- coco_train_script.py is under testing
- General Usage
- Recognition Models
- Detection Models
- Other implemented tensorflow or keras models
- Licenses
- Citing
- Currently recommended TF version is
tensorflow==2.8.0. Expecially for training or TFLite conversion. - Default import
import os import tensorflow as tf import numpy as np import pandas as pd import matplotlib.pyplot as plt from tensorflow import keras
- Install as pip package:
Refer to each sub directory for detail usage.
pip install -U keras-cv-attention-models # Or pip install -U git+https://github.com/leondgarse/keras_cv_attention_models - Basic model prediction
Or just use model preset
from keras_cv_attention_models import volo mm = volo.VOLO_d1(pretrained="imagenet") """ Run predict """ import tensorflow as tf from tensorflow import keras from skimage.data import chelsea img = chelsea() # Chelsea the cat imm = keras.applications.imagenet_utils.preprocess_input(img, mode='torch') pred = mm(tf.expand_dims(tf.image.resize(imm, mm.input_shape[1:3]), 0)).numpy() pred = tf.nn.softmax(pred).numpy() # If classifier activation is not softmax print(keras.applications.imagenet_utils.decode_predictions(pred)[0]) # [('n02124075', 'Egyptian_cat', 0.9692954), # ('n02123045', 'tabby', 0.020203391), # ('n02123159', 'tiger_cat', 0.006867502), # ('n02127052', 'lynx', 0.00017674894), # ('n02123597', 'Siamese_cat', 4.9493494e-05)]
preprocess_inputanddecode_predictionsfrom keras_cv_attention_models import coatnet from skimage.data import chelsea mm = coatnet.CoAtNet0() preds = mm(mm.preprocess_input(chelsea())) print(mm.decode_predictions(preds)) # [[('n02124075', 'Egyptian_cat', 0.9653769), ('n02123159', 'tiger_cat', 0.018427467), ...]
num_classes={custom output classes}others than1000or0will just skip loading the header Dense layer weights. Asmodel.load_weights(weight_file, by_name=True, skip_mismatch=True)is used for loading weights.from keras_cv_attention_models import swin_transformer_v2 mm = swin_transformer_v2.SwinTransformerV2Tiny_window8(num_classes=64) # >>>> Load pretrained from: ~/.keras/models/swin_transformer_v2_tiny_window8_256_imagenet.h5 # WARNING:tensorflow:Skipping loading weights for layer #601 (named predictions) due to mismatch in shape for weight predictions/kernel:0. Weight expects shape (768, 64). Received saved weight with shape (768, 1000) # WARNING:tensorflow:Skipping loading weights for layer #601 (named predictions) due to mismatch in shape for weight predictions/bias:0. Weight expects shape (64,). Received saved weight with shape (1000,)
num_classes=0set for excluding model topGlobalAveragePooling2D + Denselayers.from keras_cv_attention_models import resnest mm = resnest.ResNest50(num_classes=0) print(mm.output_shape) # (None, 7, 7, 2048)
- Reload own model weights by set
pretrained="xxx.h5". Better if reloading model with differentinput_shapeand with weights shape not matching.import os from keras_cv_attention_models import coatnet pretrained = os.path.expanduser('~/.keras/models/coatnet0_224_imagenet.h5') mm = coatnet.CoAtNet1(input_shape=(384, 384, 3), pretrained=pretrained)
- Alias name
kecamcan be used instead ofkeras_cv_attention_models. It's__init__.pyonly with one linefrom keras_cv_attention_models import *.import kecam mm = kecam.yolor.YOLOR_CSP() imm = kecam.test_images.dog_cat() preds = mm(mm.preprocess_input(imm)) bboxs, lables, confidences = mm.decode_predictions(preds)[0] kecam.coco.show_image_with_bboxes(imm, bboxs, lables, confidences)
- Calculate flops method from TF 2.0 Feature: Flops calculation #32809.
from keras_cv_attention_models import coatnet, resnest, model_surgery model_surgery.get_flops(coatnet.CoAtNet0()) # >>>> FLOPs: 4,221,908,559, GFLOPs: 4.2219G model_surgery.get_flops(resnest.ResNest50()) # >>>> FLOPs: 5,378,399,992, GFLOPs: 5.3784G
- Code format is using
line-length=160:find ./* -name "*.py" | grep -v __init__ | grep -v setup.py | xargs -I {} black -l 160 {}
- attention_layers is
__init__.pyonly, which imports core layers defined in model architectures. LikeRelativePositionalEmbeddingfrombotnet,outlook_attentionfromvolo, and many otherPositional Embedding Layers/Attention Blocks.
from keras_cv_attention_models import attention_layers
aa = attention_layers.RelativePositionalEmbedding()
print(f"{aa(tf.ones([1, 4, 14, 16, 256])).shape = }")
# aa(tf.ones([1, 4, 14, 16, 256])).shape = TensorShape([1, 4, 14, 16, 14, 16])- model_surgery including functions used to change model parameters after built.
from keras_cv_attention_models import model_surgery
mm = keras.applications.ResNet50() # Trainable params: 25,583,592
# Replace all ReLU with PReLU. Trainable params: 25,606,312
mm = model_surgery.replace_ReLU(mm, target_activation='PReLU')
# Fuse conv and batch_norm layers. Trainable params: 25,553,192
mm = model_surgery.convert_to_fused_conv_bn_model(mm)- ImageNet contains more detail usage and some comparing results.
- Init Imagenet dataset using tensorflow_datasets #9.
- For custom dataset, recommending method is using
tfds.load, refer Writing custom datasets and Creating private tensorflow_datasets from tfds #48 by @Medicmind. custom_dataset_script.pycan also be used creating ajsonformat file, which can be used as--data_name xxx.jsonfor training, detail usage can be found in Custom recognition dataset.aotnet.AotNet50default parameters set is a typicalResNet50architecture withConv2D use_bias=FalseandpaddinglikePyTorch.- Default parameters for
