must-know-terms-concepts-for-beginners-in-deep-learning/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- how does
activation functionwork: *u = ∑W*X+b, X is the input vector, W is the weights vector, b is bias- apply activation function
f()to u,f(u)is the output of the layer
- apply activation function
- Different activation functions
- The sigmoid transformation generates a more smooth range of values between 0 and 1. We might need to observe the changes in the output with slight changes in the input values. Smooth curves allow us to do that and are hence preferred over step functions.
- The major benefit of using ReLU is that it has a constant derivative value for all inputs greater than 0. The constant derivative value helps the network to train faster.
- softmax, normally used in the output layer for classification. It is similar to sigmoid but its output is normalized to make the sum as 1. Meanwhile, sigmoid is used for binary classification while softmax can be used on multi-class classification.
- Gradient Descent & Optimization & Cost function: Gradient descent is an optimization method, aiming at minimizing the cost/loss
- Backpropagation is used to update weights
- Batches: While training a neural network, instead of sending the entire input in one go, we divide in input into several chunks of equal size randomly. Training the data on batches makes the model more generalized as compared to the model built when the entire data set is fed to the network in one go.
- Epochs: An epoch is defined as a single training iteration of all batches in both forward and back propagation. This means 1 epoch is a single forward and backward pass of the entire input data. Higher epochs could lead to higher accuracy but maybe also overfitting, the higher one also takes longer time.
- Dropout: Dropout is a regularization technique which prevents over-fitting of the network. When training a certain number of neurons in the hidden layer is randomly dropped. This means that the training happens on several architectures of the neural network on different combinations of the neurons. You can think of drop out as an ensemble technique, where the output of multiple networks is then used to produce the final output.
- Batch Normalization, it is used to ensure the data distribution will be the same as the next layer expected. Because after backpropagation, the weights changed and the data distribution may also changed while te next layer expects to see similar data distribution it has seen before.
- CNN (Convolutional Neural Network)
- 1×1 convolution CNN can help in dimensionality reduction, feature pooling and it suffers less overfitting due to small kernel size
- Filter: is a smaller window of data, it used to filter the entire data into multiples windows, each window generates a convoluted value. All the convoluted values form a new set of data. Using this method, an image can be convoluted into less parameters. CNN is often used on image
- Pooling: a pooling layer is often added between convolutional layers to reduce parameters in order to reduce overfitting. For example, in practice, MAX pooling works better
- Padding: Padding refers to adding extra layer of zeros across the images so that the output image has the same size as the input
- Data Augmentation: the addition of new data derived from the given data, which might prove to be beneficial for prediction. Such as brightening/rotating the image
- Detailed CNN Go Through: https://www.analyticsvidhya.com/blog/2017/06/architecture-of-convolutional-neural-networks-simplified-demystified/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Not a big fan of deep learning, but I am paying attention to all these tuutorials as well, to learn more about them. This article is a real good one. I love this typy of go through, from the very beginning, step by step, telling you how an algorithm work, with examples :)
- CNN is a popular algorithm for image classification
- Images are formed by pixels, if the order or color of these pixels change, the image will change too. Machine will break an image into a matrix of pixels, and store the color code of each pixel at the representative position
- A fully connected network would take this image as an array by flattening it and considering pixel values as features to predict the number in image. What CNN does is to take the input image, define a weight matrix and the input is convolved to extract specific features from the image without losing the information about its spatial arrangement, this also significantly reduces number of features
- The convolution layer - kk matrix with 0,1 weights, use this kK matrix in the whole n*n matrix to extract features. Weights are learnt such that the loss function will be minimized. When there are multiple convolution layer, the deeper the layer is, the more complex features it extratced. An activation map is the output of the convolution layer.
