Embedding
To integrate PDI transformations and jobs into your applications, embed PDI objects directly into your application code. The instructions in this section address common embedding scenarios.
You can get the accompanying sample project from the kettle-sdk-embedding-samples folder of the sample code package. The sample project is bundled with a minimal set of dependencies. In a real-world implementation, projects require the complete set of PDI dependencies from data-integration/lib, and may require plugins from data-integration/plugins. Consider the following:
All PDI dependencies must be included in the class path. This includes files located within the following PDI folders:
data-integration/libdata-integration/libswt/<os>data-integration/classes
You can point to these folders directly within the PDI installation or copy these folders into your project’s directory structure. Examples:
java -classpath "lib/*;libswt/linux/*;classes/*" MyApp.java
java -classpath "$PDI_DI_DIR/lib/*;$PDI_DI_DIR/libswt/linux/*;
$PDI_DI_DIR/classes/*" MyApp.java
In order to use default osgi features of PDI, make the PDI data-integration/system folder available to your application - this folder is required for proper karaf initialization. This can be done in the following ways:
-
Copy the
data-integration/systemfolder directly into the<working directory>/systemsfolder of your application -
Set the
pentaho.user.dirsystem property to point to the PDIdata-integrationfolder (parent of the system folder), either through a command line option (-Dpentaho.user.dir=<pdi install path>/data-integration), or directly within the code:System.setProperty( "pentaho.user.dir", new File("<pdi install path>/ data-integration") );
Furthermore, to enable osgi features of PDI that are not enabled by default, the appropriate feature (jar or kar) needs to be added to the data-integration\system\karaf\deploy folder. No application reboot is required.
Make the kettle plugins (non-osgi) available to your application. Out of the box, the kettle engine will look for plugins in these two locations (recursively):
<working directory>plugins<user.home>/.kettle/plugins
To make default kettle plugins available, do one of the following:
-
Copy the
<pdi install path>/data-integration/pluginsfolder directly into the<working directory>/pluginsfolder of your application -
Set the
KETTLE_PLUGIN_BASE_FOLDERSsystem property to point to the PDIdata-integrationfolder (parent of the plugins folder), either through a command line option (-DKETTLE_PLUGIN_BASE_FOLDERS=<pdi install path>/data-integration), or directly within the code:System.setProperty( "KETTLE_PLUGIN_BASE_FOLDERS", new File("<pdi install path>/ data-integration") );
Once the plugin location(s) are properly configured, you can place any additional custom plugins in the specified locations. You can also place custom plugins in the location(s) of your choosing, as long at these locations are registered with the appropriate implementation of PluginTypeInterface prior to initializing the kettle environment:
StepPluginType.getInstance().getPluginFolders().add( new PluginFolder(
"<path to the plugin folder>" , false, true ) );
For each embedding scenario, there is a sample class that can be executed as a stand-alone java application.
- Running Transformations
- Running Jobs
- Building Transformations Dynamically
- Building Jobs Dynamically
- Obtaining Logging Information
- Exposing a Transformation or Job as a Web Service
If you want to run a PDI transformation from Java code in a stand-alone application, take a look at this sample class, org.pentaho.di.sdk.samples.embedding.RunningTransformations. It executes the sample transformation(s) located in the etl folder. The transform can be run from the .ktr file using runTransformationFromFileSystem() or from a PDI repository using runTransfomrationFromRepository().
- Always make the first call to
KettleEnvironment.init()whenever you are working with the PDI APIs. - Prepare the transformation. The definition of a PDI transformation is represented by a
TransMetaobject. You can load this object from a.ktrfile, a PDI repository, or you can generate it dynamically. To query the declared parameters of the transformation definition uselistParameters(), or to query the assigned values usesetParameterValue(). - Execute the transformation. An executable
Transobject is derived from theTransMetaobject that is passed to the constructor. TheTransobject starts and then executes asynchronously. To ensure that all steps of theTransobject have completed, callwaitUntilFinished(). - Evaluate the transformation outcome. After the
Transobject completes, you can access the result usinggetResult(). TheResultobject can be queried for success by evaluatinggetNrErrors(). This method returns zero (0) on success and a non-zero value when there are errors. To get more information, retrieve the transformation log lines. - When the transformations have completed, it is best practice to call
KettleEnvironment.shutdown()to ensure the proper shutdown of all kettle listeners.
