This repository hosts the code for the Ctrl-G framework proposed in the paper Adaptable Logical Control for Large Language Models. Ctrl-G combines any production-ready LLM with a Hidden Markov Model (HMM), enabling LLM outputs to adhere to logical constraints represented as deterministic finite automata (DFAs).
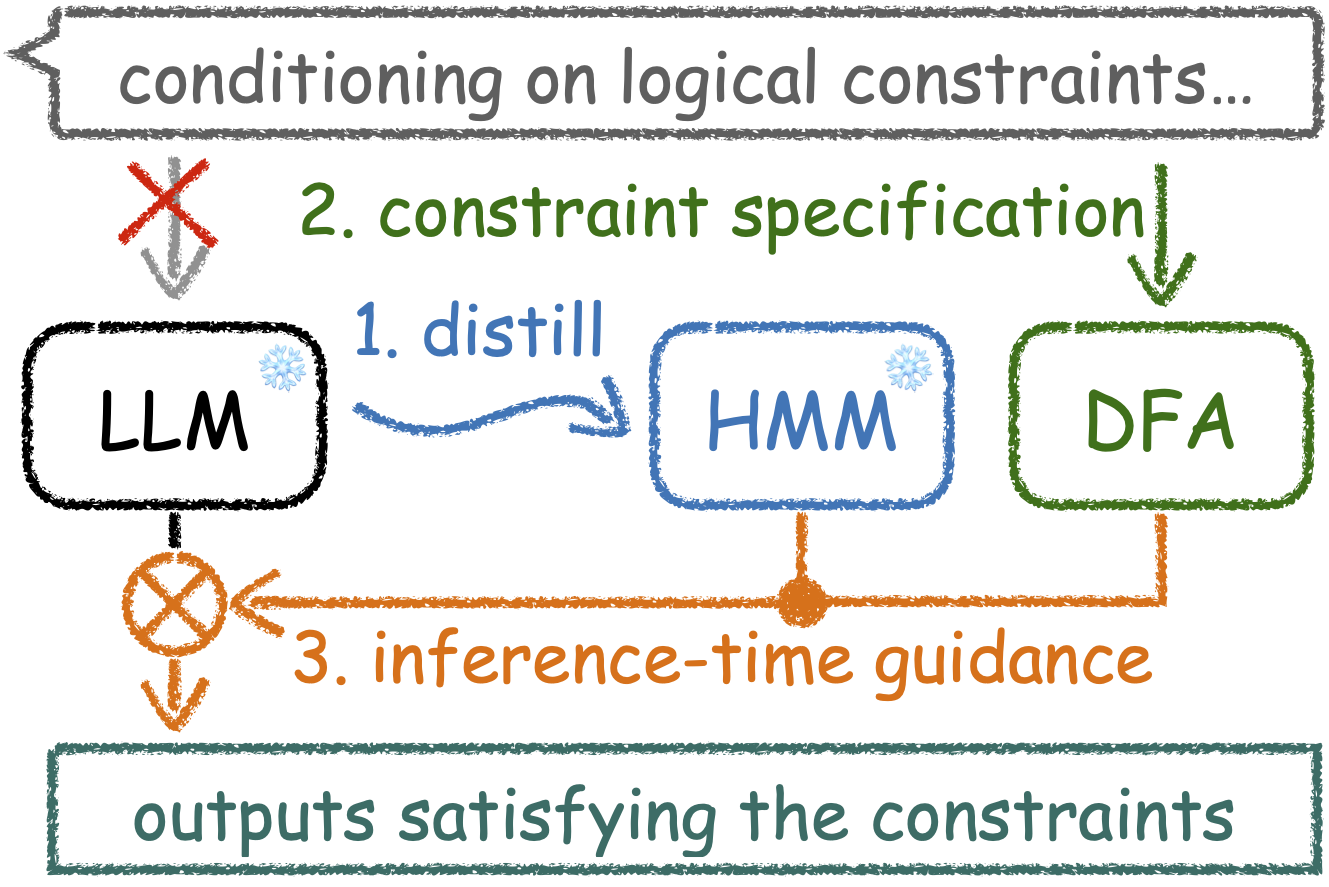
With this codebase, users can impose logical constraints on LLM outputs and implement functionalities including (but not limited to):
- Text infilling: given some text fragments
TEXT_1TEXT_2...TEXT_N, generating infillings at[INSERT]forTEXT_1 [INSERT] TEXT_2 [INSERT] ... [INSERT] TEXT_N. - Keyphrase inclusion: generate text using a given set of keyphrases of arbitrary length.
- Length control: generate text consisting of exactly
atobwords, sentences, paragraphs and etc. - LLM detetoxification: excluding a list of bad words/phrases from LLM generation
- Rhymes: generate text that ends with a word that rhymes with a given word.