- Stride: If the weight matrix moves 1 pixel at a time, we call it as a stride of 1. The size of image keeps on reducing as we increase the stride value
- Padding: Padding the input image with zeros across it when the size shrinked after stride. This is to preserve the size of the image
- The spatial size of the output image can be calculated as
([W-F+2P]/S)+1. Here, W is the input volume size, F is the size of the filter, P is the number of padding applied and S is the number of strides. - Output Layer - The convolution and pooling layers would only be able to extract features and reduce the number of parameters from the original images. However, to generate the final output we need to apply a fully connected layer to generate an output equal to the number of classes we need. The output layer has a loss functionlike categorical cross-entropy, to compute the error in prediction. Once the forward pass is complete the backpropagation begins to update the weight and biases for error and loss reduction.
- Images should be resized to the same shape and size before using CNN. You can use Python
cv2for image resizing.images[i]=cv2.resize(images[i],(300,300))
- RNN (Recurrent Neural Network)
- Recurrent Neuron: A recurrent neuron is one in which the output of the neuron is sent back to it for t time stamps.
- RNN is often used for sequential data, such as time series
- Vanishing Gradient Problem – Vanishing gradient problem arises in cases where the gradient of the activation function is very small. During back propagation when the weights are multiplied with these low gradients, they tend to become very small and “vanish” as they go further deep in the network. This makes the neural network to forget the long range dependency. This generally becomes a problem in cases of recurrent neural networks where long term dependencies are very important for the network to remember. This can be solved by using activation functions like ReLu which do not have small gradients.
- Exploding Gradient Problem – This is the exact opposite of the vanishing gradient problem, where the gradient of the activation function is too large. During back propagation, it makes the weight of a particular node very high with respect to the others rendering them insignificant. This can be easily solved by clipping the gradient so that it doesn’t exceed a certain value.
- how does
-
Computer Vision & Deep Learning Architectures
- https://www.analyticsvidhya.com/blog/2017/08/10-advanced-deep-learning-architectures-data-scientists/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Computer Vision Tasks:
- Object Recognition / classification
- Classification + Localisation
- Object Detection
- Image Segmentation
- Architectures
- AlexNet: a simple architecture with convolutional and pooling layers one on top of the other, followed by fully connected layers at the top. AlexNet speeds up the training by 10 times just by the use of GPU.
- VGG Net: characterized by its pyramidal shape, where the bottom layers which are closer to the image are wide, whereas the top layers are deep. It contains subsequent convolutional layers followed by pooling layers. It is very slow to train if trained from scratch, even on a decent GPU. But pre-trained networks for VGG are available freely on the internet, so it is commonly used out of the box for various applications.
- GoogleNet: made a novel approach called the Inception Module. It is a drastic change from the sequential architectures. In a single layer, multiple types of “feature extractors” are present. The network at training itself has many options to choose from when solving the task. It can either choose to convolve the input, or to pool it directly. GoogleNet trains faster than VGG. Size of a pre-trained GoogleNet is comparatively smaller than VGG.
- ResNet: consists of multiple subsequent residual modules, which are the basic building block of ResNet architecture. A residual module has two options, either it can perform a set of functions on the input, or it can skip this step altogether. Similar to GoogleNet, these residual modules are stacked one over the other to form a complete end-to-end network. The main advantage of ResNet is that hundreds, even thousands of these residual layers can be used to create a network and then trained. This is a bit different from usual sequential networks, where you see that there is reduced performance upgrades as you increase the number of layers.
- ResNeXt: the improvement on ResNet. A current state-of-art technique in object recognition
- RCNN (Region Based CNN): It is said to be the most influential of all the deep learning architectures that have been applied to object detection problem. It attempts to draw a bounding box over all the objects present in the image, and then recognize what object is in the image with CNN.
- YOLO (You Only Look Once): First of all, I like this name. A current state-of-the-art real time system built on deep learning for solving image detection problems. It first divides the image into defined bounding boxes, and then runs a recognition algorithm in parallel for all of these boxes to identify which object class do they belong to. All of this is done in parallely, so it can run in real time; processing upto 40 images in a second.
- SqueezeNet: extremely useful in low bandwidth scenarios like mobile platforms. It using a specialized structure called the fire module.
- SegNet: it deals with image segmentation problem. It consists of sequence of processing layers (encoders) followed by a corresponding set of decoders for a pixelwise classification. The information transfer is direct instead of convolving them.