If you want to run a PDI job from Java code in a stand-alone application, take a look at this sample class, org.pentaho.di.sdk.samples.embedding.RunningJobs. It sets the parameters and executes the job in etl/parameterized_job.kjb. The job can be run from the .kjb file using runJobFromFileSystem() or from a repository using runJobFromRepository().
- Always make the first call to
KettleEnvironment.init()whenever you are working with the PDI APIs. - Prepare the job. The definition of a PDI job is represented by a
JobMetaobject. You can load this object from a.kjbfile, a PDI repository, or you can generate it dynamically. To query the declared parameters of the job definition uselistParameters(). To set the assigned values usesetParameterValue(). - Execute the job. An executable
Jobobject is derived from theJobMetaobject that is passed in to the constructor. TheJobobject starts, and then executes in a separate thread. To wait for the job to complete, callwaitUntilFinished(). - Evaluate the job outcome. After the
Jobcompletes, you can access the result usinggetResult(). TheResultobject can be queried for success usinggetResult(). This method returns true on success and false on failure. To get more information, retrieve the job log lines. - When the jobs have completed, it is best practice to call
KettleEnvironment.shutdown()to ensure the proper shutdown of all kettle listeners.
To enable your application to respond quickly to changing conditions, you can build transformations dynamically. The example class, org.pentaho.di.sdk.samples.embedding.GeneratingTransformations, shows you how. It generates a transformation definition and saves it to a .ktr file.
- Always make the first call to
KettleEnvironment.init()whenever you are working with the PDI APIs. - Create and configure a transformation definition object. A transformation definition is represented by a
TransMetaobject. Create this object using the default constructor. The transformation definition includes the name, the declared parameters, and the required database connections. - Populate the
TransMetaobject with steps. The data flow of a transformation is defined by steps that are connected by hops. - Create the step by instantiating its class directly and configure it using its get and set methods. Transformation steps reside in sub-packages of
org.pentaho.di.trans.steps. For example, to use the Get File Names step, create an instance oforg.pentaho.di.trans.steps.getfilenames.GetFileNamesMetaand use its get and set methods to configure it. - Obtain the step id string. Each PDI step has an id that can be retrieved from the PDI plugin registry. A simple way to retrieve the step id is to call
PluginRegistry.getInstance().getPluginId(StepPluginType.class, theStepMetaObject). - Create an instance of
org.pentaho.di.trans.step.StepMeta, passing the step id string, the name, and the configured step object to the constructor. An instance ofStepMetaencapsulates the step properties, as well as controls the placement of the step on the Spoon canvas and connections to hops. Once theStepMetaobject has been created, callsetDrawn(true)andsetLocation(x,y)to make sure the step appears correctly on the Spoon canvas. Finally, add the step to the transformation, by callingaddStep()on the transformation definition object. - Once steps have been added to the transformation definition, they need to be connected by hops. To create a hop, create an instance of
org.pentaho.di.trans.TransHopMeta, passing in the From and To steps as arguments to the constructor. Add the hop to the transformation definition by callingaddTransHop().
After all steps have been added and connected by hops, the transformation definition object can be serialized to a .ktr file by calling getXML() and opening it in Spoon for inspection. The sample class org.pentaho.di.sdk.samples.embedding.GeneratingTransformations generates this transformation.
![]()
To enable your application to respond quickly to changing conditions, you can build jobs dynamically. The example class, org.pentaho.di.sdk.samples.embedding.GeneratingJobs, shows you how. It generates a job definition and saves it to a .kjb file.
