generated from cotes2020/chirpy-starter
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
24 changed files
with
577 additions
and
11 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -14,9 +14,9 @@ timezone: Asia/Shanghai | |
| # jekyll-seo-tag settings › https://github.com/jekyll/jekyll-seo-tag/blob/master/docs/usage.md | ||
| # ↓ -------------------------- | ||
|
|
||
| title: Here # the main title | ||
| title: Ahern # the main title | ||
|
|
||
| tagline: 广阔天地,大有作为 # it will display as the sub-title | ||
| tagline: 广阔天地,大有作为。 # it will display as the sub-title | ||
|
|
||
| description: >- # used by seo meta and the atom feed | ||
| A minimal, responsive and feature-rich Jekyll theme for technical writing. | ||
|
|
@@ -34,7 +34,7 @@ twitter: | |
| social: | ||
| # Change to your full name. | ||
| # It will be displayed as the default author of the posts and the copyright owner in the Footer | ||
| name: Here | ||
| name: Ahern | ||
| email: [email protected] # change to your email address | ||
| links: | ||
| # The first element serves as the copyright owner's link | ||
|
|
@@ -76,7 +76,7 @@ theme_mode: # [light | dark] | |
| img_cdn: | ||
|
|
||
| # the avatar on sidebar, support local or CORS resources | ||
| avatar: | ||
| avatar: ./assets/avatar.png | ||
|
|
||
| # The URL of the site-wide social preview image used in SEO `og:image` meta tag. | ||
| # It can be overridden by a customized `page.image` in front matter. | ||
|
|
@@ -86,14 +86,14 @@ social_preview_image: # string, local or CORS resources | |
| toc: true | ||
|
|
||
| comments: | ||
| active: # The global switch for posts comments, e.g., 'disqus'. Keep it empty means disable | ||
| active: utterances # The global switch for posts comments, e.g., 'disqus'. Keep it empty means disable | ||
| # The active options are as follows: | ||
| disqus: | ||
| shortname: # fill with the Disqus shortname. › https://help.disqus.com/en/articles/1717111-what-s-a-shortname | ||
| # utterances settings › https://utteranc.es/ | ||
| utterances: | ||
| repo: # <gh-username>/<repo> | ||
| issue_term: # < url | pathname | title | ...> | ||
| repo: li-zeyuan/li-zeyuan.github.io # <gh-username>/<repo> | ||
| issue_term: pathname # < url | pathname | title | ...> | ||
| # Giscus options › https://giscus.app | ||
| giscus: | ||
| repo: # <gh-username>/<repo> | ||
|
|
||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,4 @@ | ||
| ahern: | ||
| name: Ahern | ||
| twitter: https://twitter.com/ahren_utf | ||
| url: https://github.com/li-zeyuan |
This file was deleted.
Oops, something went wrong.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,11 @@ | ||
| --- | ||
| title: 关于架构设计问答 | ||
| date: 2024-03-29 00:00:00 +0800 | ||
| categories: [root, architecture] | ||
| tags: [architecture, interview] | ||
