A modular deep learning framework for building neural network models on heterogeneous tabular data.
![]()
PyTorch Frame is a deep learning extension for PyTorch, designed for heterogeneous tabular data with different column types, including numerical, categorical, time, text, and images. It offers a modular framework for implementing existing and future methods. The library features methods from state-of-the-art models, user-friendly mini-batch loaders, benchmark datasets, and interfaces for custom data integration.
PyTorch Frame democratizes deep learning research for tabular data, catering to both novices and experts alike. Our goals are:
-
Facilitate Deep Learning for Tabular Data: Historically, tree-based models (e.g., GBDT) excelled at tabular learning but had notable limitations, such as integration difficulties with downstream models, and handling complex column types, such as texts, sequences, and embeddings. Deep tabular models are promising to resolve the limitations. We aim to facilitate deep learning research on tabular data by modularizing its implementation and supporting the diverse column types.
-
Integrates with Diverse Model Architectures like Large Language Models: PyTorch Frame supports integration with a variety of different architectures including LLMs. With any downloaded model or embedding API endpoint, you can encode your text data with embeddings and train it with deep learning models alongside other complex semantic types. We support the following (but not limited to):
|
OpenAI Embedding Code Example |
Cohere Embed v3 Code Example |
Hugging Face Code Example |

Voyage AI Code Example |
- Library Highlights
- Architecture Overview
- Quick Tour
- Implemented Deep Tabular Models
- Benchmark
- Installation
PyTorch Frame builds directly upon PyTorch, ensuring a smooth transition for existing PyTorch users. Key features include:
- Diverse column types:
PyTorch Frame supports learning across various column types:
numerical,categorical,multicategorical,text_embedded,text_tokenized,timestamp,image_embedded, andembedding. See here for the detailed tutorial. - Modular model design: Enables modular deep learning model implementations, promoting reusability, clear coding, and experimentation flexibility. Further details in the architecture overview.
- Models Implements many state-of-the-art deep tabular models as well as strong GBDTs (XGBoost, CatBoost, and LightGBM) with hyper-parameter tuning.
- Datasets: Comes with a collection of readily-usable tabular datasets. Also supports custom datasets to solve your own problem. We benchmark deep tabular models against GBDTs.
- PyTorch integration: Integrates effortlessly with other PyTorch libraries, facilitating end-to-end training of PyTorch Frame with downstream PyTorch models. For example, by integrating with PyG, a PyTorch library for GNNs, we can perform deep learning over relational databases. Learn more in RelBench and example code.
Models in PyTorch Frame follow a modular design of FeatureEncoder, TableConv, and Decoder, as shown in the figure below:
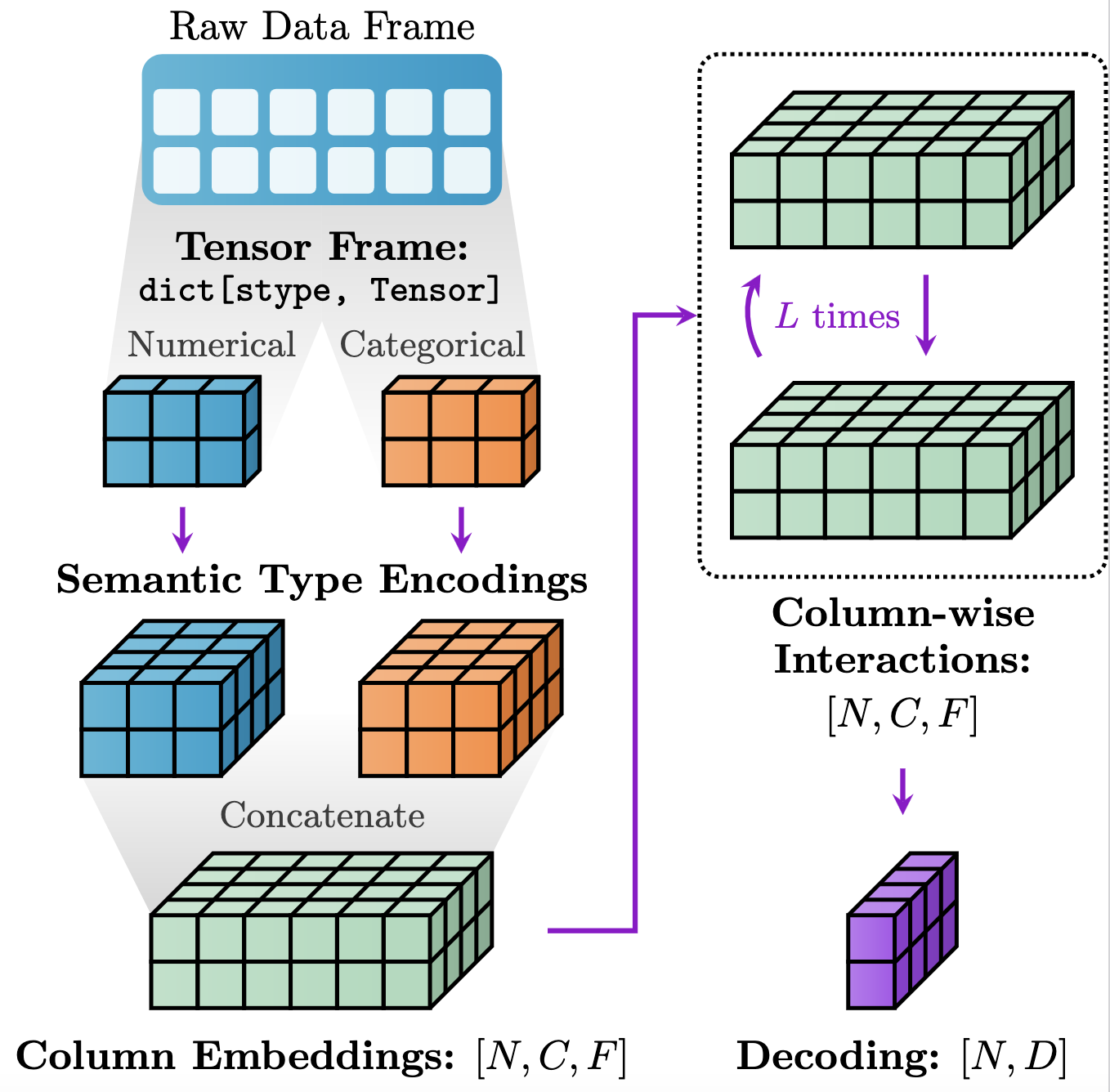
In essence, this modular setup empowers users to effortlessly experiment with myriad architectures:
Materializationhandles converting the raw pandasDataFrameinto aTensorFramethat is amenable to Pytorch-based training and modeling.FeatureEncoderencodesTensorFrameinto hidden column embeddings of size[batch_size, num_cols, channels].TableConvmodels column-wise interactions over the hidden embeddings.Decodergenerates embedding/prediction per row.
In this quick tour, we showcase the ease of creating and training a deep tabular model with only a few lines of code.
As an example, we implement a simple ExampleTransformer following the modular architecture of Pytorch Frame.
In the example below:
self.encodermaps an inputTensorFrameto an embedding of size[batch_size, num_cols, channels].self.convsiteratively transforms the embedding of size[batch_size, num_cols, channels]into an embedding of the same size.self.decoderpools the embedding of size[batch_size, num_cols, channels]into[batch_size, out_channels].
