




{kind=link}
Platon: identification and characterization of bacterial plasmid contigs from short-read draft assemblies
TL;DR Platon detects plasmid-borne contigs within bacterial draft (meta) genomes assemblies. Therefore, Platon analyzes the distribution bias of protein-coding gene families among chromosomes and plasmids. This analysis is complemented by comprehensive contig characterizations followed by heuristic filters.
Platon conducts three analysis steps:
- It predicts and searches protein sequences against a custom and pre-computed database comprising marker protein sequences (MPS) and related replicon distribution scores (RDS). These scores express the empirically measured bias of protein sequence family distributions among plasmids and chromosomes pre-computed on complete NCBI RefSeq replicons. Platon calculates the mean RDS for each contig and either classifies them as chromosome if the RDS is below a sensitivity cutoff determined to 95% sensitivity or as plasmid if the RDS is above a specificity cutoff determined to 99.9% specificity. Exact values for these thresholds have been computed based on Monte Carlo simulations of artifical replicon fragments created from complete RefSeq chromosome and plasmid sequences.
- Contigs passing the sensitivity filter get comprehensivley characterized. Hereby, Platon tries to circularize the contig sequences, searches for rRNA, replication, mobilization and conjugation genes, oriT sequences, incompatibility group DNA probes and finally performs a BLAST+ search against the NCBI plasmid database.
- Finally, to increase the overall sensitivity, Platon classifies all remaining contigs based on the gathered information by several heuristics.
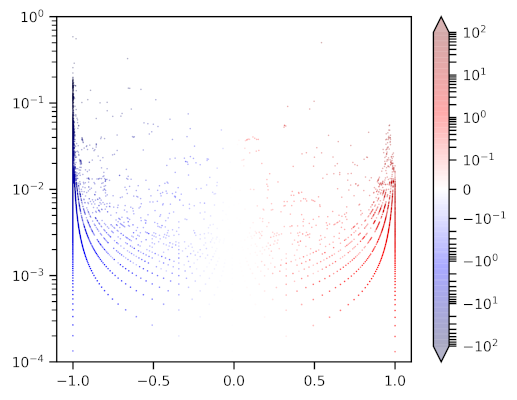 |
|---|
| Fig: Replicon distribution and alignment hit frequencies of MPS. Shown are summed plasmid and chromosome alignment hit frequencies per MPS plotted against plasmid/chromosome hit count ratios scaled to [-1 (chromosome), 1 (plasmid)]; Hue: normalized RDS values (min=-100, max=100), hit count outliers below 10-4 and above 1 are discarded for the sake of readability. |
Platon accepts draft (meta) genome assemblies in fasta format. If contigs have been assembled with SPAdes, Platon is able to extract the coverage information from the contig names.
For each contig classified as plasmid sequence the following columns are printed to STDOUT as tab separated values:
- Contig ID
- Length
- Coverage
- # ORFs
- RDS
- Circularity
- Incompatibility Type(s)
- # Replication Genes
- # Mobilization Genes
- # OriT Sequences
- # Conjugation Genes
- # rRNA Genes
- # Plasmid Database Hits
In addition, Platon writes the following files into the output directory:
<prefix>.plasmid.fasta: contigs classified as plasmids or plasmodal origin<prefix>.chromosome.fasta: contigs classified as chromosomal origin<prefix>.tsv: dense information as printed to STDOUT (see above)<prefix>.json: comprehensive results and information on each single plasmid contig. All files are prefixed (<prefix>) as the input genome fasta file.
Platon can be installed via BioConda or Pip. However, we encourage to use Conda to automatically install all required 3rd party dependencies. In all cases a mandatory database must be downloaded.
$ conda install -c conda-forge -c bioconda -c defaults platon$ python3 -m pip install --user cb-platonPlaton requires the following 3rd party executables which must be installed & executable:
- Prodigal (2.6.3) https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2848648 https://github.com/hyattpd/Prodigal
- Diamond (2.0.6) https://pubmed.ncbi.nlm.nih.gov/25402007 http://www.diamondsearch.org
- Blast+ (2.10.1) https://www.ncbi.nlm.nih.gov/pubmed/2231712 https://blast.ncbi.nlm.nih.gov
- MUMmer (4.0.0-beta2) https://www.ncbi.nlm.nih.gov/pmc/articles/PMC395750/ https://github.com/gmarcais/mummer
- HMMER (3.3.1) https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3695513/ http://hmmer.org/
- INFERNAL (1.1.4) https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3810854 http://eddylab.org/infernal
Platon requires a mandatory database which is publicly hosted at Zenodo:
Further information is provided in the database section below.
$ wget https://zenodo.org/record/4066768/files/db.tar.gz
$ tar -xzf db.tar.gz
$ rm db.tar.gzThe db path can either be provided via parameter (--db) or environment variable (PLATON_DB):
$ platon --db <db-path> genome.fasta
$ export PLATON_DB=<db-path>
$ platon genome.fastaAdditionally, for a system-wide setup, the database can be copied to the Platon base directory:
$ cp -r db/ <platon-installation-dir>Usage:
usage: platon [--db DB] [--prefix PREFIX] [--output OUTPUT] [--mode {sensitivity,accuracy,specificity}] [--characterize] [--meta] [--help] [--verbose] [--threads THREADS] [--version] <genome>
Identification and characterization of bacterial plasmid contigs from short-read draft assemblies.
