Code for Large Scale Hierarchical Text Classification competition.
a centroid-based flat classifier.
- Selecting k-class from near the query with nearest centroid classifier.
- Judging with binary classifier whether the query can be accepted to class.
(predict.cpp)
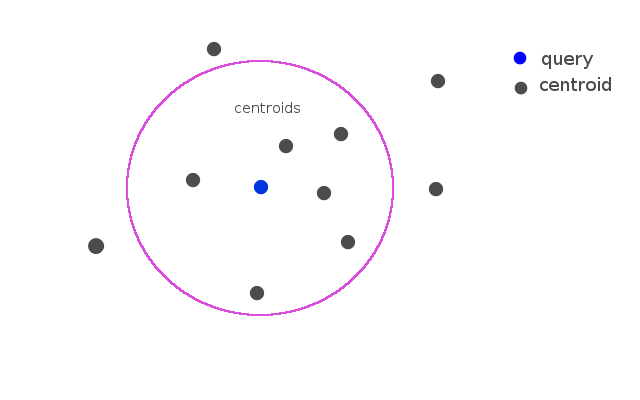
Selecting k-candidate classes that centroid of class close to the query.
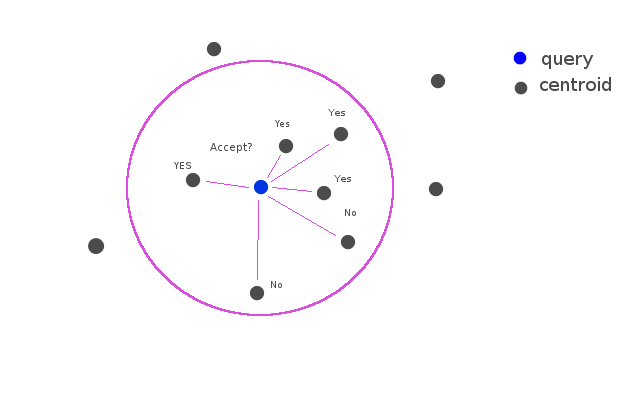
Selecting classes that binary classifier of class returns p > 0.5. (Implementation of the binary classifier is logistic regression)
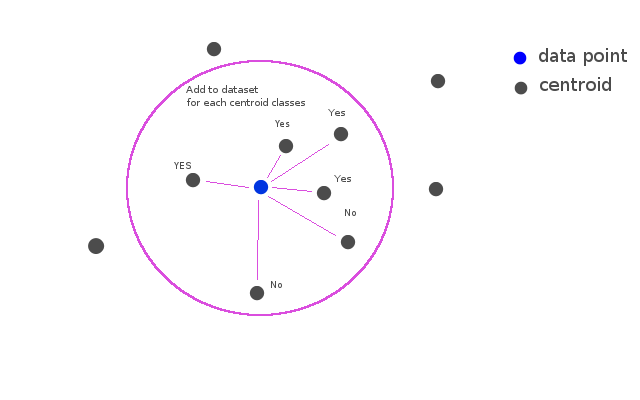
For each data points..
- Selecting k-class from near the data point with nearest centroid classifier.
- Adding the data point as training data to dataset for each classes.
(prefetch.cpp)
For each classes..
- Learning the binary classifier using own dataset.
(train.cpp)
using variant TF-IDF.
tf = log(number_of_term_occurs_in_document + 1)
idf = log(total_number_of_documents / (number_of_documents_containing_term + 1)) + 5
tfidf = tf * idf
and feature vector is normalized by L2 norm. (code: tfidf_transformer.hpp)
using cosine similarity.
- Ubuntu 13.10
- g++ 4.8.1
- make
- 32GB RAM
please edit SETTINGS.h first.
make
./prefetch
./train
./predict
NOTE: ./prefetch is very slow. probably processing time exceeds 15 hours.
./vt_prefech
./vt_train
./validation
running the validation test.
./vt_knn
generating the sumission.txt.
./knn
running the validation test.
./vt_ncc
generating the sumission.txt.
./ncc
| Model | LBMaF | Training Time | Prediction Time |
|---|---|---|---|
| k-NN | 0.23088 | n/a | 10 minutes |
| NCC | 0.28931 | 80 seconds | 2 hours |
| NCC+BC | 0.33025 | 15 hours | 2 hours |