train_script.pyis likeA3configuration from ResNet strikes back: An improved training procedure in timm withbatch_size=256, input_shape=(160, 160).# `antialias` is default enabled for resize, can be turned off be set `--disable_antialias`. CUDA_VISIBLE_DEVICES='0' TF_XLA_FLAGS="--tf_xla_auto_jit=2" ./train_script.py --seed 0 -s aotnet50
# Evaluation using input_shape (224, 224). # `antialias` usage should be same with training. CUDA_VISIBLE_DEVICES='1' ./eval_script.py -m aotnet50_epoch_103_val_acc_0.7674.h5 -i 224 --central_crop 0.95 # >>>> Accuracy top1: 0.78466 top5: 0.94088
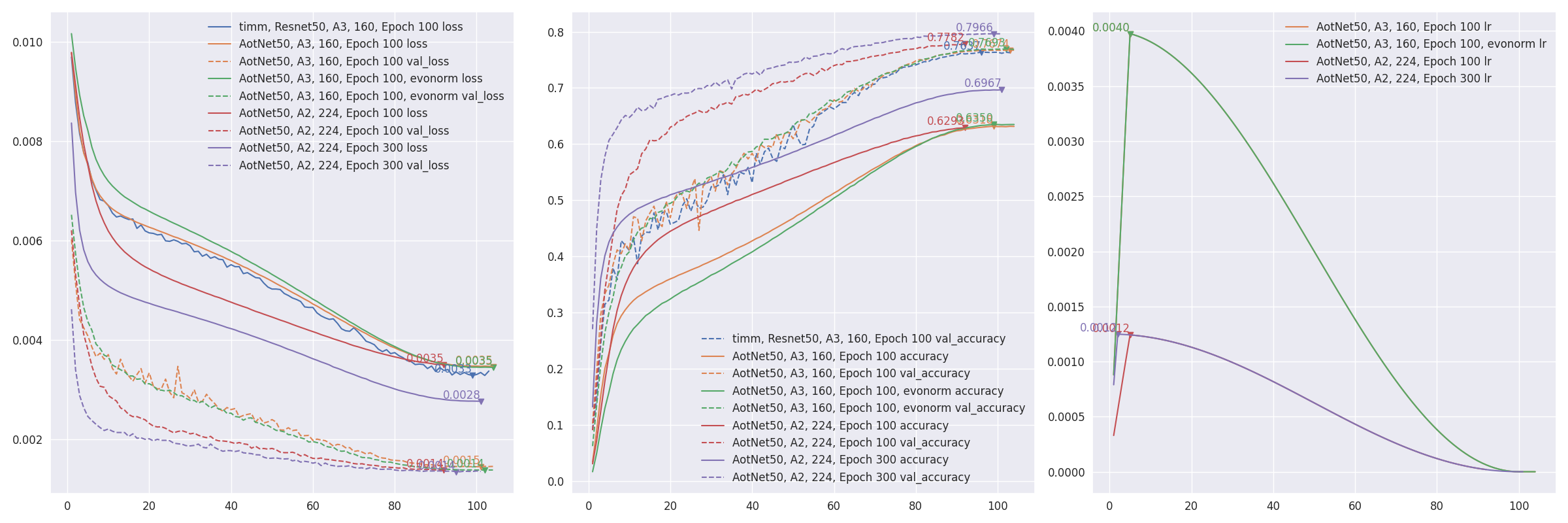
- Restore from break point by setting
--restore_pathand--initial_epoch, and keep other parameters same.restore_pathis higher priority thanmodelandadditional_model_kwargs, also restoreoptimizerandloss.initial_epochis mainly for learning rate scheduler. If not sure where it stopped, checkcheckpoints/{save_name}_hist.json.import json with open("checkpoints/aotnet50_hist.json", "r") as ff: aa = json.load(ff) len(aa['lr']) # 41 ==> 41 epochs are finished, initial_epoch is 41 then, restart from epoch 42
CUDA_VISIBLE_DEVICES='0' TF_XLA_FLAGS="--tf_xla_auto_jit=2" ./train_script.py --seed 0 -r checkpoints/aotnet50_latest.h5 -I 41 # >>>> Restore model from: checkpoints/aotnet50_latest.h5 # Epoch 42/105
eval_script.pyis used for evaluating model accuracy. EfficientNetV2 self tested imagenet accuracy #19 just showing how different parameters affecting model accuracy.# evaluating pretrained builtin model CUDA_VISIBLE_DEVICES='1' ./eval_script.py -m regnet.RegNetZD8 # evaluating pretrained timm model CUDA_VISIBLE_DEVICES='1' ./eval_script.py -m timm.models.resmlp_12_224 --input_shape 224 # evaluating specific h5 model CUDA_VISIBLE_DEVICES='1' ./eval_script.py -m checkpoints/xxx.h5 # evaluating specific tflite model CUDA_VISIBLE_DEVICES='1' ./eval_script.py -m xxx.tflite
- Progressive training refer to PDF 2104.00298 EfficientNetV2: Smaller Models and Faster Training. AotNet50 A3 progressive input shapes
96 128 160:CUDA_VISIBLE_DEVICES='1' TF_XLA_FLAGS="--tf_xla_auto_jit=2" ./progressive_train_script.py \ --progressive_epochs 33 66 -1 \ --progressive_input_shapes 96 128 160 \ --progressive_magnitudes 2 4 6 \ -s aotnet50_progressive_3_lr_steps_100 --seed 0
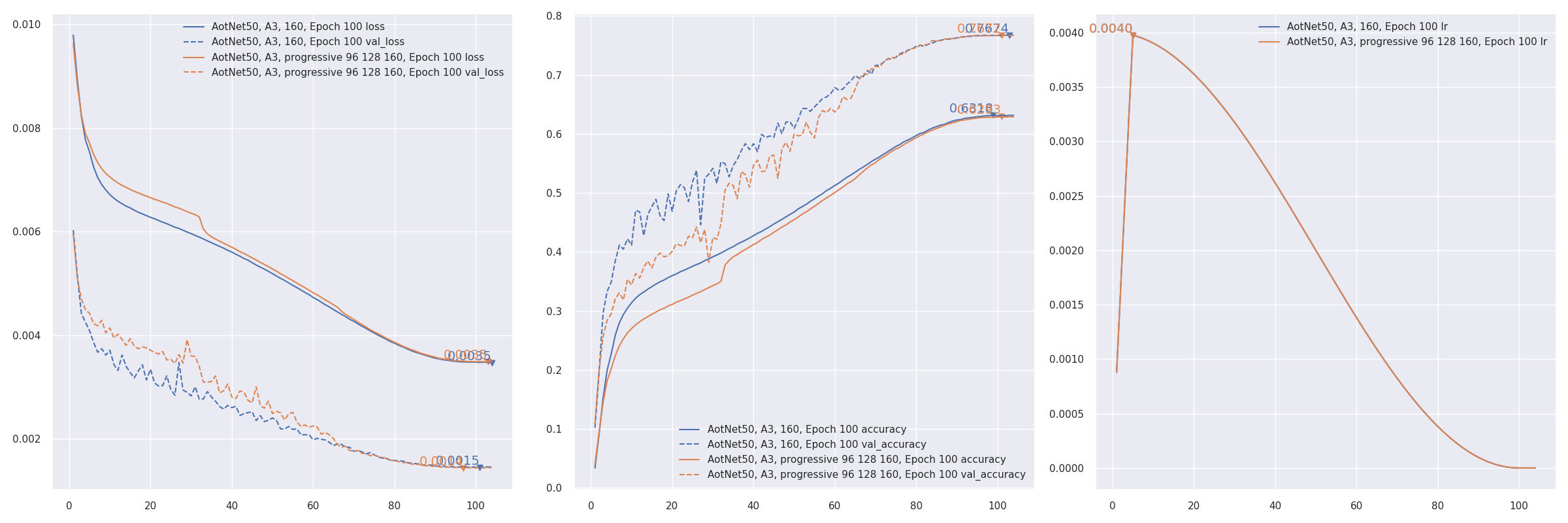
- Transfer learning with
freeze_backboneorfreeze_norm_layers: EfficientNetV2B0 transfer learning on cifar10 testing freezing backbone #55. - Token label train test on CIFAR10 #57. Currently not working as well as expected.
Token labelis implementation of Github zihangJiang/TokenLabeling, paper PDF 2104.10858 All Tokens Matter: Token Labeling for Training Better Vision Transformers.
-
Currently still under testing.
-
COCO contains more detail usage.
-
custom_dataset_script.pycan be used creating ajsonformat file, which can be used as--data_name xxx.jsonfor training, detail usage can be found in Custom detection dataset. -
Default parameters for
coco_train_script.pyisEfficientDetD0withinput_shape=(256, 256, 3), batch_size=64, mosaic_mix_prob=0.5, freeze_backbone_epochs=32, total_epochs=105. Technically, it's anypyramid structure backbone+EfficientDet / YOLOX header / YOLOR header+anchor_free / yolor / efficientdet anchorscombination supported. -
Currently 3 types anchors supported, parameter
anchors_modecontrols which anchor to use, value in["efficientdet", "anchor_free", "yolor"]. DefaultNonefordet_headerpresets.anchors_mode use_object_scores num_anchors anchor_scale aspect_ratios num_scales grid_zero_start efficientdet False 9 4 [1, 2, 0.5] 3 False anchor_free True 1 1 [1] 1 True yolor True 3 None presets None offset=0.5 # Default EfficientDetD0 CUDA_VISIBLE_DEVICES='0' ./coco_train_script.py # Default EfficientDetD0 using input_shape 512, optimizer adamw, freezing backbone 16 epochs, total 50 + 5 epochs CUDA_VISIBLE_DEVICES='0' ./coco_train_script.py -i 512 -p adamw --freeze_backbone_epochs 16 --lr_decay_steps 50 # EfficientNetV2B0 backbone + EfficientDetD0 detection header CUDA_VISIBLE_DEVICES='0' ./coco_train_script.py --backbone efficientnet.EfficientNetV2B0 --det_header efficientdet.EfficientDetD0 # ResNest50 backbone + EfficientDetD0 header using yolox like anchor_free anchors CUDA_VISIBLE_DEVICES='0' ./coco_train_script.py --backbone resnest.ResNest50 --anchors_mode anchor_free # UniformerSmall32 backbone + EfficientDetD0 header using yolor anchors CUDA_VISIBLE_DEVICES='0' ./coco_train_script.py --backbone uniformer.UniformerSmall32 --anchors_mode yolor # Typical YOLOXS with anchor_free anchors CUDA_VISIBLE_DEVICES='0' ./coco_train_script.py --det_header yolox.YOLOXS --freeze_backbone_epochs 0 # YOLOXS with efficientdet anchors CUDA_VISIBLE_DEVICES='0' ./coco_train_script.py --det_header yolox.YOLOXS --anchors_mode efficientdet --freeze_backbone_epochs 0 # CoAtNet0 backbone + YOLOX header with yolor anchors CUDA_VISIBLE_DEVICES='0' ./coco_train_script.py --backbone coatnet.CoAtNet0 --det_header yolox.YOLOX --anchors_mode yolor # Typical YOLOR_P6 with yolor anchors CUDA_VISIBLE_DEVICES='0' ./coco_train_script.py --det_header yolor.YOLOR_P6 --freeze_backbone_epochs 0 # YOLOR_P6 with anchor_free anchors CUDA_VISIBLE_DEVICES='0' ./coco_train_script.py --det_header yolor.YOLOR_P6 --anchors_mode anchor_free --freeze_backbone_epochs 0 # ConvNeXtTiny backbone + YOLOR header with efficientdet anchors CUDA_VISIBLE_DEVICES='0' ./coco_train_script.py --backbone convnext.ConvNeXtTiny --det_header yolor.YOLOR --anchors_mode yolor
Note: COCO training still under testing, may change parameters and default behaviors. Take the risk if would like help developing.