- GAN (Generative Adversarial Network): It is used to generate an entirely new image which is not present in the training dataset, but is realistic enough to be in the dataset.
- Reference (good one!): https://www.analyticsvidhya.com/blog/2017/08/10-advanced-deep-learning-architectures-data-scientists/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- An example to build atchitecture in Keras (Step 7): https://elitedatascience.com/keras-tutorial-deep-learning-in-python#step-7
-
NN examples in R and Python: https://www.analyticsvidhya.com/blog/2017/05/neural-network-from-scratch-in-python-and-r/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
Use pre-trained model for deep learning: https://www.analyticsvidhya.com/blog/2017/06/transfer-learning-the-art-of-fine-tuning-a-pre-trained-model/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
Deep Learning talks from PyData (it also has some other data science talks): https://www.analyticsvidhya.com/blog/2017/05/pydata-amsterdam-2017-machine-learning-deep-learning-data-science/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
Neural Network vs Deep Learning: When there are more hidden layers and increase depth of neural network a neural network becomes deep learning.
-
Something about AI (those brief explaination about real life applications are useful and intresting): https://www.analyticsvidhya.com/blog/2016/12/artificial-intelligence-demystified/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
Deep Learning Learning Resources: https://www.analyticsvidhya.com/blog/2016/08/deep-learning-path/
-
Reinforcement Learning Open Sources: https://www.analyticsvidhya.com/blog/2016/12/getting-ready-for-ai-based-gaming-agents-overview-of-open-source-reinforcement-learning-platforms/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
Reinforcement Learning with Python Example: https://www.analyticsvidhya.com/blog/2017/01/introduction-to-reinforcement-learning-implementation/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
Deeping Learning APIs, help you build simple apps (it's interesting): https://www.analyticsvidhya.com/blog/2017/02/6-deep-learning-applications-beginner-python/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
5 More Deep Learning APIs [Python]: https://www.analyticsvidhya.com/blog/2017/02/5-deep-learning-applications-beginner-python/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
Deep Learning Skillset Test1: https://www.analyticsvidhya.com/blog/2017/01/must-know-questions-deep-learning/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Neural Networks cannot do data preprocessing themselves
- Neural Network Dropout can be seen as an extreme form of Bagging in which each model is trained on a single case and each parameter of the model is very strongly regularized by sharing it with the corresponding parameter in all the other models.
- Neural Network uses hidden layers to reduce dimensionality, it is based on predictive capability of the features. By comparison, PCA does dimensional reduction based on feature correlation
- People set a metric called bayes error which is the error they hope to achieve, this is because: Input variables may not contain complete information about the output variable; System (that creates input-output mapping) may be stochastic; Limited training data
- The number of neurons in the output layer dose NOT have to match the number of classes. If your outputis using one-hot encoding, they have to match. Otherwise, you can use other methods. For example, 2 neurons represent 4 classes using binary bits (00, 01, 10, 11)
- Without knowing what are the weights and biases of a neural network, we cannot comment on what output it would give.
- Convolutional Neural Network would be better suited for image related problems because of its inherent nature for taking into account changes in nearby locations of an image
- Recurrent neural network works best for sequential data. Recurrent neuron can be thought of as a neuron sequence of infinite length of time steps. Dropout does not work well with recurrent layer.
- A neural network is said to be a universal function approximator, so it can theoretically represent any decision boundary.
- To decrease the “ups and downs” when visualizing errors, you can try to increase the batch size. But the "ups and downs" are no need to worry as long as there is a cumulative decrease in both training and validation error.
