-
Notifications
You must be signed in to change notification settings - Fork 840
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
* fix dependencies install in whisper notebook * add depth anything notebook * code style * fix readme * table of content * move notebooks
- Loading branch information
Showing
5 changed files
with
907 additions
and
1 deletion.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Large diffs are not rendered by default.
Oops, something went wrong.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,32 @@ | ||
| # Depth estimation with DepthAnything and OpenVINO | ||
|
|
||
| [](https://mybinder.org/v2/gh/openvinotoolkit/openvino_notebooks/HEAD?filepath=notebooks%2F281-depth-anythingh%2F281-depth-anything.ipynb) | ||
| [](https://colab.research.google.com/github/openvinotoolkit/openvino_notebooks/blob/main/notebooks/281-depth-anything/281-depth-anything.ipynb) | ||
|
|
||
|  | ||
|
|
||
| [Depth Anything](https://depth-anything.github.io/) is a highly practical solution for robust monocular depth estimation. Without pursuing novel technical modules, this project aims to build a simple yet powerful foundation model dealing with any images under any circumstances. | ||
| The framework of Depth Anything is shown below. it adopts a standard pipeline to unleashing the power of large-scale unlabeled images. | ||
| 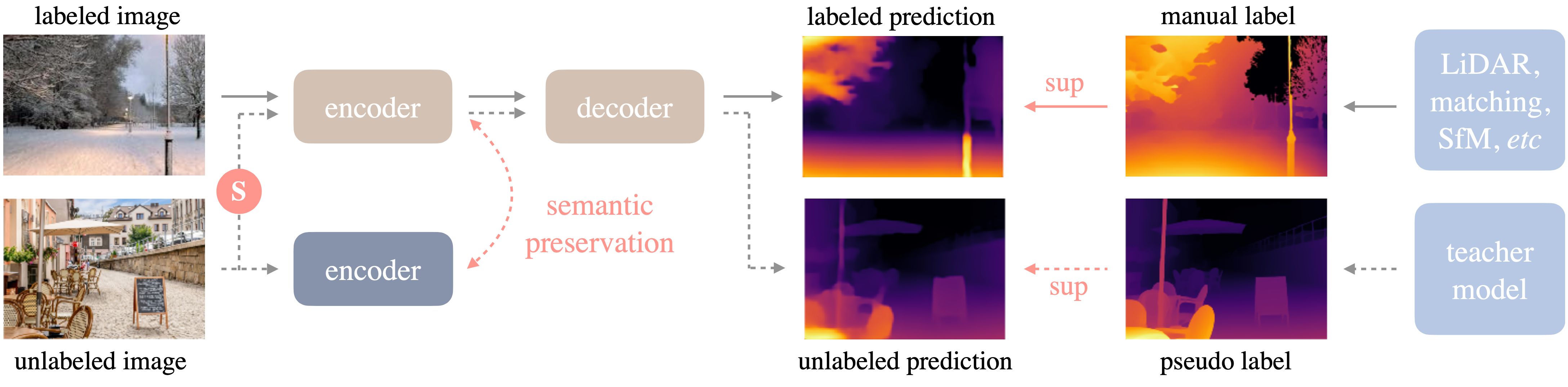 | ||
|
|
||
| More details about model can be found in [project web page](https://depth-anything.github.io/), [paper](https://arxiv.org/abs/2401.10891), and official [repository](https://github.com/LiheYoung/Depth-Anything) | ||
|
|
||
| In this tutorial we will explore how to convert and run DepthAnything using OpenVINO. | ||
|
|
||
| ## Notebook Contents | ||
|
|
||
| This notebook demonstrates Monocular Depth Estimation with the [DepthAnything](https://github.com/LiheYoung/Depth-Anything) in OpenVINO. | ||
|
|
||
| The tutorial consists of following steps: | ||
| - Install prerequisites | ||
| - Load and run PyTorch model inference | ||
| - Convert Model to Openvino Intermediate Representation format | ||
| - Run OpenVINO model inference on single image | ||
| - Run OpenVINO model inference on video | ||
| - Launch interactive demo | ||
|
|
||
| ## Installation Instructions | ||
|
|
||
| This is a self-contained example that relies solely on its own code.</br> | ||
| We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. | ||
| For details, please refer to [Installation Guide](../../README.md). |