- Introduction
- Characteristics of fast_map function
- Usage
- Installation
- Performance comparison (against multithreading/multiprocessing on their own)
- Troubleshooting and issues
- Considerations
What is a map?
map is a python function which allows to repetitively execute the same function without the need to use loops. It executes each task sequentially, meaning that it doesn't start executing a new task before completing the previous one.
This library allows to execute multiple tasks in parallel using multiple processor cores, and multiple threads to maximise performance when the function is blocking (e.g. it's delayed by time.sleep()).
It provides fast_map function and the non-blocking fast_map_async equivalent (having the same performance, but allowing to continue execution and receive results in callbacks).
Let's take a look at the following function:
def f(x):
time.sleep(1)Using map(f, range(60)) would take a minute to complete, whereas fast_map(f, range(60)) would complete in around 1 second. Note that both of these functions return a generator.
- provides parallelism and concurrency for blocking functions
- returns a generator (meaning that individual returned values are returned immediately after being computed, before the whole collection is returned as a whole)
- return is ordered (accordingly to supplied arguments), however the execution order of tasks isn't guaranteed* and will most likely differ
- evenly distributes tasks within processes
- uses the number of threads equal to the number of supplied tasks (unless threads_limit argument is provided)
- uses the number of processes equal to the number of CPU cores unless the number of tasks (or supplied
threads_limit/procs_limit) is smaller than it (e.g. to avoid creating multiple processes for a single task) threads_limitandprocs_limitarguments are optional (settingthreads_limitis strongly encouraged,procs_limitis only useful when want the number of created processes to be less than the number of CPU cores and the number of tasks/threads)
Tasks are passed to separate processes in their original order (attempting to produce ordered returns as fast as possible. However, tasks are executed in parallel, and there is no mechanism implemented in this library to ensure their start/end point will be ordered/synchronized, only their returned values are ordered.
What does it mean?
The code below will print numbers in the wrong order.
def f(x):
print(x)
for i in fast_map(f, range(60)):
passThe code below will print numbers in the correct order.
def f(x):
return x
for i in fast_map(f, range(60)):
print(i)fast_map (see fast_map_usage.py for a more elaborated demonstration.
from fast_map import fast_map
import time
def io_and_cpu_expensive_function(x):
time.sleep(1)
for i in range(10 ** 6):
pass
return x*x
for i in fast_map(io_and_cpu_expensive_function, range(8), threads_limit=100, procs_limit=10):
print(i)Note that "threads_limit" has no effect here because only 8 threads are created anyway (1 for each task). It would make a difference if we used "range(101)". In such case we would have to wait additional second before the last (or few remaining) result was yielded/returned.
The procs_limit only takes effect if it's lower than the number of CPU cores and lower than the number of tasks to execute.
fast_map_async (see fast_map_async_usage.py for a more elaborated demonstration)
from fast_map import fast_map_async
import time
def io_and_cpu_expensive_function(x):
time.sleep(1)
for i in range(10 ** 6):
pass
return x*x
def on_result(result):
print(result)
def on_done():
print('all done')
# returns a thread
t = fast_map_async(
io_and_cpu_expensive_function,
range(8),
on_result = on_result,
on_done = on_done,
threads_limit = 100,
procs_limit = 4
)
t.join()Again, "threads_limit" has no effect here.
python3 -m pip install fast_map
I compared it against using muliprocessing/multithreading on their own. test_fast_map.py is the script I used. It was tested with:
Python3.7
Ubuntu 18.04.6
Intel i5-3320M (4 cores)
8GB DDR3 memory
Results show that for IO+CPU expensive tasks fast_map performs better than multithreading-only and multiprocessing-only approaches. For strictly CPU expensive tasks it performs better than multithreading-only but slightly worse than multiprocessing-only approach.
In both cases, IO+CPU and strictly CPU expensive tasks, it performs better than the standard map.
Standard map is not shown because it would take minutes (as it executes tasks sequentially).
"-1" result means that ProcessPoolExecutor failed due to "too many files open" (which on my system happens when around 1000 processes are created by the python script). It shows why creating large number of processes to achieve concurrency may be a bad idea. A better idea would be to either:
- rely on multi-threading itself (which unfortunately utilizes only a single cpu-core)
- use asyncio (assumming that the blocking code can be turned into coroutines), possibly combined with multiprocessing as shown in asyncioeval
- combine multiprocessing with multi-threading just like fast_map does

The following blocking function was used to produce the graph above:
def io_and_cpu_expensive_blocking_function(x):
time.sleep(1)
for i in range(10 ** 6):
pass
return xIt can be noticed that using larger number of threads tends to compute results faster even in CPU expensive tasks, however I would risk a statement that using such large number of threads (e.g. 1 per each task) for a stricly CPU expensive tasks may bring negligible speed improvement of the fast_map but may possibly slow down the whole system. Because python processes may "fight" with other process over CPU time (that's just my hypothesis).