| author: ahern | ||
| --- | ||
|
|
||
| ### 你会如何做架构设计改造?为什么? | ||
| - 模版:1、复杂来源,2、解决方案,3、评估标准,4、技术实现 | ||
| - 参考:https://www.cnblogs.com/edisonchou/p/architecture_design_learning_in_5mins_part3.html |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,193 @@ | ||
| --- | ||
| title: Clickhouse笔记 | ||
| date: 2024-03-29 00:00:00 +0800 | ||
| categories: [root, clickhouse] | ||
| tags: [clickhouse] | ||
| author: ahern | ||
| --- | ||
| ## 概述 | ||
| - 端口8123:tcp转发 | ||
| - 端口9000:http转发 | ||
| - 端口9009:interserverHTTPPort | ||
| - 列式存储:磁盘存储按列存储 | ||
| - 多核并行:分区间并行处理数据(查询,合并等) | ||
| - 多种表引擎:常用MergeTree Family,Log Family,Integrations | ||
| - 写入建议:一批大于1000行,或每秒不超过一个写入请求 | ||
|
|
||
| ## 数据类型 | ||
| - 整型:Int8、Int16、Int32、Int64;UInt8、UInt16、UInt32、UInt64 | ||
| - 浮点型:Float32、Float64 | ||
| - 布尔值:无该类型,用UInt8代替 | ||
| - 字符串:String,FixedString(N) | ||
| - 时间类型:Date,Datetime,Datetime64 | ||
| - LowCardinality: 对数据类型进行二次字典编码;修改底层数据存储 | ||
| - 适用场景:原始数据冗长,去重后的计数值<1000 | ||
| - 优点:降低磁盘存储空间,提高查询性能 | ||
| - 缺点:写性能有所下降 | ||
| - 参考 | ||
| - https://blog.csdn.net/jiangshouzhuang/article/details/103268340 | ||
| - https://github.com/ClickHouse/clickhouse-presentations/blob/master/meetup19/string_optimization.pdf | ||
| - https://blog.csdn.net/jiangshouzhuang/article/details/103268340 | ||
| - 枚举:对比LowCardinality,枚举更加适合静态字典的场景 | ||
| - 数组 | ||
| - 不推荐多维数组 | ||
| - 参考:https://clickhouse.com/docs/en/sql-reference/data-types/ | ||
|
|
||
| ## 目录结构 | ||
| ``` | ||
| root@/data/clickhouse# tree -L 1 | ||
| . | ||
| |-- data // 数据、表元数据 | ||
| |-- format_schemas | ||
| |-- log // ck-server日志文件 | ||
| `-- tmp | ||
| root@/data/clickhouse/data# tree -L 1 | ||
| . | ||
| |-- data // 数据、索引文件 | ||
| |-- dictionaries_lib | ||
| |-- flags | ||
| |-- metadata // 表元数据 | ||
| |-- metadata_dropped | ||
| |-- preprocessed_configs | ||
| |-- status | ||
| `-- store // data下数据文件是以软连接到store目录 | ||
| // 表partition | ||
| root@/data/clickhouse/data/data/{database}/{table}# tree -L 1 | ||
| . | ||
| |-- 20220917_20_20_0 // patition | ||
| |-- 20220917_21_21_0 | ||
| |-- detached // 记录损坏partition | ||
| `-- format_version.txt // version | ||
| // partition目录 | ||
| root@/data/clickhouse/data/data/{database}/{table}/{patition}# tree -L 1 | ||
| . | ||
| |-- checksums.txt // 校验文件 | ||
| |-- columns.txt // 列信息(字段名、类型) | ||
| |-- count.txt // 总数 | ||
| |-- data.bin // 数据 | ||
| |-- data.mrk3 // 数据标记文件,索引文件会用到该标记 | ||
| |-- default_compression_codec.txt // 压缩 | ||
| |-- minmax_timestamp.idx // 分区minimal索引 | ||
| |-- partition.dat // 分区信息 | ||
| `-- primary.idx // 主键索引 | ||
| ``` | ||
| ## partition命名规则 | ||
| ``` | ||
| 20220917_1_1_0 | ||
| [分区名]-[最小分区块编号]-[最大分区块编号]-[合并数次] | ||
| 分区名:跟partition by参数有关,有整数字符串、日期、哈希值 | ||
| 分区块编号:新生成的分区自增 | ||
| 合并数次:合并一次加1 | ||
| ``` | ||
|
|
||
