The MLB-YouTube dataset is a new, large-scale dataset consisting of 20 baseball games from the 2017 MLB post-season available on YouTube with over 42 hours of video footage. Our dataset consists of two components: segmented videos for activity recognition and continuous videos for activity classification. Our dataset is quite challenging as it is created from TV broadcast baseball games where multiple different activities share the camera angle. Further, the motion/appearance difference between the various activities is quite small.
Please see our paper for more details on the dataset [arXiv].
If you use our dataset or find the code useful for your research, please cite our paper:
@inproceedings{mlbyoutube2018,
title={Fine-grained Activity Recognition in Baseball Videos},
booktitle={CVPR Workshop on Computer Vision in Sports},
author={AJ Piergiovanni and Michael S. Ryoo},
year={2018}
}
Example Frames from various activities:

We densely annotated the videos with captions from the commentary given by the announcers, resulting in approximately 50 hours of matching text and video. These captions only roughly describe what is happening in the video, and often contain unrelated stories or commentary on a previous event, making this a challenging task.
Examples of the text and video:

For more details see our paper introducing the captions dataset [arXiv].
@article{mlbcaptions2018
title={Learning Shared Multimodal Embeddings with Unpaired Data},
author={AJ Piergiovanni and Michael S. Ryoo},
journal={arXiv preprint arXiv:1806.08251},
year={2018}
}
Our segmented video dataset consists of 4,290 video clips. Each clip is annotated with the various baseball activities that occur, such as swing, hit, ball, strike, foul, etc. A video clip can contain multiple activities, so we treat this as a multi-label classification task. A full list of the activities and the number of examples of each is shown in the table below.
| Activity | # Examples |
|---|---|
| No Activity | 2983 |
| Ball | 1434 |
| Strike | 1799 |
| Swing | 2506 |
| Hit | 1391 |
| Foul | 718 |
| In Play | 679 |
| Bunt | 24 |
| Hit by Pitch | 14 |
We additionally annotated each clip containing a pitch with the pitch type (e.g., fastball, curveball, slider, etc.) and the speed of the pitch. We also collected a set of 2,983 hard negative examples where no action occurs. These examples include views of the crowd, the field, or the players standing before or after a pitch occurred. Examples of the activities and hard negatives are shown below:



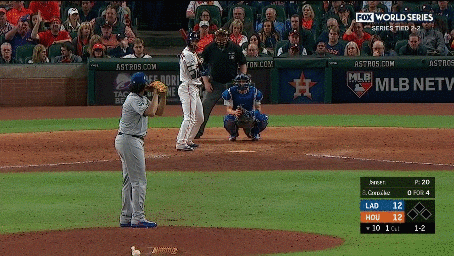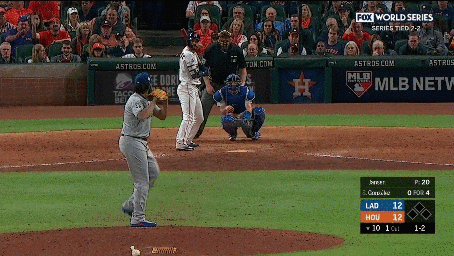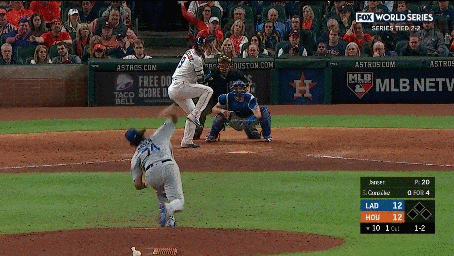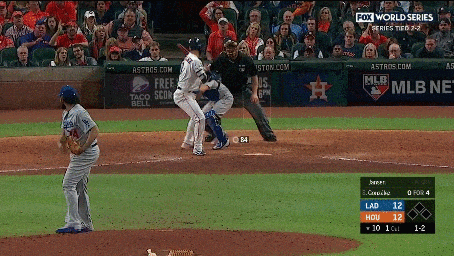

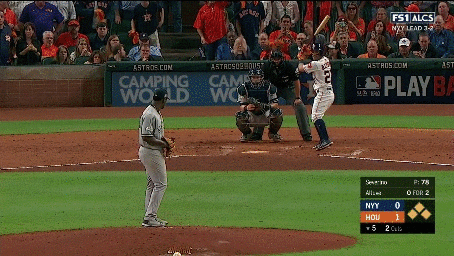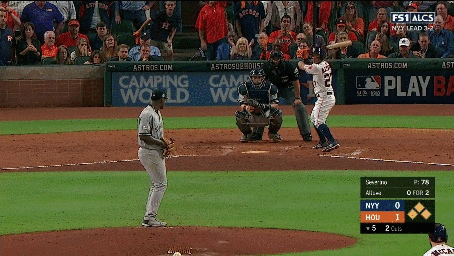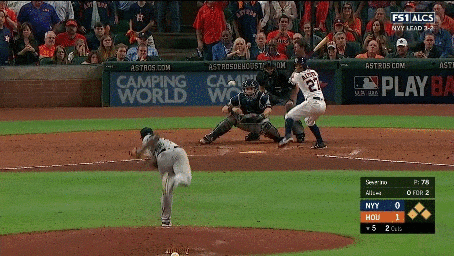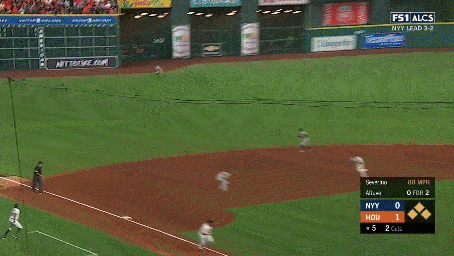