-
coco_eval_script.pyis used for evaluating model AP / AR on COCO validation set. It has a dependencypip install pycocotoolswhich is not in package requirements. More usage can be found in COCO Evaluation.# EfficientDetD0 using resize method bilinear w/o antialias CUDA_VISIBLE_DEVICES='1' ./coco_eval_script.py -m efficientdet.EfficientDetD0 --resize_method bilinear --disable_antialias # >>>> [COCOEvalCallback] input_shape: (512, 512), pyramid_levels: [3, 7], anchors_mode: efficientdet # YOLOX using BGR input format CUDA_VISIBLE_DEVICES='1' ./coco_eval_script.py -m yolox.YOLOXTiny --use_bgr_input --nms_method hard --nms_iou_or_sigma 0.65 # >>>> [COCOEvalCallback] input_shape: (416, 416), pyramid_levels: [3, 5], anchors_mode: anchor_free # YOLOR using letterbox_pad and other tricks. CUDA_VISIBLE_DEVICES='1' ./coco_eval_script.py -m yolor.YOLOR_CSP --nms_method hard --nms_iou_or_sigma 0.65 \ --nms_max_output_size 300 --nms_topk -1 --letterbox_pad 64 --input_shape 704 # >>>> [COCOEvalCallback] input_shape: (704, 704), pyramid_levels: [3, 5], anchors_mode: yolor # Specify h5 model CUDA_VISIBLE_DEVICES='1' ./coco_eval_script.py -m checkpoints/yoloxtiny_yolor_anchor.h5 # >>>> [COCOEvalCallback] input_shape: (416, 416), pyramid_levels: [3, 5], anchors_mode: yolor
- Visualizing is for visualizing convnet filters or attention map scores.
- make_and_apply_gradcam_heatmap is for Grad-CAM class activation visualization.
from keras_cv_attention_models import visualizing, test_images, resnest mm = resnest.ResNest50() img = test_images.dog() superimposed_img, heatmap, preds = visualizing.make_and_apply_gradcam_heatmap(mm, img, layer_name="auto")

- plot_attention_score_maps is model attention score maps visualization.
from keras_cv_attention_models import visualizing, test_images, botnet img = test_images.dog() _ = visualizing.plot_attention_score_maps(botnet.BotNetSE33T(), img)

- Currently
TFLitenot supportingConv2D with groups>1/gelu/tf.image.extract_patches/tf.transpose with len(perm) > 4. Some operations could be supported intf-nightlyversion. May try if encountering issue. More discussion can be found Converting a trained keras CV attention model to TFLite #17. Some speed testing results can be found How to speed up inference on a quantized model #44. tf.nn.gelu(inputs, approximate=True)activation works for TFLite. Define model withactivation="gelu/approximate"oractivation="gelu/app"will setapproximate=Trueforgelu. Should better decide before training, or there may be accuracy loss.- model_surgery.convert_groups_conv2d_2_split_conv2d converts model
Conv2D with groups>1layers toSplitConvusingsplit -> conv -> concat:from keras_cv_attention_models import regnet, model_surgery from keras_cv_attention_models.imagenet import eval_func bb = regnet.RegNetZD32() mm = model_surgery.convert_groups_conv2d_2_split_conv2d(bb) # converts all `Conv2D` using `groups` to `SplitConv2D` test_inputs = np.random.uniform(size=[1, *mm.input_shape[1:]]) print(np.allclose(mm(test_inputs), bb(test_inputs))) # True converter = tf.lite.TFLiteConverter.from_keras_model(mm) open(mm.name + ".tflite", "wb").write(converter.convert()) print(np.allclose(mm(test_inputs), eval_func.TFLiteModelInterf(mm.name + '.tflite')(test_inputs), atol=1e-7)) # True
- model_surgery.convert_gelu_and_extract_patches_for_tflite converts model
geluactivation togelu approximate=True, andtf.image.extract_patchesto aConv2Dversion:from keras_cv_attention_models import cotnet, model_surgery from keras_cv_attention_models.imagenet import eval_func mm = cotnet.CotNetSE50D() mm = model_surgery.convert_groups_conv2d_2_split_conv2d(mm) mm = model_surgery.convert_gelu_and_extract_patches_for_tflite(mm) converter = tf.lite.TFLiteConverter.from_keras_model(mm) open(mm.name + ".tflite", "wb").write(converter.convert()) test_inputs = np.random.uniform(size=[1, *mm.input_shape[1:]]) print(np.allclose(mm(test_inputs), eval_func.TFLiteModelInterf(mm.name + '.tflite')(test_inputs), atol=1e-7)) # True
- model_surgery.prepare_for_tflite is just a combination of above 2 functions:
from keras_cv_attention_models import beit, model_surgery mm = beit.BeitBasePatch16() mm = model_surgery.prepare_for_tflite(mm) converter = tf.lite.TFLiteConverter.from_keras_model(mm) open(mm.name + ".tflite", "wb").write(converter.convert())
- Not supporting
VOLO/HaloNetmodels converting, cause they need a longertf.transposeperm.
- Keras AotNet is just a
ResNet/ResNetV2like framework, that set parameters likeattn_typesandse_ratioand others, which is used to apply different types attention layer. Works likebyoanet/byobnetfromtimm. - Default parameters set is a typical
ResNetarchitecture withConv2D use_bias=FalseandpaddinglikePyTorch.