- When you want to re-use a pre-trained NN model on similar problems, you can keep the previous layers but only re-train the last layer, since all the previous layers work as feature extractors
- To deal with overfitting in NN, you can use Dropout, Regularization and Batch Normalization. Using Batch Normalization is possbile to reach higher level accuracy. Dropout is designed as a regulazer in order to reduce the gap between the tester and the trainer; Batch Normalization is designed to make optimization easier, so it does less regularization. So Batch Normalization is not as strong as dropout. When the dataset is very small, Dropout should be better than Batch Normalization. Batch Normalization video: https://www.youtube.com/watch?v=Xogn6veSyxA
-
Deep Learning Skillset Test2: https://www.analyticsvidhya.com/blog/2017/04/40-questions-test-data-scientist-deep-learning/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- NN is a representative algorithm, which means: it converts data to a form that better solve the problem
- Perplexity is a commonly used evaluation technique when applying deep learning for NLP tasks. Lower the perplexity the better.
- Sigmoid was the most commonly used activation function in neural network, until an issue was identified. The issue is that when the gradients are too large in positive or negative direction, the resulting gradients coming out of the activation function get squashed. This is called saturation of the neuron. That is why ReLU function was proposed, which kept the gradients same as before in the positive direction. ReLU also gets saturated, but it's on the negative side of x-axis.
- Dropout Rate is the probability of keeping a neuron active. Higher the dropout rate, lower is the regularization
- l-BFGS is a second order gradient descent technique whereas SGD is a first order gradient descent technique. When
Data is sparseorNumber of parameters of neural network are small, l-BFGS is better - For non-continuous objective during optimization in deep neural net, Subgradient method is better
-
Some ideas about GPU: https://www.analyticsvidhya.com/blog/2017/05/gpus-necessary-for-deep-learning/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
Microsoft CNTK (Cognitive Toolkit)
- Official Website: https://www.microsoft.com/en-us/cognitive-toolkit/
- GitHub: https://github.com/Microsoft/CNTK
-
Age Detection Tutorial: https://www.analyticsvidhya.com/blog/2017/06/hands-on-with-deep-learning-solution-for-age-detection-practice-problem/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
-
Generative Adversarial Networks (GNA): https://www.analyticsvidhya.com/blog/2017/06/introductory-generative-adversarial-networks-gans/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Reads like, how to train your dragon
- Anyway, it's cool to see this video: https://www.youtube.com/watch?v=6OAHfBoxyx8
- I like the idea that if he kills the shadow, he dies; but if he does nothing, he dies; only when he tried to merge with the shadow, he becomes stronger... Quite like this GNA concepts
- I even found Prince of Persia 1989-2013 short history: https://www.youtube.com/watch?v=SscOEEXmy84
Experiences/Suggestions from Others
- Why Machine Learning Model failed to get deployed in the industry: https://www.analyticsvidhya.com/blog/2016/05/8-reasons-analytics-machine-learning-models-fail-deployed/?utm_content=buffere8f77&utm_medium=social&utm_source=linkedin.com&utm_campaign=buffer
- From a data scientist (I agree with many points he said here, especially the one to get enough sleep, I also think we have to have enough good food before focusing on data science work, this is an area really needs strong focus and cost energy): https://www.analyticsvidhya.com/blog/2016/12/exclusive-ama-with-data-scientist-sebastian-raschka/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Suggestons for analytics learning (I agree with some, although I don't think they should call them "rules"): https://www.analyticsvidhya.com/blog/2014/04/8-rules-age-analytics-learning/?utm_content=buffer9e51f&utm_medium=social&utm_source=facebook.com&utm_campaign=buffer
- Regression skillset test: https://www.analyticsvidhya.com/blog/2016/12/45-questions-to-test-a-data-scientist-on-regression-skill-test-regression-solution/?utm_content=buffer5229b&utm_medium=social&utm_source=facebook.com&utm_campaign=buffer
- Linear Regression skillset test: https://www.analyticsvidhya.com/blog/2017/07/30-questions-to-test-a-data-scientist-on-linear-regression/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Tree based skillset test: https://www.analyticsvidhya.com/blog/2016/12/detailed-solutions-for-skilltest-tree-based-algorithms/?utm_content=bufferde46d&utm_medium=social&utm_source=facebook.com&utm_campaign=buffer
- Clustering Skillset test: https://www.analyticsvidhya.com/blog/2017/02/test-data-scientist-clustering/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- KNN Skillset test: https://www.analyticsvidhya.com/blog/2017/09/30-questions-test-k-nearest-neighbors-algorithm/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Computation time for testing data is longer than training time, since during testing time, you calculate the k nearest neighbours
- The training time for any k is the same.