- ...
We recommend using conda for setting up the environment for Ctrl-G.
conda create --name ctrlg python=3.11conda activate ctrlgconda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidiaconda install -c pytorch -c nvidia faiss-gpu=1.8.0#only required for HMM distillationpip install transformers==4.41.2 huggingface_hub==0.23.4 sentencepiece protobuf notebook ipywidgetspip install -e .# installing ctrlg locally
For your convenience, we release a variety of LLM checkpoints and their approximating HMMs on huggingface_hub.
[
{
"base_model": "ctrlg/gpt2-large_common-gen",
"hmm_models": [
"ctrlg/hmm_gpt2-large_common-gen_4096",
"ctrlg/hmm_gpt2-large_common-gen_32768"
],
},
{
"base_model": "ctrlg/tulu2-7b_writing-prompts",
"hmm_models": [
"ctrlg/hmm_tulu2-7b_writing-promptss_32768",
],
},
]More checkpoints coming soon! Stay tuned!
The following code blocks are extracted from tutorial_ctrlg.ipynb and we refer readers to the original notebook for a more details.
Here we load from huggingface_hub the pretrained base model checkpoint ctrlg/gpt2-large_common-gen and the corresponding HMM checkpoint ctrlg/hmm_gpt2-large_common-gen_4096.
import os
device = 'cuda'
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # set your cuda device
os.environ['TOKENIZERS_PARALLELISM'] = 'false'
import torch
import ctrlg
from transformers import AutoModelForCausalLM, AutoTokenizer, LogitsProcessorList
BASE_MODEL_PATH = f'ctrlg/gpt2-large_common-gen' # a gpt2-large checkpoint domain adapted to the common-gen corpus
HMM_MODEL_PATH = f'ctrlg/hmm_gpt2-large_common-gen_4096' # alternatively 'ctrlg/hmm_gpt2-large_common-gen_32768' for better quality
base_model = AutoModelForCausalLM.from_pretrained(BASE_MODEL_PATH).to(device)
base_model.eval()
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL_PATH)
hmm_model = ctrlg.HMM.from_pretrained(HMM_MODEL_PATH).to(device)prefix_ids = tokenizer.encode(' on a fine sunny') # generate text starting with ' on a fine sunny'
suffix_ids = tokenizer.encode(' in the park.<|endoftext|>') # generate text ending with ' in the park.<|endoftext|>'
prompt_ids = tokenizer.encode('<|endoftext|> on a fine sunny') # prompt the base model with the '<|endoftext|>' token and the prefix
min_new_tokens = 5
max_new_tokens = 32
vocab_size = hmm_model.vocab_size
eos_token_id = hmm_model.eos_token_id
ac_builder = ctrlg.AhoCorasickBuilder(vocab_size)