from keras_cv_attention_models import aotnet
# Mixing se and outlook and halo and mhsa and cot_attention, 21M parameters.
# 50 is just a picked number that larger than the relative `num_block`.
attn_types = [None, "outlook", ["bot", "halo"] * 50, "cot"],
se_ratio = [0.25, 0, 0, 0],
model = aotnet.AotNet50V2(attn_types=attn_types, se_ratio=se_ratio, stem_type="deep", strides=1)
model.summary()| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| BeitBasePatch16, 21k | 86.53M | 17.61G | 224 | 85.240 | beit_base_patch16_224.h5 |
| 86.74M | 55.70G | 384 | 86.808 | beit_base_patch16_384.h5 | |
| BeitLargePatch16, 21k | 304.43M | 61.68G | 224 | 87.476 | beit_large_patch16_224.h5 |
| 305.00M | 191.65G | 384 | 88.382 | beit_large_patch16_384.h5 | |
| 305.67M | 363.46G | 512 | 88.584 | beit_large_patch16_512.h5 |
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| BotNet50 | 21M | 5.42G | 224 | ||
| BotNet101 | 41M | 9.13G | 224 | ||
| BotNet152 | 56M | 12.84G | 224 | ||
| BotNet26T | 12.5M | 3.30G | 256 | 79.246 | botnet26t_256_imagenet.h5 |
| BotNextECA26T | 10.59M | 2.45G | 256 | 79.270 | botnext_eca26t_256_imagenet.h5 |
| BotNetSE33T | 13.7M | 3.89G | 256 | 81.2 | botnet_se33t_256_imagenet.h5 |
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| CMTTiny, (Self trained 105 epochs) | 9.5M | 0.65G | 160 | 77.4 | |
| - 305 epochs | 9.5M | 0.65G | 160 | 78.94 | cmt_tiny_160_imagenet |
| - fine-tuned 224 (69 epochs) | 9.5M | 1.32G | 224 | 80.73 | cmt_tiny_224_imagenet |
| CMTTiny_torch, 1000 epochs | 9.5M | 0.65G | 160 | 79.2 | cmt_tiny_torch_160 |
| CMTXS_torch | 15.2M | 1.58G | 192 | 81.8 | cmt_xs_torch_192 |
| CMTSmall_torch | 25.1M | 4.09G | 224 | 83.5 | cmt_small_torch_224 |
| CMTBase_torch | 45.7M | 9.42G | 256 | 84.5 | cmt_base_torch_256 |
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| CoaTLiteTiny | 5.7M | 1.60G | 224 | 77.5 | coat_lite_tiny_imagenet.h5 |
| CoaTLiteMini | 11M | 2.00G | 224 | 79.1 | coat_lite_mini_imagenet.h5 |
| CoaTLiteSmall | 20M | 3.97G | 224 | 81.9 | coat_lite_small_imagenet.h5 |
| CoaTTiny | 5.5M | 4.33G | 224 | 78.3 | coat_tiny_imagenet.h5 |
| CoaTMini | 10M | 6.78G | 224 | 81.0 | coat_mini_imagenet.h5 |
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| CoAtNet0 (Self trained 105 epochs) | 23.3M | 2.09G | 160 | 80.48 | coatnet0_160_imagenet.h5 |
| - fine-tune 224, 37 epochs | 23.3M | 4.17G | 224 | 82.21 | coatnet0_224_imagenet.h5 |
| CoAtNet0 | 25M | 4.2G | 224 | 81.6 | |
| CoAtNet0, Stride-2 DConv2D | 25M | 4.6G | 224 | 82.0 | |
| CoAtNet1 | 42M | 8.4G | 224 | 83.3 | |
| CoAtNet1, Stride-2 DConv2D | 42M | 8.8G | 224 | 83.5 | |
| CoAtNet2 | 75M | 15.7G | 224 | 84.1 | |
| CoAtNet2, Stride-2 DConv2D | 75M | 16.6G | 224 | 84.1 | |
| CoAtNet2, ImageNet-21k pretrain | 75M | 16.6G | 224 | 87.1 | |
| CoAtNet3 | 168M | 34.7G | 224 | 84.5 | |
| CoAtNet3, ImageNet-21k pretrain | 168M | 34.7G | 224 | 87.6 | |
| CoAtNet3, ImageNet-21k pretrain | 168M | 203.1G | 512 | 87.9 | |
| CoAtNet4, ImageNet-21k pretrain | 275M | 360.9G | 512 | 88.1 | |
| CoAtNet4, ImageNet-21K + PT-RA-E150 | 275M | 360.9G | 512 | 88.56 |
JFT pre-trained models accuracy
| Model | Input | Reported Params | self-defined Params | Top1 Acc |
|---|---|---|---|---|
| CoAtNet3, Stride-2 DConv2D | 384 | 168M, FLOPs 114G | 160.64M, FLOPs 109.67G | 88.52 |
| CoAtNet3, Stride-2 DConv2D | 512 | 168M, FLOPs 214G | 161.24M, FLOPs 205.06G | 88.81 |
| CoAtNet4 | 512 | 275M, FLOPs 361G | 270.69M, FLOPs 359.77G | 89.11 |
| CoAtNet5 | 512 | 688M, FLOPs 812G | 676.23M, FLOPs 807.06G | 89.77 |
| CoAtNet6 | 512 | 1.47B, FLOPs 1521G | 1.336B, FLOPs 1470.56G | 90.45 |
| CoAtNet7 | 512 | 2.44B, FLOPs 2586G | 2.413B, FLOPs 2537.56G | 90.88 |
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| ConvNeXtTiny | 28M | 4.49G | 224 | 82.1 | tiny_imagenet.h5 |
| - ImageNet21k-ft1k | 28M | 4.49G | 224 | 82.9 | tiny_224_21k.h5 |
| - ImageNet21k-ft1k | 28M | 13.19G | 384 | 84.1 | tiny_384_21k.h5 |
| ConvNeXtSmall | 50M | 8.73G | 224 | 83.1 | small_imagenet.h5 |
| - ImageNet21k-ft1k | 50M | 8.73G | 224 | 84.6 | small_224_21k.h5 |
| - ImageNet21k-ft1k | 50M | 25.67G | 384 | 85.8 | small_384_21k.h5 |
| ConvNeXtBase | 89M | 15.42G | 224 | 83.8 | base_224_imagenet.h5 |
| ConvNeXtBase | 89M | 45.32G | 384 | 85.1 | base_384_imagenet.h5 |
| - ImageNet21k-ft1k | 89M | 15.42G | 224 | 85.8 | base_224_21k.h5 |
| - ImageNet21k-ft1k | 89M | 45.32G | 384 | 86.8 | base_384_21k.h5 |
| ConvNeXtLarge | 198M | 34.46G | 224 | 84.3 | large_224_imagenet.h5 |
| ConvNeXtLarge | 198M | 101.28G | 384 | 85.5 | large_384_imagenet.h5 |
| - ImageNet21k-ft1k | 198M | 34.46G | 224 | 86.6 | large_224_21k.h5 |
| - ImageNet21k-ft1k | 198M | 101.28G | 384 | 87.5 | large_384_21k.h5 |
| ConvNeXtXLarge, 21k | 350M | 61.06G | 224 | 87.0 | xlarge_224_21k.h5 |
| ConvNeXtXLarge, 21k | 350M | 179.43G | 384 | 87.8 | xlarge_384_21k.h5 |
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| CotNet50 | 22.2M | 3.25G | 224 | 81.3 | cotnet50_224_imagenet.h5 |
| CotNeXt50 | 30.1M | 4.3G | 224 | 82.1 | |
| CotNetSE50D | 23.1M | 4.05G | 224 | 81.6 | cotnet_se50d_224_imagenet.h5 |
| CotNet101 | 38.3M | 6.07G | 224 | 82.8 | cotnet101_224_imagenet.h5 |
| CotNeXt101 | 53.4M | 8.2G | 224 | 83.2 | |
| CotNetSE101D | 40.9M | 8.44G | 224 | 83.2 | cotnet_se101d_224_imagenet.h5 |
| CotNetSE152D | 55.8M | 12.22G | 224 | 84.0 | cotnet_se152d_224_imagenet.h5 |
| CotNetSE152D | 55.8M | 24.92G | 320 | 84.6 | cotnet_se152d_320_imagenet.h5 |
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| DaViT_T | 28.36M | 4.56G | 224 | 82.8 | davit_t_imagenet.h5 |
| DaViT_S | 49.75M | 8.83G | 224 | 84.2 | davit_s_imagenet.h5 |
| DaViT_B | 87.95M | 15.55G | 224 | 84.6 | davit_b_imagenet.h5 |
| DaViT_L, 21k | 196.8M | 103.2G | 384 | 87.5 | |
| DaViT_H, 1.5B | 348.9M | 327.3G | 512 | 90.2 | |
| DaViT_G, 1.5B | 1.406B | 1.022T | 512 | 90.4 |
- Keras EdgeNeXt is for PDF 2206.10589 EdgeNeXt: Efficiently Amalgamated CNN-Transformer Architecture for Mobile Vision Applications.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| EdgeNeXt_XX_Small | 1.33M | 266M | 256 | 71.23 | edgenext_xx_small_256_imagenet.h5 |
| EdgeNeXt_X_Small | 2.34M | 547M | 256 | 74.96 | edgenext_x_small_256_imagenet.h5 |
| EdgeNeXt_Small | 5.59M | 1.27G | 256 | 79.41 | edgenext_small_256_imagenet.h5 |
| - usi | 5.59M | 1.27G | 256 | 81.07 | edgenext_small_256_usi.h5 |
- Keras EfficientFormer is for PDF 2206.01191 EfficientFormer: Vision Transformers at MobileNet Speed.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| EfficientFormerL1, distill | 12.3M | 1.31G | 224 | 79.2 | l1_224_imagenet.h5 |
| EfficientFormerL3, distill | 31.4M | 3.95G | 224 | 82.4 | l3_224_imagenet.h5 |
| EfficientFormerL7, distill | 74.4M | 9.79G | 224 | 83.3 | l7_224_imagenet.h5 |
- Keras EfficientNet includes implementation of PDF 2104.00298 EfficientNetV2: Smaller Models and Faster Training.
