homepage_recipes
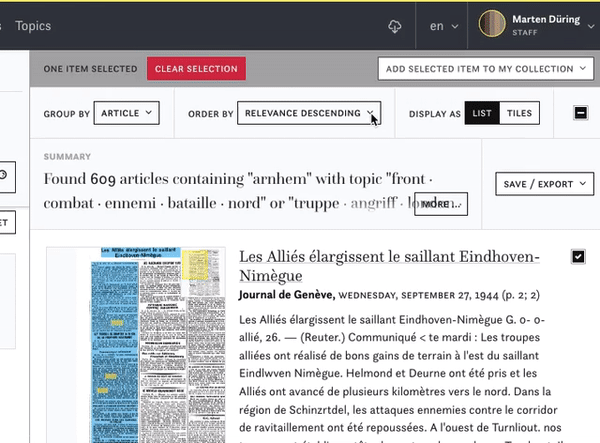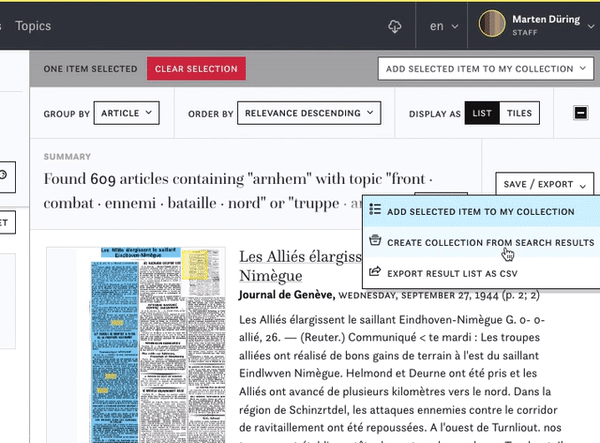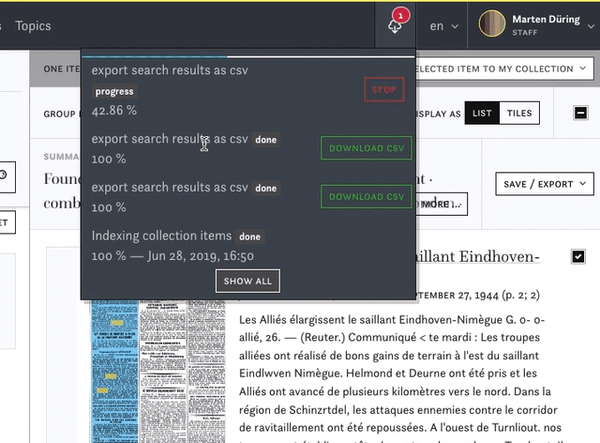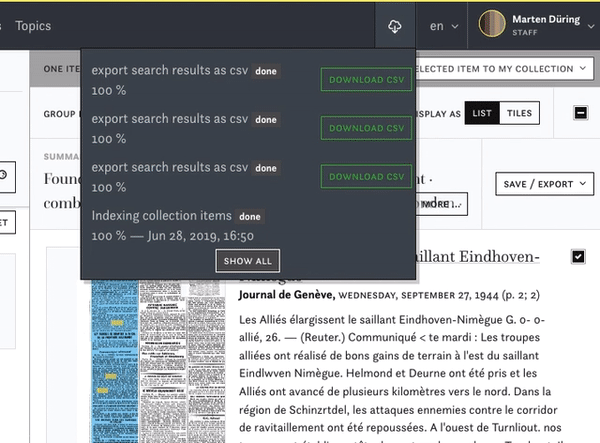
You can export the article texts and their metadata as .csv files for further analysis or just to keep a copy for yourself. In the exported .csv file you will have the most important metadata for each article as well as the full text. Mind that the .csv file needs to be imported in the UFT8 format for further use, with all the diacritic signs of the articles text.