word_count_builder = ctrlg.WordCountBuilder(tokenizer, vocab_size)
dfa_graphs = []
# constraint 1: one of [' girl', ' boy', ' girls', ' boys', ' children'] AND one of [' dogs', ' cats', ' dog', ' cat'] have to appear in the GIVEN ORDER.
keyphrases = [[' girl', ' boy', ' girls', ' boys', ' children'],
[' dogs', ' cats', ' dog', ' cat']]
for keyphrase in keyphrases:
patterns = [tokenizer.encode(x) for x in keyphrase]
dfa_graphs.append(ac_builder.build(patterns))
dfa_graphs = [ctrlg.DFA_concatenate(dfa_graphs)] # concatenate the patterns so they appear in the given order
# constraint 2: generate 7 - 12 words
a, b = 7, 12
dfa_graphs.append(word_count_builder.build(a, b))
dfa_graph = ctrlg.DFA_prod(dfa_graphs, mode='intersection') # logical and
dfa_model = ctrlg.DFAModel(dfa_graph, vocab_size).to(device) # compile for GPU inference# initialze the constraints logits processor & pre-computes conditional probabilities
constraint_logits_processor = ctrlg.ConstraintLogitsProcessor(
hmm_model, dfa_model,
min_new_tokens, max_new_tokens,
prompt_ids, prefix_ids=prefix_ids, suffix_ids=suffix_ids)
# set the hmm_batch_size depending on the resource available;
beam_size = 16
constraint_logits_processor.hmm_batch_size = beam_size
# generate with beam search
input_ids = torch.tensor([prompt_ids], device=device)
outputs = base_model.generate(
input_ids=input_ids, do_sample=False,
num_beams=beam_size, num_return_sequences=beam_size,
min_new_tokens=min_new_tokens, max_new_tokens=max_new_tokens,
logits_processor=LogitsProcessorList([constraint_logits_processor]),
pad_token_id=tokenizer.eos_token_id,
)# extract the generated ids;
generated_ids = ctrlg.extract_generated_ids(outputs.tolist(), prompt_ids, suffix_ids, eos_token_id)
# rank the generated ids by the base_model probability
generated_ids = ctrlg.rank_generated_ids(base_model, generated_ids, prompt_ids, suffix_ids)
# print top 10 outputs
for idx, generated in enumerate(generated_ids[:10]):
print(f'{idx}. ' + tokenizer.decode(prefix_ids, skip_special_tokens=True) + \
'\033[1m' + tokenizer.decode(generated, skip_special_tokens=True) + '\033[0m' + \
tokenizer.decode(suffix_ids, skip_special_tokens=True))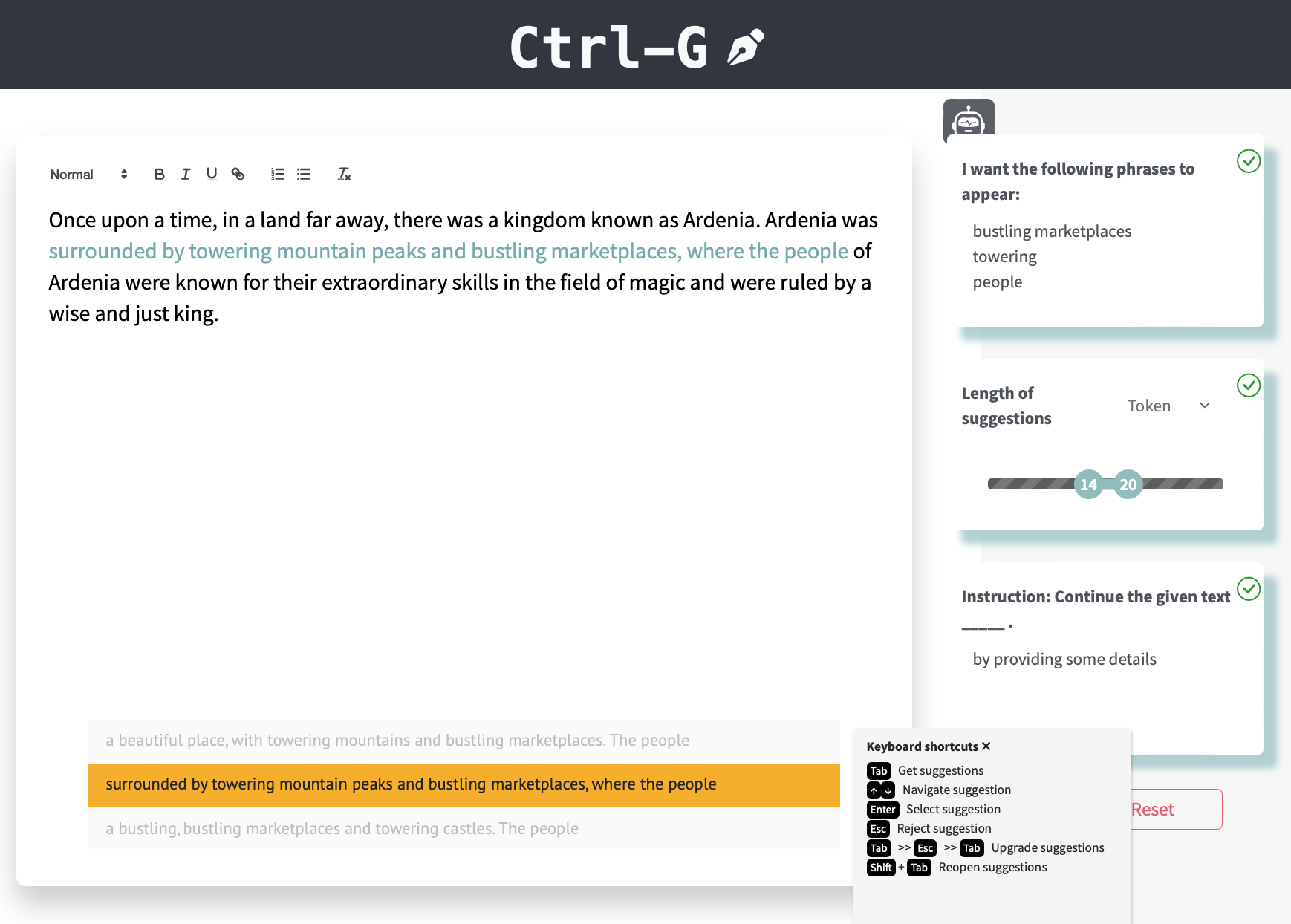
We refer readers to distillation/tutorial_distillation.ipynb for a tutorial on HMM distillation, i.e., given an LLM where we can sample from, train an HMM as its approximation.