| V2 Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| EfficientNetV2B0 | 7.1M | 0.72G | 224 | 78.7 | effv2b0-imagenet.h5 |
| - ImageNet21k-ft1k | 7.1M | 0.72G | 224 | 77.55? | effv2b0-21k-ft1k.h5 |
| EfficientNetV2B1 | 8.1M | 1.21G | 240 | 79.8 | effv2b1-imagenet.h5 |
| - ImageNet21k-ft1k | 8.1M | 1.21G | 240 | 79.03? | effv2b1-21k-ft1k.h5 |
| EfficientNetV2B2 | 10.1M | 1.71G | 260 | 80.5 | effv2b2-imagenet.h5 |
| - ImageNet21k-ft1k | 10.1M | 1.71G | 260 | 79.48? | effv2b2-21k-ft1k.h5 |
| EfficientNetV2B3 | 14.4M | 3.03G | 300 | 82.1 | effv2b3-imagenet.h5 |
| - ImageNet21k-ft1k | 14.4M | 3.03G | 300 | 82.46? | effv2b3-21k-ft1k.h5 |
| EfficientNetV2T | 13.6M | 3.18G | 288 | 82.34 | effv2t-imagenet.h5 |
| EfficientNetV2T_GC | 13.7M | 3.19G | 288 | 82.46 | effv2t-gc-imagenet.h5 |
| EfficientNetV2S | 21.5M | 8.41G | 384 | 83.9 | effv2s-imagenet.h5 |
| - ImageNet21k-ft1k | 21.5M | 8.41G | 384 | 84.9 | effv2s-21k-ft1k.h5 |
| EfficientNetV2M | 54.1M | 24.69G | 480 | 85.2 | effv2m-imagenet.h5 |
| - ImageNet21k-ft1k | 54.1M | 24.69G | 480 | 86.2 | effv2m-21k-ft1k.h5 |
| EfficientNetV2L | 119.5M | 56.27G | 480 | 85.7 | effv2l-imagenet.h5 |
| - ImageNet21k-ft1k | 119.5M | 56.27G | 480 | 86.9 | effv2l-21k-ft1k.h5 |
| EfficientNetV2XL, 21k-ft1k | 206.8M | 93.66G | 512 | 87.2 | effv2xl-21k-ft1k.h5 |
| V1 Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| EfficientNetV1B0 | 5.3M | 0.39G | 224 | 77.6 | effv1-b0-imagenet.h5 |
| - NoisyStudent | 5.3M | 0.39G | 224 | 78.8 | effv1-b0-noisy_student.h5 |
| EfficientNetV1B1 | 7.8M | 0.70G | 240 | 79.6 | effv1-b1-imagenet.h5 |
| - NoisyStudent | 7.8M | 0.70G | 240 | 81.5 | effv1-b1-noisy_student.h5 |
| EfficientNetV1B2 | 9.1M | 1.01G | 260 | 80.5 | effv1-b2-imagenet.h5 |
| - NoisyStudent | 9.1M | 1.01G | 260 | 82.4 | effv1-b2-noisy_student.h5 |
| EfficientNetV1B3 | 12.2M | 1.86G | 300 | 81.9 | effv1-b3-imagenet.h5 |
| - NoisyStudent | 12.2M | 1.86G | 300 | 84.1 | effv1-b3-noisy_student.h5 |
| EfficientNetV1B4 | 19.3M | 4.46G | 380 | 83.3 | effv1-b4-imagenet.h5 |
| - NoisyStudent | 19.3M | 4.46G | 380 | 85.3 | effv1-b4-noisy_student.h5 |
| EfficientNetV1B5 | 30.4M | 10.40G | 456 | 84.3 | effv1-b5-imagenet.h5 |
| - NoisyStudent | 30.4M | 10.40G | 456 | 86.1 | effv1-b5-noisy_student.h5 |
| EfficientNetV1B6 | 43.0M | 19.29G | 528 | 84.8 | effv1-b6-imagenet.h5 |
| - NoisyStudent | 43.0M | 19.29G | 528 | 86.4 | effv1-b6-noisy_student.h5 |
| EfficientNetV1B7 | 66.3M | 38.13G | 600 | 85.2 | effv1-b7-imagenet.h5 |
| - NoisyStudent | 66.3M | 38.13G | 600 | 86.9 | effv1-b7-noisy_student.h5 |
| EfficientNetV1L2, NoisyStudent | 480.3M | 477.98G | 800 | 88.4 | effv1-l2-noisy_student.h5 |
- Keras FBNetV3 includes implementation of PDF 2006.02049 FBNetV3: Joint Architecture-Recipe Search using Predictor Pretraining.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| FBNetV3B | 5.57M | 539.82M | 256 | 79.15 | fbnetv3_b_imagenet.h5 |
| FBNetV3D | 10.31M | 665.02M | 256 | 79.68 | fbnetv3_d_imagenet.h5 |
| FBNetV3G | 16.62M | 1379.30M | 256 | 82.05 | fbnetv3_g_imagenet.h5 |
- Keras GCViT includes implementation of PDF 2206.09959 Global Context Vision Transformers.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| GCViT_XXTiny | 12.0M | 2.15G | 224 | 79.6 | |
| GCViT_XTiny | 20.0M | 2.96G | 224 | 81.9 | |
| GCViT_Tiny | 28.2M | 4.83G | 224 | 83.2 | gcvit_tiny_224_imagenet.h5 |
| GCViT_Small | 51.1M | 8.63G | 224 | 83.9 | gcvit_small_224_imagenet.h5 |
| GCViT_Base | 90.3M | 14.9G | 224 | 84.4 | gcvit_base_224_imagenet.h5 |
- Keras GMLP includes implementation of PDF 2105.08050 Pay Attention to MLPs.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| GMLPTiny16 | 6M | 1.35G | 224 | 72.3 | |
| GMLPS16 | 20M | 4.44G | 224 | 79.6 | gmlp_s16_imagenet.h5 |
| GMLPB16 | 73M | 15.82G | 224 | 81.6 |
- Keras HaloNet is for PDF 2103.12731 Scaling Local Self-Attention for Parameter Efficient Visual Backbones.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| HaloNetH0 | 5.5M | 2.40G | 256 | 77.9 | |
| HaloNetH1 | 8.1M | 3.04G | 256 | 79.9 | |
| HaloNetH2 | 9.4M | 3.37G | 256 | 80.4 | |
| HaloNetH3 | 11.8M | 6.30G | 320 | 81.9 | |
| HaloNetH4 | 19.1M | 12.17G | 384 | 83.3 | |
| - 21k | 19.1M | 12.17G | 384 | 85.5 | |
| HaloNetH5 | 30.7M | 32.61G | 448 | 84.0 | |
| HaloNetH6 | 43.4M | 53.20G | 512 | 84.4 | |
| HaloNetH7 | 67.4M | 119.64G | 600 | 84.9 | |
| HaloNextECA26T | 10.7M | 2.43G | 256 | 79.50 | halonext_eca26t_256_imagenet.h5 |
| HaloNet26T | 12.5M | 3.18G | 256 | 79.13 | halonet26t_256_imagenet.h5 |
| HaloNetSE33T | 13.7M | 3.55G | 256 | 80.99 | halonet_se33t_256_imagenet.h5 |
| HaloRegNetZB | 11.68M | 1.97G | 224 | 81.042 | haloregnetz_b_224_imagenet.h5 |
| HaloNet50T | 22.7M | 5.29G | 256 | 81.70 | halonet50t_256_imagenet.h5 |
| HaloBotNet50T | 22.6M | 5.02G | 256 | 82.0 | halobotnet50t_256_imagenet.h5 |
- Keras LCNet includes implementation of PDF 2109.15099 PP-LCNet: A Lightweight CPU Convolutional Neural Network.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| LCNet050 | 1.88M | 46.02M | 224 | 63.10 | lcnet_050_imagenet.h5 |
| LCNet075 | 2.36M | 96.82M | 224 | 68.82 | lcnet_075_imagenet.h5 |
| LCNet100 | 2.95M | 158.28M | 224 | 72.10 | lcnet_100_imagenet.h5 |
| LCNet150 | 4.52M | 338.05M | 224 | 73.71 | lcnet_150_imagenet.h5 |
| LCNet200 | 6.54M | 585.35M | 224 | 75.18 | lcnet_200_imagenet.h5 |
| LCNet250 | 9.04M | 900.16M | 224 | 76.60 | lcnet_250_imagenet.h5 |