| ## 表引擎 | ||
|
|
||
| #### MergeTree | ||
| - 支持索引和分区 | ||
| - partition by(optional):指定分区规则,一般是按时间 | ||
| - primary key(optional):主键,只提供一级索引,没有唯一约束 | ||
| - order by(required):分区内排序,主键必须是order by字段的前缀字段 | ||
| - settings(optional):一些额外控制参数,如index_granularity索引粒度,默认8192 | ||
| - TTL:支持列ttl,表级ttl | ||
| - 参考:https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree | ||
|
|
||
| #### ReplacingMergeTree | ||
| - 在MergeTree的基础上增加去重功能 | ||
| - 入参为版本字段:如engine =ReplacingMergeTree(create_time) | ||
| - 根据order by字段进行去重,不能跨分区去重 | ||
| - 在分区合并时才进行去重 | ||
| - 参考:https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/replacingmergetree | ||
|
|
||
| #### SummingMergeTree | ||
| - 入参为需要汇总的字段:如ENGINE = SummingMergeTree([columns]) | ||
| - 以order by列为维度 | ||
| - 同一分区才会做聚合处理 | ||
| - 分区合并时进行聚合 | ||
| - 参考:https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/summingmergetree | ||
|
|
||
| #### Distributed | ||
| {:height="10%" width="50%"} | ||
| - 分布式表:逻辑表,对该表进行操作时,会被路由到本地,然后汇总结果返回给用户 | ||
| - 本地表:实际存储数据的表 | ||
| - 常见分布式集群方案: | ||
| - MergeTree + Distributed | ||
| - MergeTree + Distributed+集群复制 | ||
| - ReplicatedMergeTree + Distributed | ||
| - 参考 | ||
| - https://zhuanlan.zhihu.com/p/161242274 | ||
| - https://clickhouse.com/docs/en/engines/table-engines/special/distributed | ||
| - https://www.cnblogs.com/yisany/p/13524018.html | ||
|
|
||
| #### \*MergeTree与Replicated\*MergeTree区别 | ||
| - \*MergeTree数据同步依赖数据库同步机制,不依赖zookeeper | ||
| - Replicated\*MergeTree依赖zookeeper | ||
| - 参考:https://juejin.cn/post/6875235444909408263 | ||
|
|
||
| ## 索引(MergeTree) | ||
| 参考:https://sobriver.top/2021/07/07/%E7%BC%96%E7%A8%8B/clickhouse/clickhouse%E7%B4%A2%E5%BC%95%E5%8E%9F%E7%90%86%E4%BB%8B%E7%BB%8D/ | ||
|
|
||
| #### 主键索引 | ||
| - 没有唯一约束 | ||
| - 稀疏索引 | ||
| - 由建表语句index_granularity指定索引粒度,默认8192 | ||
|
|
||
| #### 分区索引 | ||
| - 记录分区下分区字段对应原始数据的最小和最大值 | ||
| - 查询语句指定分区字段时,通过该索引快速定位到分区 | ||
|
|
||
| #### 跳数索引 | ||
| - INDEX index_name expr TYPE type(...) GRANULARITY granularity_value,type:minmax, set, bloom_filter等 | ||
| - minmax:指定一个值范围 | ||
| - set(max_rows):保存表达式去重复后值,适用重复性高的字段 | ||
| - bloom_filter([false_positive]):布隆过滤器,false_positive为误报率 | ||
| - ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):对String, FixedString 和 Map类型数据有效,可用于优化 EQUALS, LIKE 和 IN表达式。 | ||
| - tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):适用全文搜索 | ||
|
|
||
| #### 稀疏索引 | ||
| - 分区数据已经按order by字段排序,在这个基础上再创建索引(二级索引) | ||
|
|
||
| #### 参考 | ||
| - 类型:https://clickhouse.com/docs/en/guides/improving-query-performance/skipping-indexes#skip-index-types | ||
| - 布隆过滤器参数计算:https://hur.st/bloomfilter/ | ||
| - https://blog.csdn.net/haveanybody/article/details/123919938 | ||
|
|
||
| ## explain | ||
| #### 是否走索引 | ||
| - explain indexes = 1 | ||
| - https://www.modb.pro/db/161379 | ||