- Larger k is, the smother the decision boundry is
- KNN can also be used in regression, you can use the test value to compare with mean or median of the subgroups and choose the k nearest ones
- KNN doesn't make any assumption but it works better of all the data is in the same scale; Also it works better for smaller set of data, because of the computation burden
- In KNN, if you want to calcuate the distance between ategorical variables, use Hamming Distance
- If there is noise data, you can try to increase k
- SVM Skillset test: https://www.analyticsvidhya.com/blog/2017/10/svm-skilltest/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- I don't agree with all the answers, such as 19th questions, I think it should be 2&3.
- Image Processing skillset: https://www.analyticsvidhya.com/blog/2017/10/image-skilltest/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Machine Learning Skillset test: https://www.analyticsvidhya.com/blog/2017/04/40-questions-test-data-scientist-machine-learning-solution-skillpower-machine-learning-datafest-2017/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- 2 variables can relate to each other but with 0 pearson correlation
- SGD vs GD: In SGD for each iteration you choose the batch which is generally contain the random sample of data But in case of GD each iteration contain the all of the training observations.
- Statistics Skillset test: https://www.analyticsvidhya.com/blog/2017/05/41-questions-on-statisitics-data-scientists-analysts/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Probability Skillset test: https://www.analyticsvidhya.com/blog/2017/04/40-questions-on-probability-for-all-aspiring-data-scientists/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Some answers may have problems. For example, I think if question 33 has the right answer then question 28 has the wrong answer
- Majorly uses the Byesian Theorem taught in conditional probability theorem: https://www.analyticsvidhya.com/blog/2017/03/conditional-probability-bayes-theorem/
- An interesting take-away is about Monty Hall’s problem (I don't fullt understand, especially after seeing the debat after the post), the problem looks interesting: https://www.analyticsvidhya.com/blog/2014/04/probability-action-monty-halls-money-show/
- In this post 6 years later, now I understand the probability behind Monty Hall problem: https://www.analyticsvidhya.com/blog/2020/08/probability-conditional-probability-monty-hall-problem/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- The decision tree made it easy to understand
- The conditional probability was trying to tell you, if you chose door 1, switch to door 2 or 3 after the host revealed door 3 or door 2 has higher chance to win than sticking to door 1. Same, if we have N doors and you chose door 1,
P(prize door 1 | host door x) = (1/N) * (1/(N-1)) / P(host door x),P(prize another door | host door x) = (1/N) * (1/(N-2)) / P(host door x), so still if you stick to door 1 choice, the chance to win is lower.
- In this post 6 years later, now I understand the probability behind Monty Hall problem: https://www.analyticsvidhya.com/blog/2020/08/probability-conditional-probability-monty-hall-problem/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- When applying Onehot Encoding, make sure the frequency distribution is the same in training and testing data
- Output value range:
- tanh function: [-1, 1]
- SIGMOID function: [0, 1]
- ReLU function: [0, infinite], ReLU gives continuous output in range 0 to infinity, so if the output requires finite output, ReLU cannot be a choice
- When there are multicollinear features (highly correlated features), solutions can be:
- remove one of the correlated variables
- use penalized regression models like ridge or lasso regression
- Ensembling is using weak learners, these learners are less likely to have overfit since each of them are sure about part of the problems, and therefore they may have low variance but high bias (how much the predicted value is different from the real value)
- If a classifier is confident about an incorrect classification, then log-loss will penalise it heavily. For a particular observation, the classifier assigns a very small probability for the correct class then the corresponding contribution to the log-loss will be very large. Lower the log-loss, the better is the model.
- Ensembling Skillset test: https://www.analyticsvidhya.com/blog/2017/02/40-questions-to-ask-a-data-scientist-on-ensemble-modeling-techniques-skilltest-solution/?