- Keras LeViT is for PDF 2104.01136 LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| LeViT128S, distillation | 7.8M | 0.31G | 224 | 76.6 | levit128s_imagenet.h5 |
| LeViT128, distillation | 9.2M | 0.41G | 224 | 78.6 | levit128_imagenet.h5 |
| LeViT192, distillation | 11M | 0.66G | 224 | 80.0 | levit192_imagenet.h5 |
| LeViT256, distillation | 19M | 1.13G | 224 | 81.6 | levit256_imagenet.h5 |
| LeViT384, distillation | 39M | 2.36G | 224 | 82.6 | levit384_imagenet.h5 |
- Keras MLP mixer includes implementation of PDF 2105.01601 MLP-Mixer: An all-MLP Architecture for Vision.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| MLPMixerS32, JFT | 19.1M | 1.01G | 224 | 68.70 | |
| MLPMixerS16, JFT | 18.5M | 3.79G | 224 | 73.83 | |
| MLPMixerB32, JFT | 60.3M | 3.25G | 224 | 75.53 | |
| - imagenet_sam | 60.3M | 3.25G | 224 | 72.47 | b32_imagenet_sam.h5 |
| MLPMixerB16 | 59.9M | 12.64G | 224 | 76.44 | b16_imagenet.h5 |
| - imagenet21k | 59.9M | 12.64G | 224 | 80.64 | b16_imagenet21k.h5 |
| - imagenet_sam | 59.9M | 12.64G | 224 | 77.36 | b16_imagenet_sam.h5 |
| - JFT | 59.9M | 12.64G | 224 | 80.00 | |
| MLPMixerL32, JFT | 206.9M | 11.30G | 224 | 80.67 | |
| MLPMixerL16 | 208.2M | 44.66G | 224 | 71.76 | l16_imagenet.h5 |
| - imagenet21k | 208.2M | 44.66G | 224 | 82.89 | l16_imagenet21k.h5 |
| - input 448 | 208.2M | 178.54G | 448 | 83.91 | |
| - input 224, JFT | 208.2M | 44.66G | 224 | 84.82 | |
| - input 448, JFT | 208.2M | 178.54G | 448 | 86.78 | |
| MLPMixerH14, JFT | 432.3M | 121.22G | 224 | 86.32 | |
| - input 448, JFT | 432.3M | 484.73G | 448 | 87.94 |
- Keras MobileNetV3 includes implementation of PDF 1905.02244 Searching for MobileNetV3.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| MobileNetV3Small050 | 1.29M | 24.92M | 224 | 57.89 | small_050_imagenet.h5 |
| MobileNetV3Small075 | 2.04M | 44.35M | 224 | 65.24 | small_075_imagenet.h5 |
| MobileNetV3Small100 | 2.54M | 57.62M | 224 | 67.66 | small_100_imagenet.h5 |
| MobileNetV3Large075 | 3.99M | 156.30M | 224 | 73.44 | large_075_imagenet.h5 |
| MobileNetV3Large100 | 5.48M | 218.73M | 224 | 75.77 | large_100_imagenet.h5 |
| - miil | 5.48M | 218.73M | 224 | 77.92 | large_100_miil.h5 |
- Keras MobileViT is for PDF 2110.02178 MOBILEVIT: LIGHT-WEIGHT, GENERAL-PURPOSE, AND MOBILE-FRIENDLY VISION TRANSFORMER.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| MobileViT_XXS | 1.3M | 0.42G | 256 | 69.0 | mobilevit_xxs_imagenet |
| MobileViT_XS | 2.3M | 1.05G | 256 | 74.7 | mobilevit_xs_imagenet |
| MobileViT_S | 5.6M | 2.03G | 256 | 78.3 | mobilevit_s_imagenet |
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| MobileViT_V2_050 | 1.37M | 0.47G | 256 | 70.18 | v2_050_256_imagenet.h5 |
| MobileViT_V2_075 | 2.87M | 1.04G | 256 | 75.56 | v2_075_256_imagenet.h5 |
| MobileViT_V2_100 | 4.90M | 1.83G | 256 | 78.09 | v2_100_256_imagenet.h5 |
| MobileViT_V2_125 | 7.48M | 2.84G | 256 | 79.65 | v2_125_256_imagenet.h5 |
| MobileViT_V2_150 | 10.6M | 4.07G | 256 | 80.38 | v2_150_256_imagenet.h5 |
| - imagenet22k | 10.6M | 4.07G | 256 | 81.46 | v2_150_256_imagenet22k.h5 |
| - imagenet22k, 384 | 10.6M | 9.15G | 384 | 82.60 | v2_150_384_imagenet22k.h5 |
| MobileViT_V2_175 | 14.3M | 5.52G | 256 | 80.84 | v2_175_256_imagenet.h5 |
| - imagenet22k | 14.3M | 5.52G | 256 | 81.94 | v2_175_256_imagenet22k.h5 |
| - imagenet22k, 384 | 14.3M | 12.4G | 384 | 82.93 | v2_175_384_imagenet22k.h5 |
| MobileViT_V2_200 | 18.4M | 7.12G | 256 | 81.17 | v2_200_256_imagenet.h5 |
| - imagenet22k | 18.4M | 7.12G | 256 | 82.36 | v2_200_256_imagenet22k.h5 |
| - imagenet22k, 384 | 18.4M | 16.2G | 384 | 83.41 | v2_200_384_imagenet22k.h5 |
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| NAT_Mini | 20.0M | 2.73G | 224 | 81.8 | nat_mini_imagenet.h5 |
| NAT_Tiny | 27.9M | 4.34G | 224 | 83.2 | nat_tiny_imagenet.h5 |
| NAT_Small | 50.7M | 7.84G | 224 | 83.7 | nat_small_imagenet.h5 |
| NAT_Base | 89.8M | 13.76G | 224 | 84.3 | nat_base_imagenet.h5 |
- Keras NFNets is for PDF 2102.06171 High-Performance Large-Scale Image Recognition Without Normalization.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| NFNetL0 | 35.07M | 7.13G | 288 | 82.75 | nfnetl0_imagenet.h5 |
| NFNetF0 | 71.5M | 12.58G | 256 | 83.6 | nfnetf0_imagenet.h5 |
| NFNetF1 | 132.6M | 35.95G | 320 | 84.7 | nfnetf1_imagenet.h5 |
| NFNetF2 | 193.8M | 63.24G | 352 | 85.1 | nfnetf2_imagenet.h5 |
| NFNetF3 | 254.9M | 115.75G | 416 | 85.7 | nfnetf3_imagenet.h5 |
| NFNetF4 | 316.1M | 216.78G | 512 | 85.9 | nfnetf4_imagenet.h5 |
| NFNetF5 | 377.2M | 291.73G | 544 | 86.0 | nfnetf5_imagenet.h5 |
| NFNetF6 SAM | 438.4M | 379.75G | 576 | 86.5 | nfnetf6_imagenet.h5 |
| NFNetF7 | 499.5M | 481.80G | 608 | ||
| ECA_NFNetL0 | 24.14M | 7.12G | 288 | 82.58 | eca_nfnetl0_imagenet.h5 |
| ECA_NFNetL1 | 41.41M | 14.93G | 320 | 84.01 | eca_nfnetl1_imagenet.h5 |
| ECA_NFNetL2 | 56.72M | 30.12G | 384 | 84.70 | eca_nfnetl2_imagenet.h5 |
| ECA_NFNetL3 | 72.04M | 52.73G | 448 |
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| RegNetY040 | 20.65M | 3.98G | 224 | 82.3 | regnety_040_imagenet.h5 |
| RegNetY064 | 30.58M | 6.36G | 224 | 83.0 | regnety_064_imagenet.h5 |
| RegNetY080 | 39.18M | 7.97G | 224 | 83.17 | regnety_080_imagenet.h5 |
| RegNetY160 | 83.59M | 15.92G | 224 | 82.0 | regnety_160_imagenet.h5 |
| RegNetY320 | 145.05M | 32.29G | 224 | 82.5 | regnety_320_imagenet.h5 |
- Keras RegNetZ includes implementation of Github timm/models/byobnet.py.