from torch import Tensor
from torch.nn import Linear, Module, ModuleList
from torch_frame import TensorFrame, stype
from torch_frame.nn.conv import TabTransformerConv
from torch_frame.nn.encoder import (
EmbeddingEncoder,
LinearEncoder,
StypeWiseFeatureEncoder,
)
class ExampleTransformer(Module):
def __init__(
self,
channels, out_channels, num_layers, num_heads,
col_stats, col_names_dict,
):
super().__init__()
self.encoder = StypeWiseFeatureEncoder(
out_channels=channels,
col_stats=col_stats,
col_names_dict=col_names_dict,
stype_encoder_dict={
stype.categorical: EmbeddingEncoder(),
stype.numerical: LinearEncoder()
},
)
self.convs = ModuleList([
TabTransformerConv(
channels=channels,
num_heads=num_heads,
) for _ in range(num_layers)
])
self.decoder = Linear(channels, out_channels)
def forward(self, tf: TensorFrame) -> Tensor:
x, _ = self.encoder(tf)
for conv in self.convs:
x = conv(x)
out = self.decoder(x.mean(dim=1))
return outTo prepare the data, we can quickly instantiate a pre-defined dataset and create a PyTorch-compatible data loader as follows:
from torch_frame.datasets import Yandex
from torch_frame.data import DataLoader
dataset = Yandex(root='/tmp/adult', name='adult')
dataset.materialize()
train_dataset = dataset[:0.8]
train_loader = DataLoader(train_dataset.tensor_frame, batch_size=128,
shuffle=True)Then, we just follow the standard PyTorch training procedure to optimize the model parameters. That's it!
import torch
import torch.nn.functional as F
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = ExampleTransformer(
channels=32,
out_channels=dataset.num_classes,
num_layers=2,
num_heads=8,
col_stats=train_dataset.col_stats,
col_names_dict=train_dataset.tensor_frame.col_names_dict,
).to(device)
optimizer = torch.optim.Adam(model.parameters())
for epoch in range(50):
for tf in train_loader:
tf = tf.to(device)
pred = model.forward(tf)
loss = F.cross_entropy(pred, tf.y)
optimizer.zero_grad()
loss.backward()We list currently supported deep tabular models:
- Trompt from Chen et al.: Trompt: Towards a Better Deep Neural Network for Tabular Data (ICML 2023) [Example]
- FTTransformer from Gorishniy et al.: Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) [Example]
- ResNet from Gorishniy et al.: Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) [Example]
- TabNet from Arık et al.: TabNet: Attentive Interpretable Tabular Learning (AAAI 2021) [Example]
- ExcelFormer from Chen et al.: ExcelFormer: A Neural Network Surpassing GBDTs on Tabular Data [Example]
- TabTransformer from Huang et al.: TabTransformer: Tabular Data Modeling Using Contextual Embeddings [Example]
In addition, we implemented XGBoost, CatBoost, and LightGBM examples with hyperparameter-tuning using Optuna for users who'd like to compare their model performance with GBDTs.
We benchmark recent tabular deep learning models against GBDTs over diverse public datasets with different sizes and task types.
The following chart shows the performance of various models on small regression datasets, where the row represents the model names and the column represents dataset indices (we have 13 datasets here). For more results on classification and larger datasets, please check the benchmark documentation.
