🎉 Now with Full DevOps - check the latest addition TRAINS AGENT
🚉 Documentation is here! wubba lubba dub dub and a Slack Channel 🚆
There is also an updated ❇️ TRAINS AWS autoscaler
"Because it’s a jungle out there"




TRAINS is our solution to a problem we share with countless other researchers and developers in the machine learning/deep learning universe: Training production-grade deep learning models is a glorious but messy process. TRAINS tracks and controls the process by associating code version control, research projects, performance metrics, and model provenance.
We designed TRAINS specifically to require effortless integration so that teams can preserve their existing methods and practices. Use it on a daily basis to boost collaboration and visibility, or use it to automatically collect your experimentation logs, outputs, and data to one centralized server.
We have a demo server up and running at https://demoapp.trains.allegro.ai.
You can try out TRAINS and test your code, with no additional setup.

With only two lines of code, this is what you are getting:
- Git repository, branch, commit id, entry point and local git diff
- Python environment (including specific packages & versions)
- stdout and stderr
- Resource Monitoring (CPU/GPU utilization, temperature, IO, network, etc.)
- Hyper-parameters
- ArgParser for command line parameters with currently used values
- Explicit parameters dictionary
- Tensorflow Defines (absl-py)
- Initial model weights file
- Model snapshots (With optional automatic upload to central storage: Shared folder, S3, GS, Azure, Http)
- Artifacts log & store (Shared folder, S3, GS, Azure, Http)
- Tensorboard/TensorboardX scalars, metrics, histograms, images (with audio coming soon)
- Matplotlib & Seaborn
- Supported frameworks: Tensorflow, PyTorch, Keras, XGBoost and Scikit-Learn (MxNet is coming soon)
- Seamless integration (including version control) with Jupyter Notebook and PyCharm remote debugging
Additionally, log data explicitly using TRAINS Explicit Logging.
TRAINS is a two part solution:
-
TRAINS python package auto-magically connects with your code
TRAINS requires only two lines of code for full integration.
To connect your code with TRAINS:
-
pip install trainsAdd optional cloud storage support (S3/GoogleStorage/Azure):
pip install trains[s3] pip install trains[gs] pip install trains[azure]
-
Add the following lines to your code
from trains import Task task = Task.init(project_name="my project", task_name="my task")- If project_name is not provided, the repository name will be used instead
- If task_name (experiment) is not provided, the current filename will be used instead
-
Run your code. When TRAINS connects to the server, a link is printed. For example
TRAINS Results page: https://demoapp.trains.allegro.ai/projects/76e5e2d45e914f52880621fe64601e85/experiments/241f06ae0f5c4b27b8ce8b64890ce152/output/log -
Open the link and view your experiment parameters, model and tensorboard metrics
See examples here
-
-
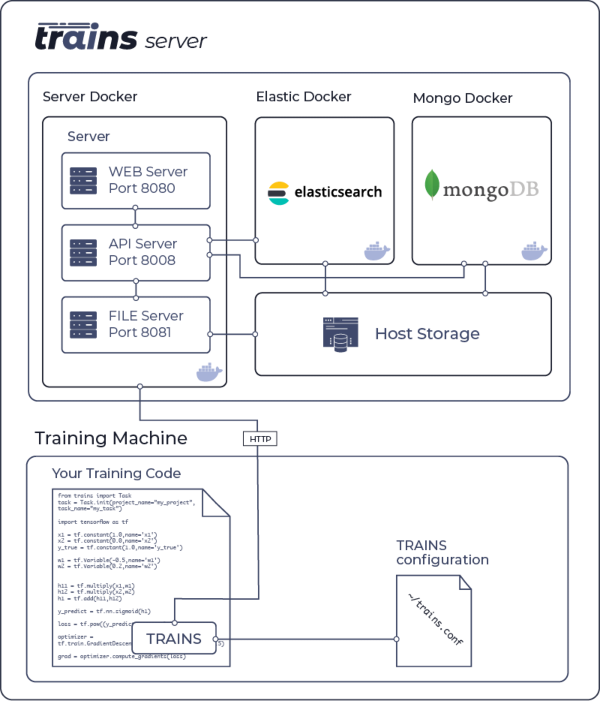
TRAINS-server for logging, querying, control and UI (Web-App)
We already have a demo server up and running for you at https://demoapp.trains.allegro.ai.
You can try out TRAINS without the need to install your own trains-server, just add the two lines of code, and it will automatically connect to the TRAINS demo-server.
Note that the demo server resets every 24 hours and all of the logged data is deleted.
When you are ready to use your own TRAINS server, go ahead and install TRAINS-server.
-
Install and run TRAINS-server (see Installing the TRAINS Server)
-
Run the initial configuration wizard for your TRAINS installation and follow the instructions to setup TRAINS package (http://trains-server-ip:port and user credentials)
trains-init
After installing and configuring, you can access your configuration file at ~/trains.conf
Sample configuration file available here.
TRAINS is supported by the same team behind allegro.ai, where we build deep learning pipelines and infrastructure for enterprise companies.
We built TRAINS to track and control the glorious but messy process of training production-grade deep learning models. We are committed to vigorously supporting and expanding the capabilities of TRAINS.
We believe TRAINS is ground-breaking. We wish to establish new standards of experiment management in deep-learning and ML. Only the greater community can help us do that.
We promise to always be backwardly compatible. If you start working with TRAINS today, even though this project is currently in the beta stage, your logs and data will always upgrade with you.
Apache License, Version 2.0 (see the LICENSE for more information)
TRAINS documentation is available here
For more examples and use cases, check examples.
If you have any questions: post on our Slack Channel, or tag your questions on stackoverflow with 'trains' tag.
For feature requests or bug reports, please use GitHub issues.
Additionally, you can always find us at [email protected]
See the TRAINS Guidelines for Contributing.
May the force (and the goddess of learning rates) be with you!