- Creating an ensemble of diverse models is a very important factor to achieve better results. Generally, an ensemble method works better, if the individual base models have less correlation among predictions
- If you have m base models in stacking, that will generate m features for second stage models
- Because when you have m base models, each model will make the prediction, each prediction result will become the column in the next stage. That's why in the next stage, you will have m more features
- More ensembling notes including details in stacking, blending, boosting and bagging: https://github.com/hanhanwu/Hanhan_Data_Science_Resources/blob/master/Experiences.md#more-about-ensembling
- Dropout in a neural network can be considered as an ensemble technique, where multiple sub-networks are trained together by “dropping” out certain connections between neurons.
- !! Bagging of unstable classifiers is a good idea. Based on this paper, "If perturbing the learning set can cause signicant changes in the predictor constructed, then bagging can improve accuracy."
- Better not to have same weights, it will make all the neurons to do the same thing and never converge
- Weights between input and hidden layer are constant
- Time series skillset test: https://www.analyticsvidhya.com/blog/2017/04/40-questions-on-time-series-solution-skillpower-time-series-datafest-2017/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Dimensional Reduction skillset test: https://www.analyticsvidhya.com/blog/2017/03/questions-dimensionality-reduction-data-scientist/?utm_content=bufferc792d&utm_medium=social&utm_source=linkedin.com&utm_campaign=buffer
- Deep Learning Skillset Test1: https://www.analyticsvidhya.com/blog/2017/01/must-know-questions-deep-learning/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Deep Learning Skillset Test2: https://www.analyticsvidhya.com/blog/2017/04/40-questions-test-data-scientist-deep-learning/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- R Skillset test: https://www.analyticsvidhya.com/blog/2017/05/40-questions-r-for-data-science/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- SQL Skillset test1: https://www.analyticsvidhya.com/blog/2017/01/46-questions-on-sql-to-test-a-data-science-professional-skilltest-solution/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- TRUNCATE vs DELETE:
truncateis ddl (data definition language) command, it does not has rollback info and will release the memory;deleteis dml (data manipulation language) command, it contains rollback info and will not release the memory. - If a relation is satisfying higher normal forms, it automatically satisfies lower normal forms. Such as if it satisfies 3NF, it should automatically satisfies 1NF.
- Minimal super key is a candidate key. Only one Candidate Key can be Primary Key.
- PROJECT vs SELECT: In relational algebra ‘PROJECT’ operation gives the unique record but in case of ‘SELECT’ operation in SQL you need to use distinct keyword for getting unique records.
- SQL Index doesn’t help for the
likeclause. The addition of the index didn’t change the query execution plan. for example, the index on rating will not work for the query (Salary * 100 > 5000). But you can create an index on (Salary * 100) which will help. CREATE TABLE avian ( emp_id SERIAL PRIMARY KEY, name varchar);creates index as primary key- My disagrees: Q10, the answer should be (B)
- TRUNCATE vs DELETE:
- SQL Skillset test2: https://www.analyticsvidhya.com/blog/2017/05/questions-sql-for-all-aspiring-data-scientists/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- When you have created a view based on the table, using
dropcannot drop the table. Trydrop .. cascadewill drop the table and its dependent objects too - cartesian product: https://en.wikipedia.org/wiki/Cartesian_product
- My disagree: Q1, the answer should be B
- Some of the answers in this test make me doubt, such as Q2, Q4. Meanwhile, Q8, Q35 has confusing question
- In Q27, the answer description should be, "A" to 1, "N" to 2 and "K" to 3. Did the author fall asleep when wrinting this article?
- In Q28, the column names should start with an upper case, otherwise it will be an error
- I didn't think about questions from 39 to 42, but only quickly went through them, it seems that the question of Q40 is still not logically strict to me. I really cannot stand this post. Howcome it has so many problems.