- Related paper PDF 2004.02967 Evolving Normalization-Activation Layers
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| RegNetZB16 | 9.72M | 1.44G | 224 | 79.868 | regnetz_b16_imagenet.h5 |
| RegNetZC16 | 13.46M | 2.50G | 256 | 82.164 | regnetz_c16_imagenet.h5 |
| RegNetZC16_EVO | 13.49M | 2.55G | 256 | 81.9 | regnetz_c16_evo_imagenet.h5 |
| RegNetZD32 | 27.58M | 5.96G | 256 | 83.422 | regnetz_d32_imagenet.h5 |
| RegNetZD8 | 23.37M | 3.95G | 256 | 83.5 | regnetz_d8_imagenet.h5 |
| RegNetZD8_EVO | 23.46M | 4.61G | 256 | 83.42 | regnetz_d8_evo_imagenet.h5 |
| RegNetZE8 | 57.70M | 9.88G | 256 | 84.5 | regnetz_e8_imagenet.h5 |
- Keras ResMLP includes implementation of PDF 2105.03404 ResMLP: Feedforward networks for image classification with data-efficient training.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| ResMLP12 | 15M | 3.02G | 224 | 77.8 | resmlp12_imagenet.h5 |
| ResMLP24 | 30M | 5.98G | 224 | 80.8 | resmlp24_imagenet.h5 |
| ResMLP36 | 116M | 8.94G | 224 | 81.1 | resmlp36_imagenet.h5 |
| ResMLP_B24 | 129M | 100.39G | 224 | 83.6 | resmlp_b24_imagenet.h5 |
| - imagenet22k | 129M | 100.39G | 224 | 84.4 | resmlp_b24_imagenet22k.h5 |
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| resnest50 | 28M | 5.38G | 224 | 81.03 | resnest50.h5 |
| resnest101 | 49M | 13.33G | 256 | 82.83 | resnest101.h5 |
| resnest200 | 71M | 35.55G | 320 | 83.84 | resnest200.h5 |
| resnest269 | 111M | 77.42G | 416 | 84.54 | resnest269.h5 |
- Keras ResNetD includes implementation of PDF 1812.01187 Bag of Tricks for Image Classification with Convolutional Neural Networks
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| ResNet50D | 25.58M | 4.33G | 224 | 80.530 | resnet50d.h5 |
| ResNet101D | 44.57M | 8.04G | 224 | 83.022 | resnet101d.h5 |
| ResNet152D | 60.21M | 11.75G | 224 | 83.680 | resnet152d.h5 |
| ResNet200D | 64.69M | 15.25G | 224 | 83.962 | resnet200d.h5 |
- Keras ResNetQ includes implementation of Github timm/models/resnet.py
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| ResNet51Q | 35.7M | 4.87G | 224 | 82.36 | resnet51q.h5 |
| ResNet61Q | 36.8M | 5.96G | 224 |
- Keras ResNeXt includes implementation of PDF 1611.05431 Aggregated Residual Transformations for Deep Neural Networks.
SWSLmeansSemi-Weakly Supervised ResNe*tfrom Github facebookresearch/semi-supervised-ImageNet1K-models. Please note the CC-BY-NC 4.0 license on theses weights, non-commercial use only.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| ResNeXt50 (32x4d) | 25M | 4.23G | 224 | 79.768 | resnext50_imagenet.h5 |
| - SWSL | 25M | 4.23G | 224 | 82.182 | resnext50_swsl.h5 |
| ResNeXt50D (32x4d + deep) | 25M | 4.47G | 224 | 79.676 | resnext50d_imagenet.h5 |
| ResNeXt101 (32x4d) | 42M | 7.97G | 224 | 80.334 | resnext101_imagenet.h5 |
| - SWSL | 42M | 7.97G | 224 | 83.230 | resnext101_swsl.h5 |
| ResNeXt101W (32x8d) | 89M | 16.41G | 224 | 79.308 | resnext101_imagenet.h5 |
| - SWSL | 89M | 16.41G | 224 | 84.284 | resnext101w_swsl.h5 |
| ResNeXt101W_64 (64x4d) | 83.46M | 15.46G | 224 | 82.46 | resnext101w_64_imagenet.h5 |
- Keras SwinTransformerV2 includes implementation of PDF 2111.09883 Swin Transformer V2: Scaling Up Capacity and Resolution.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| SwinTransformerV2Tiny_ns | 28.3M | 4.69G | 224 | 81.8 | tiny_ns_224_imagenet.h5 |
| SwinTransformerV2Small_ns | 49.7M | 9.12G | 224 | 83.5 | small_ns_224_imagenet.h5 |
| SwinTransformerV2Tiny_window8 | 28.3M | 5.99G | 256 | 81.8 | tiny_window8_256.h5 |
| SwinTransformerV2Tiny_window16 | 28.3M | 6.75G | 256 | 82.8 | tiny_window16_256.h5 |
| SwinTransformerV2Small_window8 | 49.7M | 11.63G | 256 | 83.7 | small_window8_256.h5 |
| SwinTransformerV2Small_window16 | 49.7M | 12.93G | 256 | 84.1 | small_window16_256.h5 |
| SwinTransformerV2Base_window8 | 87.9M | 20.44G | 256 | 84.2 | base_window8_256.h5 |
| SwinTransformerV2Base_window16 | 87.9M | 22.17G | 256 | 84.6 | base_window16_256.h5 |
| SwinTransformerV2Base_window16, 22k | 87.9M | 22.17G | 256 | 86.2 | base_window16_256_22k.h5 |
| SwinTransformerV2Base_window24, 22k | 87.9M | 55.89G | 384 | 87.1 | base_window24_384_22k.h5 |
| SwinTransformerV2Large_window16, 22k | 196.7M | 48.03G | 256 | 86.9 | large_window16_256_22k.h5 |
| SwinTransformerV2Large_window24, 22k | 196.7M | 117.1G | 384 | 87.6 | large_window24_384_22k.h5 |
- Keras TinyNet includes implementation of PDF 2010.14819 Model Rubik’s Cube: Twisting Resolution, Depth and Width for TinyNets.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| TinyNetE | 2.04M | 25.22M | 106 | 59.86 | tinynet_e_imagenet.h5 |
| TinyNetD | 2.34M | 53.35M | 152 | 66.96 | tinynet_d_imagenet.h5 |
| TinyNetC | 2.46M | 103.22M | 184 | 71.23 | tinynet_c_imagenet.h5 |
| TinyNetB | 3.73M | 206.28M | 188 | 74.98 | tinynet_b_imagenet.h5 |
| TinyNetA | 6.19M | 343.74M | 192 | 77.65 | tinynet_a_imagenet.h5 |
- Keras UniFormer includes implementation of PDF 2201.09450 UniFormer: Unifying Convolution and Self-attention for Visual Recognition.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| UniformerSmall32 + TL | 22M | 3.66G | 224 | 83.4 | small_32_224_token_label |
| UniformerSmall64 | 22M | 3.66G | 224 | 82.9 | small_64_imagenet |
| - Token Labeling | 22M | 3.66G | 224 | 83.4 | small_64_token_label |
| UniformerSmallPlus32 | 24M | 4.24G | 224 | 83.4 | small_plus_32_imagenet |
| - Token Labeling | 24M | 4.24G | 224 | 83.9 | small_plus_32_token_label |
| UniformerSmallPlus64 | 24M | 4.23G | 224 | 83.4 | small_plus_64_imagenet |
| - Token Labeling | 24M | 4.23G | 224 | 83.6 | small_plus_64_token_label |
| UniformerBase32 + TL | 50M | 8.32G | 224 | 85.1 | base_32_224_token_label |
| UniformerBase64 | 50M | 8.31G | 224 | 83.8 | base_64_imagenet |
| - Token Labeling | 50M | 8.31G | 224 | 84.8 | base_64_224_token_label |
| UniformerLarge64 + TL | 100M | 19.79G | 224 | 85.6 | large_64_224_token_label |
| UniformerLarge64 + TL | 100M | 63.11G | 384 | 86.3 | large_64_384_token_label |
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| VOLO_d1 | 27M | 4.82G | 224 | 84.2 | volo_d1_224_imagenet.h5 |
| - 384 | 27M | 14.22G | 384 | 85.2 | volo_d1_384_imagenet.h5 |
| VOLO_d2 | 59M | 9.78G | 224 | 85.2 | volo_d2_224_imagenet.h5 |
| - 384 | 59M | 28.84G | 384 | 86.0 | volo_d2_384_imagenet.h5 |
| VOLO_d3 | 86M | 13.80G | 224 | 85.4 | volo_d3_224_imagenet.h5 |
| - 448 | 86M | 55.50G | 448 | 86.3 | volo_d3_448_imagenet.h5 |
| VOLO_d4 | 193M | 29.39G | 224 | 85.7 | volo_d4_224_imagenet.h5 |
| - 448 | 193M | 117.81G | 448 | 86.8 | volo_d4_448_imagenet.h5 |
| VOLO_d5 | 296M | 53.34G | 224 | 86.1 | volo_d5_224_imagenet.h5 |
| - 448 | 296M | 213.72G | 448 | 87.0 | volo_d5_448_imagenet.h5 |
| - 512 | 296M | 279.36G | 512 | 87.1 | volo_d5_512_imagenet.h5 |
- Keras WaveMLP includes implementation of PDF 2111.12294 An Image Patch is a Wave: Quantum Inspired Vision MLP.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| WaveMLP_T | 17M | 2.47G | 224 | 80.9 | wavemlp_t_imagenet.h5 |
| WaveMLP_S | 30M | 4.55G | 224 | 82.9 | wavemlp_s_imagenet.h5 |
| WaveMLP_M | 44M | 7.92G | 224 | 83.3 | wavemlp_m_imagenet.h5 |
| WaveMLP_B | 63M | 10.26G | 224 | 83.6 |
- Keras EfficientDet includes implementation of Paper 1911.09070 EfficientDet: Scalable and Efficient Object Detection.