- Always make the first call to
KettleEnvironment.init()whenever you are working with the PDI APIs. - Create and configure a job definition object. A job definition is represented by a
JobMetaobject. Create this object using the default constructor. The job definition includes the name, the declared parameters, and the required database connections. - Populate the
JobMetaobject with job entries. The control flow of a job is defined by job entries that are connected by hops. - Create the job entry by instantiating its class directly and configure it using its get and set methods. The job entries reside in sub-packages of
org.pentaho.di.job.entries. For example, use the File Exists job entry, create an instance oforg.pentaho.di.job.entries.fileexists.JobEntryFileExists, and usesetFilename()to configure it. The Start job entry is implemented byorg.pentaho.di.job.entries.special.JobEntrySpecial. - Create an instance of
org.pentaho.di.job.entry.JobEntryCopyby passing the job entry created in the previous step to the constructor. An instance ofJobEntryCopyencapsulates the properties of a job entry, as well as controls the placement of the job entry on the Spoon canvas and connections to hops. Once created, callsetDrawn(true)andsetLocation(x,y)to make sure the job entry appears correctly on the Spoon canvas. Finally, add the job entry to the job by callingaddJobEntry()on the job definition object. It is possible to place the same job entry in several places on the canvas by creating multiple instances of JobEntryCopy and passing in the same job entry instance. - Once job entries have been added to the job definition, they need to be connected by hops. To create a hop, create an instance of
org.pentaho.di.job.JobHopMeta, passing in the From and To job entries as arguments to the constructor. Configure the hop consistently. Configure it as a green or red hop by callingsetConditional()andsetEvaluation(true/false). If it is an unconditional hop, callsetUnconditional(). Add the hop to the job definition by callingaddJobHop().
After all job entries have been added and connected by hops, the job definition object can be serialized to a .kjb file by calling getXML(), and opened in Spoon for inspection. The sample class org.pentaho.di.sdk.samples.embedding.GeneratingJobs generates this job.
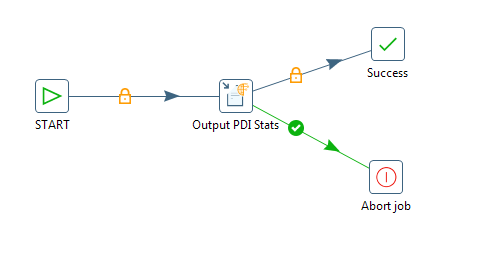
When you need more information about how transformations and jobs execute, you can view PDI log lines and text.
PDI collects log lines in a central place. The class org.pentaho.di.core.logging.KettleLogStore manages all log lines and provides methods for retrieving the log text for specific entities. To retrieve log text or log lines, supply the log channel id generated by PDI during runtime. You can obtain the log channel id by calling getLogChannelId(), which is part of LoggingObjectInterface. Jobs, transformations, job entries, and transformation steps all implement this interface.
For example, assuming the job variable is an instance of a running or completed job. This is how you retrieve its log lines:
LoggingBuffer appender = KettleLogStore.getAppender();
String logText = appender.getBuffer( job.getLogChannelId(), false ).toString();
The main methods in the sample classes org.pentaho.di.sdk.samples.embedding.RunningJobs and org.pentaho.di.sdk.samples.embedding.RunningTransformations retrieve log information from the executed job or transformation in this manner.
Running a PDI Job or Transformation as part of a web-service is implemented by writing a servlet that maps incoming parameters for a transformation or job entry and executes them as part of the request cycle.
Alternatively, you can use Carte or the Data Integration server directly by building a transformation that writes its output to the HTTP response of the Carte server. This is achieved by using the Pass Output to Servlet feature of the Text output, XML output, JSON output, or scripting steps. For an example, run the sample transformation, /data-integration/samples/transformations/Servlet Data Example.ktr, on Carte.