Input / Output:
<genome> draft genome in fasta format
--db DB, -d DB database path (default = <platon_path>/db)
--prefix PREFIX, -p PREFIX
Prefix for output files
--output OUTPUT, -o OUTPUT
Output directory (default = current working directory)
Workflow:
--mode {sensitivity,accuracy,specificity}, -m {sensitivity,accuracy,specificity}
applied filter mode: sensitivity: RDS only (>= 95% sensitivity); specificity: RDS only (>=99.9% specificity); accuracy: RDS & characterization heuristics (highest accuracy) (default = accuracy)
--characterize, -c deactivate filters; characterize all contigs
--meta use metagenome gene prediction mode
General:
--help, -h Show this help message and exit
--verbose, -v Print verbose information
--threads THREADS, -t THREADS
Number of threads to use (default = number of available CPUs)
--version show program's version number and exitSimple:
$ platon genome.fastaExpert: writing results to results directory with verbose output using 8 threads:
$ platon --db ~/db --output results/ --verbose --threads 8 genome.fastaPlaton provides 3 different modi controlling which filters will be used.
Accuracy mode is the preset default.
In the sensitivity mode Platon will classifiy all contigs with an RDS value below the sensitivity threshold as chromosomal and all remaining contigs as plasmid. This threshold was defined to account for 95% sensitivity and computed via Monte Carlo simulations of artifical contigs resulting in an RDS=-7.9.
-> use this mode to exclude chromosomal contigs.
In the specificity mode Platon will classifiy all contigs with an RDS value above the specificity threshold as plasmid and all remaining contigs as chromosomal. This threshold was defined to account for 99.9% specificity and computed via Monte Carlo simulations of artifical contigs resulting in an RDS=0.7.
In the accuracy mode Platon will classifiy all contigs with:
- an
RDSvalue below the sensitivity threshold as chromosomal - an
RDSvalue above the specificity threshold as plasmid and in addition all contigs as plasmid for which one of the following is true: it - can be circularized
- has an incompatibility group sequence
- has a replication or mobilization HMM hit
- has an oriT hit
- has an RDS above the conservative score (0.1), a RefSeq plasmid hit and no rRNA hit
Platon depends on a custom database based on MPS, RDS, RefSeq Plasmid database, PlasmidFinder db as well as manually curated MOB HMM models from MOBscan, custom conjugation and replication HMM models and oriT sequences from MOB-suite. This database based on UniProt UniRef90 release 202 can be downloaded here: (zipped 1.6 Gb, unzipped 2.8 Gb)
https://zenodo.org/record/4066768/files/db.tar.gz
Please make sure that you use the latest Platon version along with the most recent database version! Older software versions are not compatible with the latest database version
Platon was developed and tested in Python 3.5 and depends on BioPython (>=1.71).
Additionally, it depends on the following 3rd party executables:
- Prodigal (2.6.3) https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2848648 https://github.com/hyattpd/Prodigal
- Diamond (2.0.6) https://pubmed.ncbi.nlm.nih.gov/25402007 http://www.diamondsearch.org
- Blast+ (2.10.1) https://www.ncbi.nlm.nih.gov/pubmed/2231712 https://blast.ncbi.nlm.nih.gov
- MUMmer (4.0.0-beta2) https://www.ncbi.nlm.nih.gov/pmc/articles/PMC395750/ https://github.com/gmarcais/mummer
- HMMER (3.3.1) https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3695513/ http://hmmer.org/
- INFERNAL (1.1.4) https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3810854 http://eddylab.org/infernal
Schwengers O., Barth P., Falgenhauer L., Hain T., Chakraborty T., & Goesmann A. (2020). Platon: identification and characterization of bacterial plasmid contigs in short-read draft assemblies exploiting protein sequence-based replicon distribution scores. Microbial Genomics, 95, 295. https://doi.org/10.1099/mgen.0.000398
As Platon takes advantage of the inc groups, MOB HMMs and oriT sequences of the following databases, please also cite:
-
Carattoli A., Zankari E., Garcia-Fernandez A., Voldby Larsen M., Lund O., Villa L., Aarestrup F.M., Hasman H. (2014) PlasmidFinder and pMLST: in silico detection and typing of plasmids. Antimicrobial Agents and Chemotherapy, https://doi.org/10.1128/AAC.02412-14
-
Garcillán-Barcia M. P., Redondo-Salvo S., Vielva L., de la Cruz F. (2020) MOBscan: Automated Annotation of MOB Relaxases. Methods in Molecular Biology, https://doi.org/10.1007/978-1-4939-9877-7_21
-
Robertson J., Nash J. H. E. (2018) MOB-suite: Software Tools for Clustering, Reconstruction and Typing of Plasmids From Draft Assemblies. Microbial Genomics, https://doi.org/10.1099/mgen.0.000206
If you run into any issues with Platon, we'd be happy to hear about it! Please, start the pipeline with -v (verbose) and do not hesitate to file an issue including as much of the following as possible:
- a detailed description of the issue
- the platon cmd line output
- the
<prefix>.jsonfile if possible - A reproducible example of the issue with a small dataset that you can share (helps us identify whether the issue is specific to a particular computer, operating system, and/or dataset).