Our continuous video dataset consists of 2,128 1-2 minute long clips from the videos. We densely annotate each frame of the clip with the baseball activities that occur. Each continuous clip contains on average of 7.2 activities, resulting in a total of over 15,000 activity instances. We evaluate models using per-frame mean average precision (mAP).
- Download the youtube videos. Run
python download_videos.pywhich relies on youtube-dl. Change thesave_dirin the script to where you want the full videos saved. - To extract the segmented video clips, run
python extract_segmented_videos.pyand changeinput_directoryto be the directory containing the full videos andoutput_directoryto be the location to save the extracted clips. - To extract the continuous video clips, run
python extract_continuous_videos.pyand changeinput_directoryto be the directory containing the full videos andoutput_directoryto be the location to save the extracted clips.
We compared many approaches using I3D [1] and InceptionV3 [2] as feature extractors.
Please see our paper for more experimental details and results.
Results from multi-label video classification:
| Method | mAP (%) |
|---|---|
| Random | 16.3 |
| I3D + max-pool | 57.2 |
| I3D + pyramid pooling | 58.7 |
| I3D + LSTM | 53.1 |
| I3D + temporal conv | 58.4 |
| I3D + sub-events [3] | 61.3 |
| IncetpitonV3 + max-pool | 54.4 |
| InceptionV3 + pyramid pooling | 55.3 |
| InceptionV3 + LSTM | 57.7 |
| InceptionV3 + temporal conv | 56.1 |
| InceptionV3 + sub-events [3] | 62.6 |
Pitch Speed Regression:
| Method | RMSE |
|---|---|
| I3D | 4.3 mph |
| I3D + LSTM | 4.1 mph |
| I3D + sub-events [3] | 3.9 mph |
| IncetpitonV3 | 5.3 mph |
| IncetpitonV3 + LSTM | 4.5 mph |
| IncetpitonV3 + sub-events [3] | 3.6 mph |
| Method | mAP (%) |
|---|---|
| Random | 13.4 |
| IncetpitonV3 | 31.9 |
| IncetpitonV3 + max-pool | 35.2 |
| InceptionV3 + pyramid pooling | 36.8 |
| InceptionV3 + LSTM | 34.1 |
| InceptionV3 + temporal conv | 33.4 |
| InceptionV3 + sub-events [3] | 37.3 |
| InceptionV3 + super-events [4] | 39.6 |
| InceptionV3 + sub+super-events | 40.9 |
| InceptionV3 + TGM [5] | 37.4 |
| InceptionV3 + 3 TGM [5] | 38.2 |
| InceptionV3 + super-event [4] + 3 TGM [5] | 42.9 |
| I3D | 34.2 |
| I3D + max-pool | 36.8 |
| I3D + pyramid pooling | 39.7 |
| I3D + LSTM | 39.4 |
| I3D + temporal conv | 39.2 |
| I3D + sub-events [3] | 38.5 |
| I3D + super-events [4] | 39.1 |
| I3D + sub+super-events | 40.4 |
| I3D + TGM [5] | 38.5 |
| I3D + 3 TGM [5] | 40.1 |
| I3D + super-event [4] + 3 TGM [5] | 47.1 |
We provide our code to train and evalute the models in the experiments directory. We have the various models implemented in models.py, a script to load the dataset, and a script to train the models as well.
We also include our PyTorch implementation of I3D, see pytorch-i3d for more details.
- youtube-dl to download the videos
- tested with ffmpeg 2.8.11 to extract clips
- PyTorch (tested with version 0.3.1)
[1] J. Carreira and A. Zisserman. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. [arxiv] [code]
[2] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition (CVPR), 2016
[3] A. Piergiovanni, C. Fan, and M. S. Ryoo. Learning latent sub-events in activity videos using temporal attention filters. In Proceedings of the American Association for Artificial Intelligence (AAAI), 2017 [arxiv] [code]
[4] A. Piergiovanni and M. S. Ryoo. Learning latent super-events to detect multiple activities in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018 [arxiv] [code]
[5] A. Piergiovanni and M. S. Ryoo. Temporal Gaussian Mixture Layer for Videos. arXiv preprint arXiv:1803.06316, 2018 [arxiv]