Implementation for EMNLP-2020 paper: Multimodal Joint Attribute Prediction and Value Extraction for E-commerce Product
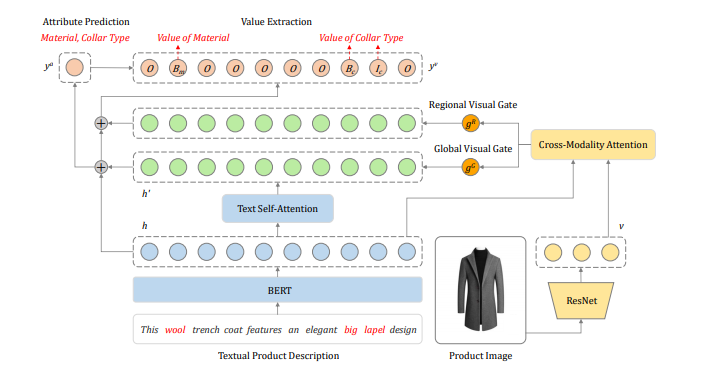
We collect a multimodal product attribute value dataset with textual product descriptions and product images.
Preview:
| instances | |
|---|---|
| All | 87,194 |
| Train | 71,194 |
| Valid | 8,000 |
| Test | 8,000 |
We sampled a tiny subset and put it here, so that you can run the code immediately after cloning.
If you are interested in the entire dataset, please:
- fill out this application form
- email us ([email protected], [email protected] or [email protected])
Replace the following files with the full version:
./data/
- jdai.jave.fashion.train.sample
- jdai.jave.fashion.valid.sample
- jdai.jave.fashion.test.sample
One instance in a row, and there are 4 columns:
- cid, id of the document, a cid may corresponds to multiple instances which share the same item image.
- sid, id of the sentence, a sid corresponds to one instance.
- text sentence (unlabelled).
- text sentence (labelled), in which labelled attribute values are surrounded by
<ATTRIBUTE_NAME>and</ATTRIBUTE_NAME>
Then run ./data/data_process.py to produce the data for model running.
./data/train
- input.seq # input seqs of word
- output.seq # output seqs of bio tokens
- output.label # output labels of attributes
- indexes # record the cid and sid of each instance
Procedures, which encode texts and images with pre-trained BERT and ResNet, are not included here. You should download pre-trained models and encode the text and image of each instance with them by yourself, after you get the full version dataset. Then replace the following files:
./data/embedded/
- txts.embedded.npy # text encoded by pre-trained bert, shape=[instance_num, seq_len, hidden_dim]
- txts.embeddedG.npy # vectors of [CLS] encoded by a pre-trained bert, shape=[instance_num, hidden_dim]
- sids_of_txts # sid index of above two files
- imgs.embedded.npy # image encoded by pre-trained resnet(last conv layer), shape=[image_num, 7*7, hidden_dim]
- imgs.embeddedG.npy # image encoded by pre-trained resnet(last pooling layer), shape=[image_num, hidden_dim]
- cids_of_imgs # cid index of above two files
References of how we implement:
ResNet: https://pytorch.org/docs/stable/torchvision/models.html
Python 3, Tensorflow 1.12
python3 train.py
python3 predict.py
Any questions about the code, please contact [email protected]