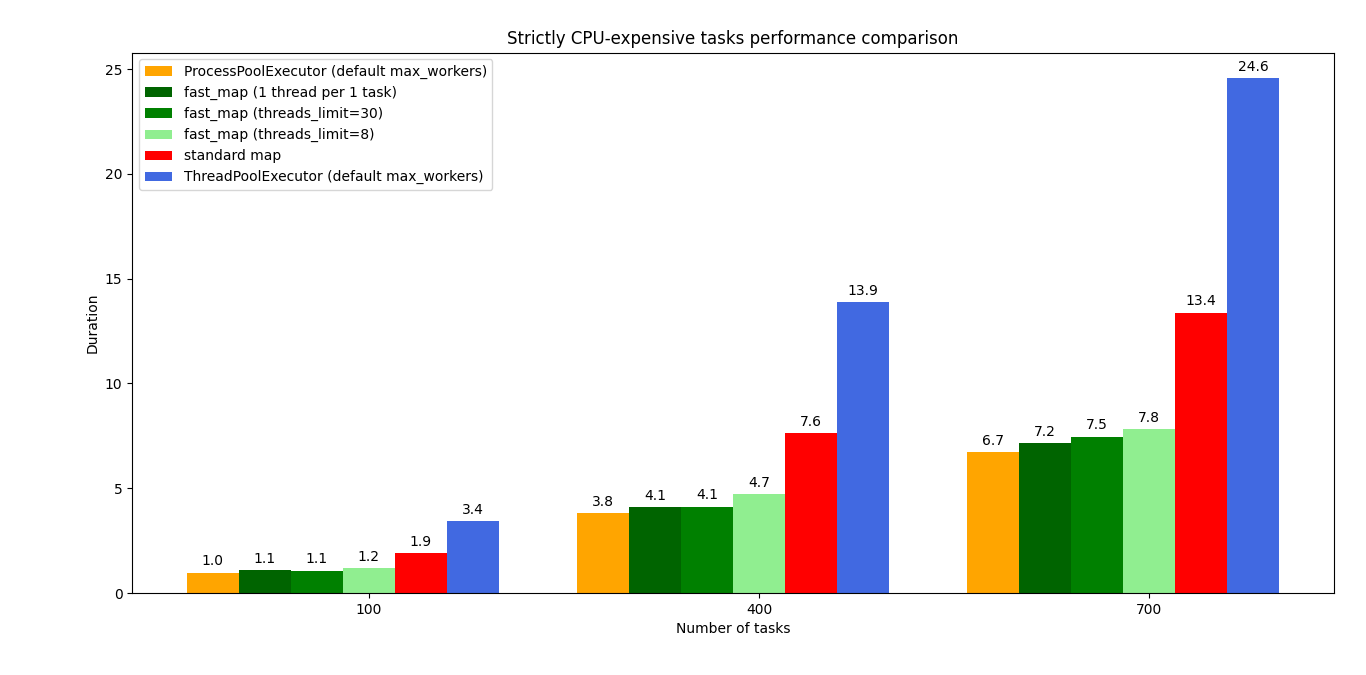
The following blocking function was used to produce the graph above:
def cpu_expensive_blocking_function(x):
for i in range(10 ** 6):
pass
return xIt isn't suitable to be used in multi-processing scripts unless you know what you're doing (it was problematic when I tried to use it in such scripts).
Calling fast_map from different threads or calling fast_map_async in a loop may lead to creating too many processes or threads (use threads_limit and procs_limit arguments to avoid issues in such case).
Accessing thread-safe objects (created externally, and using locks under the hood) within the function supplied to fast_map will probably result in a deadlock.
By default the fast_map threads_limit parameter is None, meaning that a separate thread is spawned for each of supplied tasks (attempting to provide full concurrency). It is strongly encouraged to set threads_limit to some reasonable value for 2 reasons:
- large number of threads will slow down the CPU-expensive part of the blocking function
- fast_map will result in unhandled exception when too many threads try to be created (on my system it's around few thousands)
(btw if threads_limit is higher than the number of supplied tasks, then the number of created threads equals the number of supplied tasks, so threads_limit doesn't force the number of created threads, it only limits them)
fast_map uses multiprocessing module and its default process start method (which I believe is fork on Unix). It spawns the number of processes equal to the number of CPU cores. For each spawned process it uses a separate task supplying multiprocessing.Queue (each has its own for the sake of even task distribution). It uses a singl common results queue for collecting results. It uses concurrent.futures.ThreadPoolExecutor to implement multi-threading. It uses a single threading.Thread to enqueue all the tasks (this allows to start computation on multiple processes without the need to enqueue all the tasks first).
It was inspired by a similar project which combined multiprocessing with asyncio:
asyncioeval by Nicholas Basker
Multithreading in Python uses a single core on multi-core processors. Multiprocessing isn't well suited to provide concurrency for large number of tasks (on my laptop it fails at around 1000 forked processes). Both of these combined appear to work well with functions expensive in terms or CPU work (e.g. for i in range(10**6)) and IO waiting time (e.g. time.sleep(1)).
I think asyncio is a good choice over multi-threading when we can modify a blocking function into an awaitable coroutine. If we want/must use a blocking function (e.g. we can't modify it into asyncio coroutine because it's from some library we can't modify) and we want to make it concurrent, asyncio provides loop.run_in_executor which relies on multi-threading anyway.