Det-AdvProp + AutoAugmentPaper 2103.13886 Robust and Accurate Object Detection via Adversarial Learning.
| Model | Params | FLOPs | Input | COCO val AP | test AP | Download |
|---|---|---|---|---|---|---|
| EfficientDetD0 | 3.9M | 2.55G | 512 | 34.3 | 34.6 | efficientdet_d0.h5 |
| - Det-AdvProp | 3.9M | 2.55G | 512 | 35.1 | 35.3 | |
| EfficientDetD1 | 6.6M | 6.13G | 640 | 40.2 | 40.5 | efficientdet_d1.h5 |
| - Det-AdvProp | 6.6M | 6.13G | 640 | 40.8 | 40.9 | |
| EfficientDetD2 | 8.1M | 11.03G | 768 | 43.5 | 43.9 | efficientdet_d2.h5 |
| - Det-AdvProp | 8.1M | 11.03G | 768 | 44.3 | 44.3 | |
| EfficientDetD3 | 12.0M | 24.95G | 896 | 46.8 | 47.2 | efficientdet_d3.h5 |
| - Det-AdvProp | 12.0M | 24.95G | 896 | 47.7 | 48.0 | |
| EfficientDetD4 | 20.7M | 55.29G | 1024 | 49.3 | 49.7 | efficientdet_d4.h5 |
| - Det-AdvProp | 20.7M | 55.29G | 1024 | 50.4 | 50.4 | |
| EfficientDetD5 | 33.7M | 135.62G | 1280 | 51.2 | 51.5 | efficientdet_d5.h5 |
| - Det-AdvProp | 33.7M | 135.62G | 1280 | 52.2 | 52.5 | |
| EfficientDetD6 | 51.9M | 225.93G | 1280 | 52.1 | 52.6 | efficientdet_d6.h5 |
| EfficientDetD7 | 51.9M | 325.34G | 1536 | 53.4 | 53.7 | efficientdet_d7.h5 |
| EfficientDetD7X | 77.0M | 410.87G | 1536 | 54.4 | 55.1 | efficientdet_d7x.h5 |
| EfficientDetLite0 | 3.2M | 0.98G | 320 | 27.5 | 26.41 | efficientdet_lite0.h5 |
| EfficientDetLite1 | 4.2M | 1.97G | 384 | 32.6 | 31.50 | efficientdet_lite1.h5 |
| EfficientDetLite2 | 5.3M | 3.38G | 448 | 36.2 | 35.06 | efficientdet_lite2.h5 |
| EfficientDetLite3 | 8.4M | 7.50G | 512 | 39.9 | 38.77 | efficientdet_lite3.h5 |
| EfficientDetLite3X | 9.3M | 14.01G | 640 | 44.0 | 42.64 | efficientdet_lite3x.h5 |
| EfficientDetLite4 | 15.1M | 20.20G | 640 | 44.4 | 43.18 | efficientdet_lite4.h5 |
- Keras YOLOR includes implementation of Paper 2105.04206 You Only Learn One Representation: Unified Network for Multiple Tasks.
| Model | Params | FLOPs | Input | COCO val AP | test AP | Download |
|---|---|---|---|---|---|---|
| YOLOR_CSP | 52.9M | 60.25G | 640 | 50.0 | 52.8 | yolor_csp_coco.h5 |
| YOLOR_CSPX | 99.8M | 111.11G | 640 | 51.5 | 54.8 | yolor_csp_x_coco.h5 |
| YOLOR_P6 | 37.3M | 162.87G | 1280 | 52.5 | 55.7 | yolor_p6_coco.h5 |
| YOLOR_W6 | 79.9M | 226.67G | 1280 | 53.6 ? | 56.9 | yolor_w6_coco.h5 |
| YOLOR_E6 | 115.9M | 341.62G | 1280 | 50.3 ? | 57.6 | yolor_e6_coco.h5 |
| YOLOR_D6 | 151.8M | 467.88G | 1280 | 50.8 ? | 58.2 | yolor_d6_coco.h5 |
- Keras YOLOX includes implementation of Paper 2107.08430 YOLOX: Exceeding YOLO Series in 2021.
| Model | Params | FLOPs | Input | COCO val AP | test AP | Download |
|---|---|---|---|---|---|---|
| YOLOXNano | 0.91M | 0.53G | 416 | 25.8 | yolox_nano_coco.h5 | |
| YOLOXTiny | 5.06M | 3.22G | 416 | 32.8 | yolox_tiny_coco.h5 | |
| YOLOXS | 9.0M | 13.39G | 640 | 40.5 | 40.5 | yolox_s_coco.h5 |
| YOLOXM | 25.3M | 36.84G | 640 | 46.9 | 47.2 | yolox_m_coco.h5 |
| YOLOXL | 54.2M | 77.76G | 640 | 49.7 | 50.1 | yolox_l_coco.h5 |
| YOLOXX | 99.1M | 140.87G | 640 | 51.5 | 51.5 | yolox_x_coco.h5 |
- Github faustomorales/vit-keras
- Github rishigami/Swin-Transformer-TF
- Github tensorflow/resnet_rs
- Github google-research/big_transfer
- perceiver_image_classification
- This part is copied and modified according to Github rwightman/pytorch-image-models.
- Code. The code here is licensed MIT. It is your responsibility to ensure you comply with licenses here and conditions of any dependent licenses. Where applicable, I've linked the sources/references for various components in docstrings. If you think I've missed anything please create an issue. So far all of the pretrained weights available here are pretrained on ImageNet and COCO with a select few that have some additional pretraining.
- ImageNet Pretrained Weights. ImageNet was released for non-commercial research purposes only (https://image-net.org/download). It's not clear what the implications of that are for the use of pretrained weights from that dataset. Any models I have trained with ImageNet are done for research purposes and one should assume that the original dataset license applies to the weights. It's best to seek legal advice if you intend to use the pretrained weights in a commercial product.
- COCO Pretrained Weights. Should follow cocodataset termsofuse. The annotations in COCO dataset belong to the COCO Consortium and are licensed under a Creative Commons Attribution 4.0 License. The COCO Consortium does not own the copyright of the images. Use of the images must abide by the Flickr Terms of Use. The users of the images accept full responsibility for the use of the dataset, including but not limited to the use of any copies of copyrighted images that they may create from the dataset.
- Pretrained on more than ImageNet and COCO. Several weights included or references here were pretrained with proprietary datasets that I do not have access to. These include the Facebook WSL, SSL, SWSL ResNe(Xt) and the Google Noisy Student EfficientNet models. The Facebook models have an explicit non-commercial license (CC-BY-NC 4.0, https://github.com/facebookresearch/semi-supervised-ImageNet1K-models, https://github.com/facebookresearch/WSL-Images). The Google models do not appear to have any restriction beyond the Apache 2.0 license (and ImageNet concerns). In either case, you should contact Facebook or Google with any questions.
- BibTeX
@misc{leondgarse, author = {Leondgarse}, title = {Keras CV Attention Models}, year = {2022}, publisher = {GitHub}, journal = {GitHub repository}, doi = {10.5281/zenodo.6506947}, howpublished = {\url{https://github.com/leondgarse/keras_cv_attention_models}} }
- Latest DOI: