


-
🚀 High Performance: Optimized for single-node simulations, BlazeFL allows you to adjust the degree of parallelism. For example, if you want to simulate 100 clients on a single node but lack the resources to run them all concurrently, you can configure 10 parallel processes to manage the simulation efficiently.
-
🔧 Extensibility: BlazeFL provides interfaces solely for communication and parallelization, avoiding excessive abstraction. This design ensures that the framework remains flexible and adaptable to various use cases.
-
📦 Minimal Dependencies: Minimal Dependencies: The core components of BlazeFL rely only on PyTorch, ensuring a lightweight and straightforward setup.
-
🔄 Robust Reproducibility: Even in multi-process environments, BlazeFL offers utilities to save and restore seed states, ensuring consistent and reproducible results across simulations.
-
🏷️ Type Hint Support: The framework fully supports type hints, enhancing code readability and maintainability.
-
🔗 Loose Compatibility with FedLab: Inspired by FedLab, BlazeFL maintains a degree of compatibility, facilitating an easy transition to production-level implementations when necessary.
BlazeFL enhances performance by storing shared parameters on disk instead of shared memory, enabling efficient parameter sharing across processes, simplifying memory management, and reducing overhead.

BlazeFL is available on PyPI and can be installed using your preferred package manager.
For example:
uv add blazefl
# or
poetry add blazefl
# or
pip install blazeflQuick start code is in examples/quickstart-fedavg.
For a more detailed implementation guide, checkout the examples/step-by-step-dsfl.
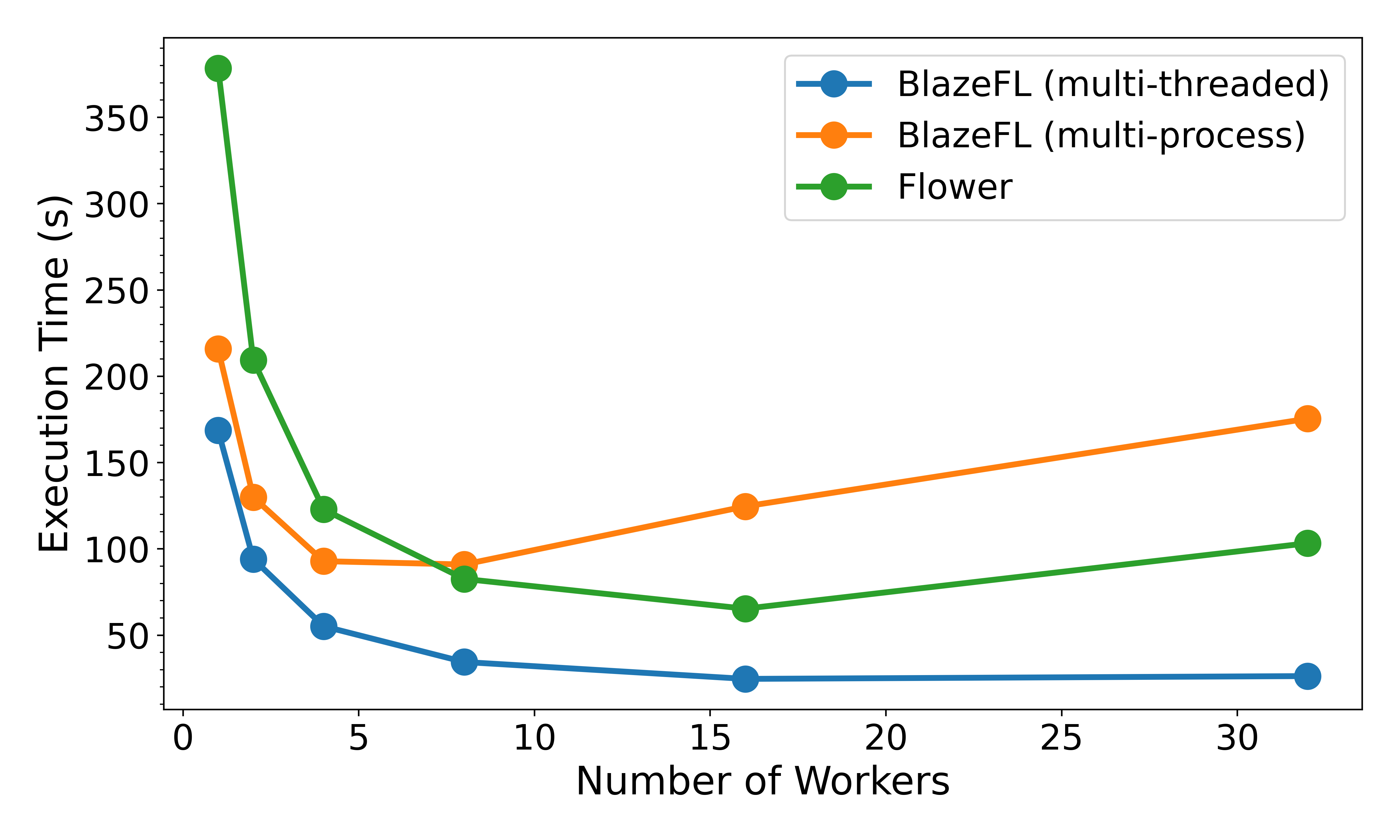
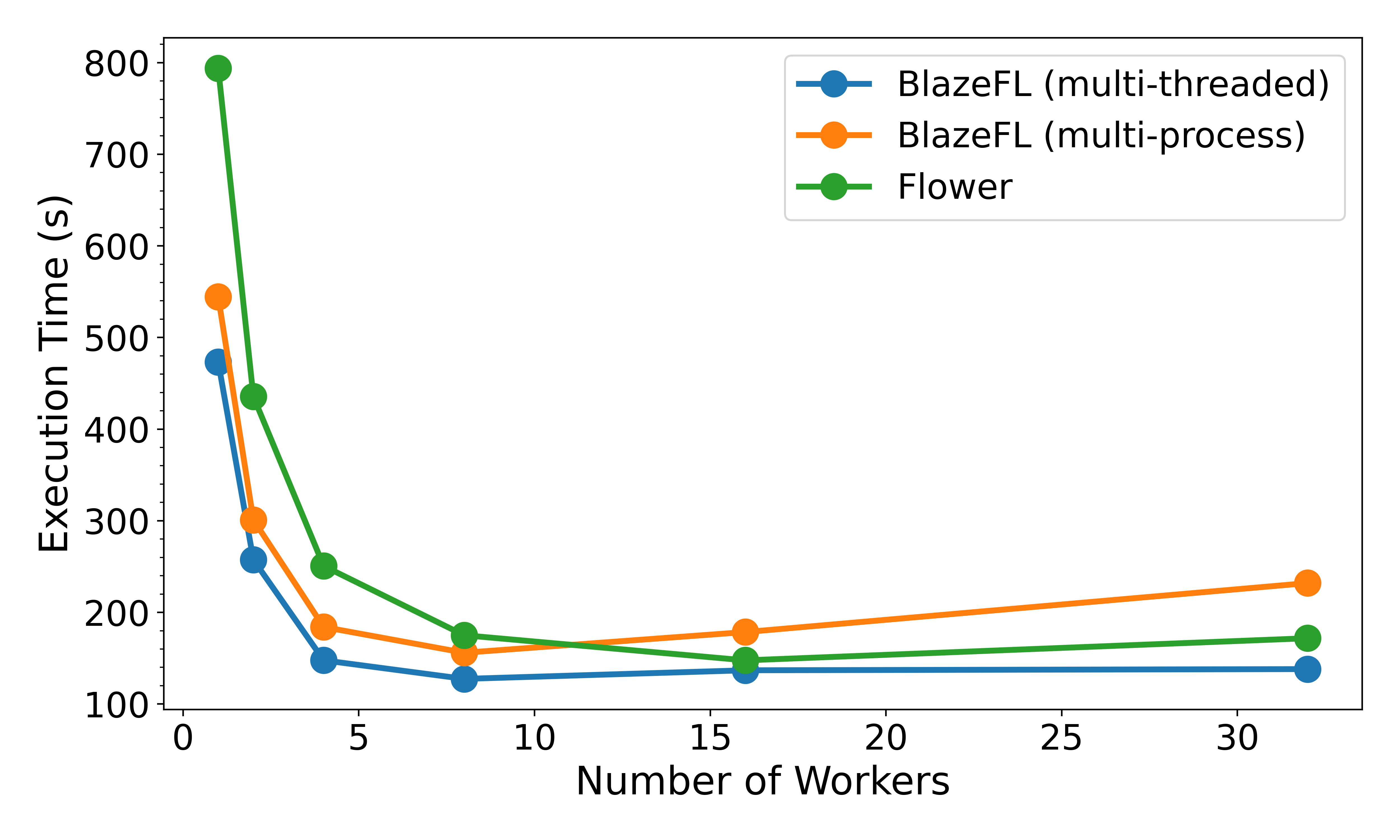
Benchmarks were conducted using Google Cloud’s Compute Engine with the following specifications:
Machine Configuration
- Machine Type: a2-highgpu-1g (vCPU count: 12, VM memory: 85 GB)
- CPU Platform: Intel Cascade Lake
- GPU: 1 x NVIDIA A100 40GB
- Boot Disk: 250 GB SSD
Benchmark Setup
For benchmarking purposes, we utilized Flower’s Quickstart Example as a baseline to evaluate BlazeFL’s performance and efficiency.
We welcome contributions from the community! If you'd like to contribute to this project, please follow these guidelines:
If you encounter a bug, have a feature request, or would like to suggest an improvement, please open an issue on the GitHub repository. Make sure to provide detailed information about the problem or suggestion.
We gladly accept pull requests! Before submitting a pull request, please ensure the following:
- Fork the repository and create your branch from main.
- Ensure your code adheres to the project's coding standards.
- Test your changes thoroughly.
- Make sure your commits are descriptive and well-documented.
- Update the README and any relevant documentation if necessary.
Please note that this project is governed by our Code of Conduct. By participating, you are expected to uphold this code. Please report any unacceptable behavior.
Thank you for contributing to our project!