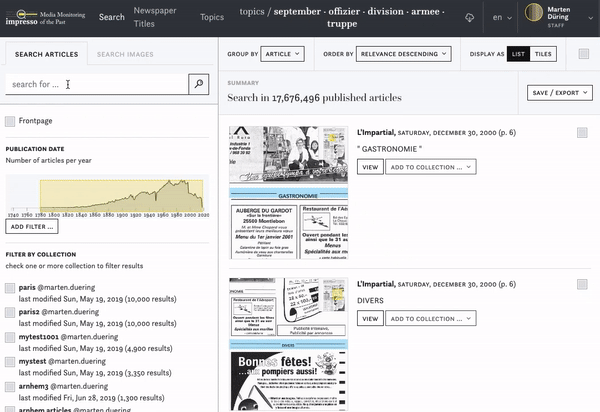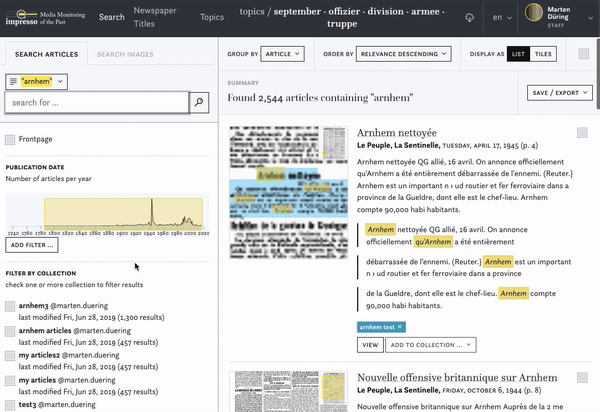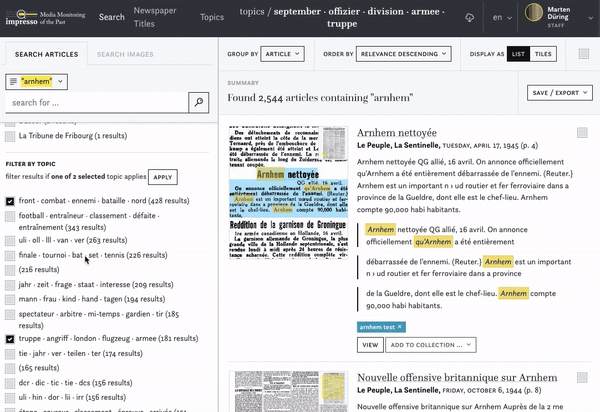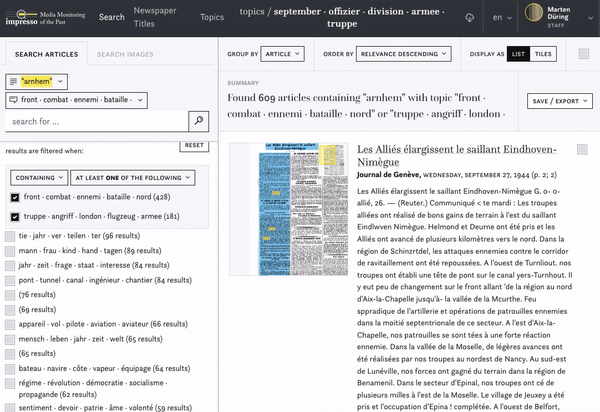
Metadata such as the name of a newspaper or the language it was printed in can be useful to filter your list of search results. Make your selection in the list of facets and confirm with "Apply".

We are experimenting with topics derived from topic modeling as content filters. You can reduce the number of search results by selecting one or more topics which appear relevant to your research interest. Alternatively, you can also exclude topics which are not of interest to you, e.g. the topic "animal · chasse · oiseau · chiens · chien" during a search for the history of the computer mouse. To do this, select "NOT containing" in the filter menu. To learn more about topic modeling, how it works and how we use it in the impresso project, we recommend this blog post.
impresso uses machine learning techniques to automatically identify images which are similar to each other. There are different ways to search for images in the corpus.