|
|
||
| ## 副本同步原理 | ||
| 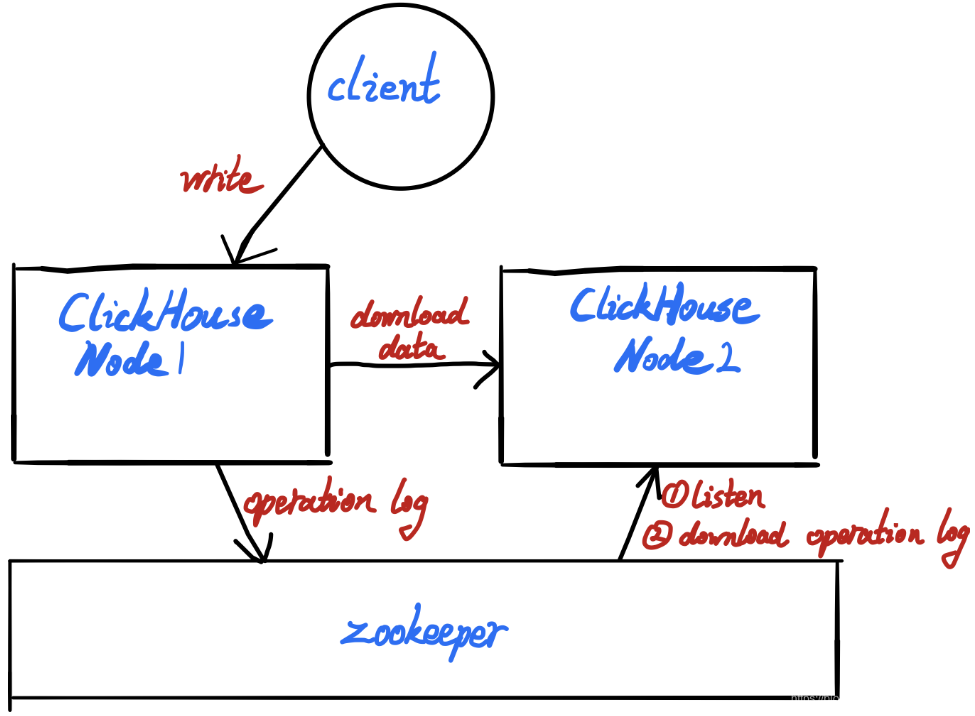{:height="10%" width="50%"} | ||
| - 1、client向某个server1发送写入请求 | ||
| - 2、server1写入本地 | ||
| - 3、同步operation log到zookeeper | ||
| - 4、其他server监听到operation log变化并拉取operation log | ||
| - 5、解析operation log,并从server1拉取数据 | ||
| - 总结: | ||
| - 1、谁处理client请求,谁负责。负责同步operation log数据到zookeeper | ||
| - 2、zookeeper不参与实质的data数据传输,只负责log同步 | ||
|
|
||
| ## 分区操作 | ||
| - 参考:https://clickhouse.com/docs/en/sql-reference/statements/alter/partition | ||
|
|
||
| ## 数据压缩 | ||
| - 数据类型存储:https://aop.pub/artical/database/clickhouse/datatype-storage/ | ||
| - 压缩算法选型:https://blog.csdn.net/neweastsun/article/details/130974311;https://chistadata.com/compression-algorithms-and-codecs-in-clickhouse/ | ||
| - 压缩算法:https://developer.aliyun.com/article/780586 | ||
|
|
||
| ## 总结 | ||
| - clickhouse采用列式存储,适合OLAP场景 | ||
| - 多种数据类型,不支持Bool,LowCardinality对数据类型进行二次编码 | ||
| - 常用MergeTree序列表引擎,关键字段:partition by,primary key,order by,settings | ||
| - 索引:主键索引,分区索引,跳数索引 | ||
| - 常用分区操作 | ||
|
|
||
| ## 参考 | ||
| - 官方文档:https://clickhouse.com/docs/en/intro | ||
| - https://blog.csdn.net/qq_40378034/article/details/120256757 | ||
| - BitMap及其在ClickHouse中的应用:https://zhuanlan.zhihu.com/p/480345952 | ||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,48 @@ | ||
| --- | ||
| title: Clickhouse故障排查 | ||
| date: 2024-03-29 00:00:00 +0800 | ||
| categories: [root, clickhouse] | ||
| tags: [clickhouse,troubleshooting] | ||
| author: ahern | ||
| --- | ||
|
|
||
| ## 写入时间字段(不带时区)时区问题 | ||
|
|
||
| #### 复现 | ||
| 1. insert 语句没有带时区,时间字段的值不会发生变化 | ||
| ```sql | ||
| insert into trace_names_all | ||
| values ('2022-07-15 00:00:08', | ||
| 'test_service_name', | ||
| 'test_span_name'); | ||
| ``` | ||
|
|
||
| 2. 修改clickhouse-server时区:UTC -> UTC+8 | ||
| - 修改前:时区为UTC时插入的数据: | ||
| ```sql | ||
| insert into trace_names_all | ||
| values ('2022-07-15 00:00:00', | ||
| 'test_service_name', | ||
| 'test_span_name'); | ||
| ``` | ||
| - **修改时区后2022-07-15 00:00:00.000 变成 2022-07-15 08:00:00.000,加8小时** | ||
| ┌───────────────timestamp─┬─serviceName───────┬─spanName───────┐ | ||
| │ 2022-07-15 08:00:00.000 │ test_service_name │ test_span_name │ | ||
| └─────────────────────────┴───────────────────┴────────────────┘ | ||
| - 修改后:时区为UTC+8插入的数据: | ||
| ```sql | ||
| insert into trace_names_all | ||
| values ('2022-07-15 00:00:08', | ||
| 'test_service_name', | ||
| 'test_span_name'); | ||
| ``` | ||
| ┌───────────────timestamp─┬─serviceName───────┬─spanName───────┐ | ||
| │ 2022-07-15 00:00:08.000 │ test_service_name │ test_span_name │ | ||
| └─────────────────────────┴───────────────────┴────────────────┘ | ||
|
|
||
| #### 原因 | ||
| 插入时间字段时(不带时区),ch默认该字段时区为ch的时区。 | ||
|
|
||
| #### 解决 | ||
| 无 | ||
|
|
Oops, something went wrong.