- When you have created a view based on the table, using
- Python Skillset test: https://www.analyticsvidhya.com/blog/2017/05/questions-python-for-data-science/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- I didn't check this one
- Interview questions: https://www.analyticsvidhya.com/blog/2016/09/40-interview-questions-asked-at-startups-in-machine-learning-data-science/
Interview Tips
- Comprehensive Interview Questions: https://www.analyticsvidhya.com/blog/2018/06/comprehensive-data-science-machine-learning-interview-guide/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Tips for Estimate Questions: https://www.analyticsvidhya.com/blog/2014/01/tips-crack-guess-estimate-case-study/?utm_content=buffer5f90d&utm_medium=social&utm_source=facebook.com&utm_campaign=buffer
- 4 R interview questions (the last 2): https://www.analyticsvidhya.com/blog/2014/05/tricky-interview-questions/
- Data Science Hiring Guidance (I especially like the last part, which questions to ask employers): https://github.com/hanhanwu/Hanhan_Data_Science_Resources2/blob/master/Data%20Science%20Hiring%20Guide.pdf
TRAIN YOUR BRAIN
- Interview puzzles I: https://www.analyticsvidhya.com/blog/2014/09/commonly-asked-puzzles-analytics-interviews/
- Interview puzzles II: https://www.analyticsvidhya.com/blog/2014/10/commonly-asked-interview-puzzles-part-ii/
- Train mind analytical thinking: https://www.analyticsvidhya.com/blog/2014/01/train-mind-analytical-thinking/
- Brain training for analytical thinking: https://www.analyticsvidhya.com/blog/2015/07/brain-training-analytical-thinking/
OTHER
- Make a wish to Data Science Santa! (I really like this idea, you just need to choose your 2017 data science learning goals and finally, they will give you a Christmas gift which is full of relative learning resurces cater for your goals!) : https://www.analyticsvidhya.com/blog/2016/12/launching-analytics-vidhya-secret-santa-kick-start-2017-with-this-gift/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Interesting Data Science videos (I mean some of them looks interesting): https://www.analyticsvidhya.com/blog/2016/12/30-top-videos-tutorials-courses-on-machine-learning-artificial-intelligence-from-2016/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Some ideas about social media analysis: https://www.analyticsvidhya.com/blog/2017/02/social-media-analytics-business/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Linear Programming: https://www.analyticsvidhya.com/blog/2017/02/lintroductory-guide-on-linear-programming-explained-in-simple-english/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- How to create an R package, and publish on CRAN, GitHub: https://www.analyticsvidhya.com/blog/2017/03/create-packages-r-cran-github/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Behavioral Science: https://www.analyticsvidhya.com/blog/2017/04/behavioral-analytics-when-psychology-collides-analytics/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Most of the fundamentals in behavioral science apply on any type of population.
- compromise effect - Human has a tendency to find the middle option.
- decoy effect - Human mind is trained to make choices between similar objects
- anchoring effect - The price of any item is based on perception rather than the actual cost of the raw materials used. We start with a price and start bidding higher. The starting price is an anchor and the final price at which the item is sold is highly correlated to this anchor.
- steep temporal discounting effect - We have a tendency to value money in near future with a strong discounting factor but such discounting factor becomes small when we talk about longer time frames.
- “unknown unknowns” effect - Human has a tendency to underestimate probabilities when they face ambiguity.
- extreme probability bias effect - We tend to underestimate probability between 0 and 0.5 if event is favorable and exactly opposite happens when event is unfavorable. With underestimated perceived probability, we underestimate the value of Risky transactions.
- Winnning Strategy in Casino (blackjack): https://www.analyticsvidhya.com/blog/2017/04/flawless-winning-strategy-casino-blackjack-data-science/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Looks calculation intensive, I dind't read them throughly, but only checked the insights :)
- Tons of data analysis tools:
- Orange (drag & Drop): https://www.analyticsvidhya.com/blog/2017/09/building-machine-learning-model-fun-using-orange/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Docker (Sharable Data Science Code/Application): https://www.analyticsvidhya.com/blog/2017/11/reproducible-data-science-docker-for-data-science/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- Julia (a language for data science, does the same thing as R, Python): https://www.analyticsvidhya.com/blog/2017/10/comprehensive-tutorial-learn-data-science-julia-from-scratch/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
- 5 years of building Analytics Vidhya, their jorney and learnings