You can pick an image you are interested in and see if there are identical or similar images:
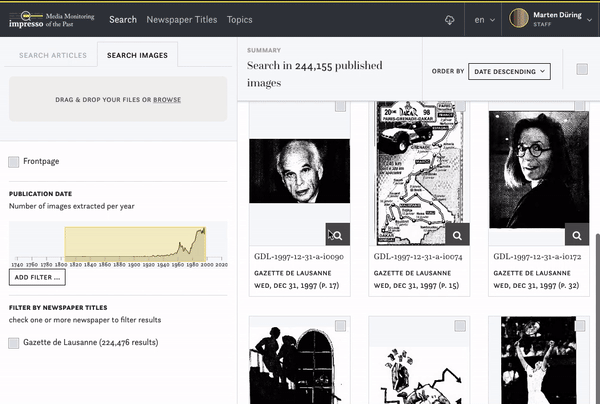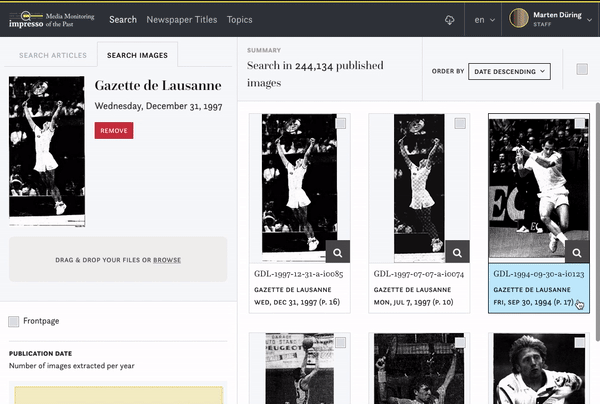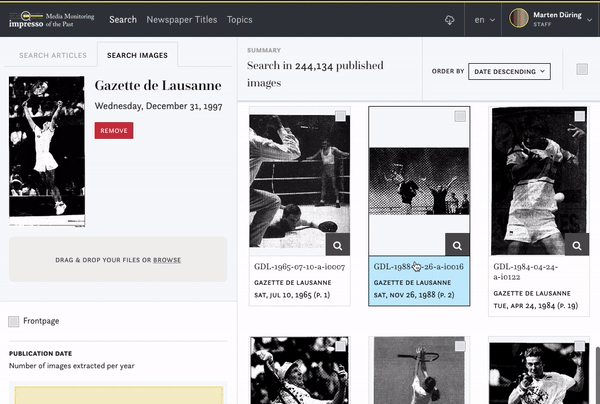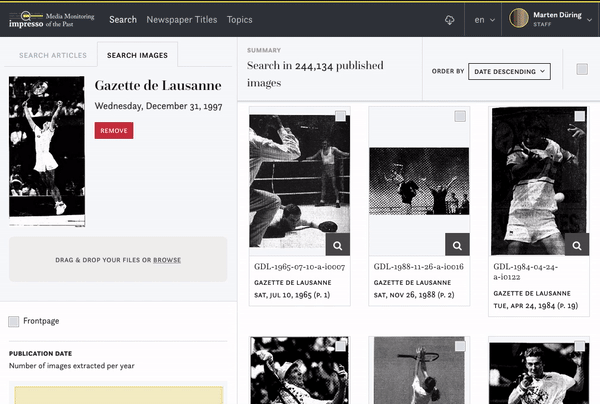
You can also upload your own image and check if there are similar images in our corpus:
You have the opportunity to create you own collections of articles. You can decide whether you would like a small number of hand-selected articles or rather a large, search-based collection of up to 10.000 articles. The parameters of the query are saved together with the articles (number of hits, keywords, date range, topics used as filters, newspapers metadata used as filters), so you can keep track of how you created the collection. You just need to add a title. Note that a future release will add the possibility to compare and contrast collections.

Suggestions offer additional keywords for search and point to common OCR misspellings you may want to include in your search so as to retrieve more articles. We use word embeddings to realise this. This technique relies on the old idea that "You shall know a word by the company it keeps". Word embeddings represent words as vectors in a multidimensional space which reveal words which are similar to each other.
..need to add more specific info on our approach...
intro text
- step
- step
{:.images}
- tetet
- rerre
After each query, each interaction in the search environment, the filters of metadata are actualised to give an overview of the distribution of the query results among the metadata: the query results distributed among the newspaper titles or language. This distribution is indicated in brackets behind each metadata facet.
- step
- step
{:.images}
- tetet
- rerre
When you have saved a large number of articles into a collection, you can simply delete individual articles by removing the label that appears below the snippets. Don't forget to make a note of the curation in the dedicated space of the collection management.
- step
- step
{:.images}
- tetet
- rerre