| Model Name | dataset_0 | dataset_1 | dataset_2 | dataset_3 | dataset_4 | dataset_5 | dataset_6 | dataset_7 | dataset_8 | dataset_9 | dataset_10 | dataset_11 | dataset_12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| XGBoost | 0.250±0.000 | 0.038±0.000 | 0.187±0.000 | 0.475±0.000 | 0.328±0.000 | 0.401±0.000 | 0.249±0.000 | 0.363±0.000 | 0.904±0.000 | 0.056±0.000 | 0.820±0.000 | 0.857±0.000 | 0.418±0.000 |
| CatBoost | 0.265±0.000 | 0.062±0.000 | 0.128±0.000 | 0.336±0.000 | 0.346±0.000 | 0.443±0.000 | 0.375±0.000 | 0.273±0.000 | 0.881±0.000 | 0.040±0.000 | 0.756±0.000 | 0.876±0.000 | 0.439±0.000 |
| LightGBM | 0.253±0.000 | 0.054±0.000 | 0.112±0.000 | 0.302±0.000 | 0.325±0.000 | 0.384±0.000 | 0.295±0.000 | 0.272±0.000 | 0.877±0.000 | 0.011±0.000 | 0.702±0.000 | 0.863±0.000 | 0.395±0.000 |
| Trompt | 0.261±0.003 | 0.015±0.005 | 0.118±0.001 | 0.262±0.001 | 0.323±0.001 | 0.418±0.003 | 0.329±0.009 | 0.312±0.002 | OOM | 0.008±0.001 | 0.779±0.006 | 0.874±0.004 | 0.424±0.005 |
| ResNet | 0.288±0.006 | 0.018±0.003 | 0.124±0.001 | 0.268±0.001 | 0.335±0.001 | 0.434±0.004 | 0.325±0.012 | 0.324±0.004 | 0.895±0.005 | 0.036±0.002 | 0.794±0.006 | 0.875±0.004 | 0.468±0.004 |
| FTTransformerBucket | 0.325±0.008 | 0.096±0.005 | 0.360±0.354 | 0.284±0.005 | 0.342±0.004 | 0.441±0.003 | 0.345±0.007 | 0.339±0.003 | OOM | 0.105±0.011 | 0.807±0.010 | 0.885±0.008 | 0.468±0.006 |
| ExcelFormer | 0.262±0.004 | 0.099±0.003 | 0.128±0.000 | 0.264±0.003 | 0.331±0.003 | 0.411±0.005 | 0.298±0.012 | 0.308±0.007 | OOM | 0.011±0.001 | 0.785±0.011 | 0.890±0.003 | 0.431±0.006 |
| FTTransformer | 0.335±0.010 | 0.161±0.022 | 0.140±0.002 | 0.277±0.004 | 0.335±0.003 | 0.445±0.003 | 0.361±0.018 | 0.345±0.005 | OOM | 0.106±0.012 | 0.826±0.005 | 0.896±0.007 | 0.461±0.003 |
| TabNet | 0.279±0.003 | 0.224±0.016 | 0.141±0.010 | 0.275±0.002 | 0.348±0.003 | 0.451±0.007 | 0.355±0.030 | 0.332±0.004 | 0.992±0.182 | 0.015±0.002 | 0.805±0.014 | 0.885±0.013 | 0.544±0.011 |
| TabTransformer | 0.624±0.003 | 0.229±0.003 | 0.369±0.005 | 0.340±0.004 | 0.388±0.002 | 0.539±0.003 | 0.619±0.005 | 0.351±0.001 | 0.893±0.005 | 0.431±0.001 | 0.819±0.002 | 0.886±0.005 | 0.545±0.004 |
We see that some recent deep tabular models were able to achieve competitive model performance to strong GBDTs (despite being 5--100 times slower to train). Making deep tabular models even more performant with less compute is a fruitful direction for future research.
We also benchmark different text encoders on a real-world tabular dataset (Wine Reviews) with one text column. The following table shows the performance:
| Test Acc | Method | Model Name | Source |
|---|---|---|---|
| 0.7926 | Pre-trained | sentence-transformers/all-distilroberta-v1 (125M # params) | Hugging Face |
| 0.7998 | Pre-trained | embed-english-v3.0 (dimension size: 1024) | Cohere |
| 0.8102 | Pre-trained | text-embedding-ada-002 (dimension size: 1536) | OpenAI |
| 0.8147 | Pre-trained | voyage-01 (dimension size: 1024) | Voyage AI |
| 0.8203 | Pre-trained | intfloat/e5-mistral-7b-instruct (7B # params) | Hugging Face |
| 0.8230 | LoRA Finetune | DistilBERT (66M # params) | Hugging Face |
The benchmark script for Hugging Face text encoders is in this file and for the rest of text encoders is in this file.
PyTorch Frame is available for Python 3.9 to Python 3.11.
pip install pytorch-frame
See the installation guide for other options.
If you use PyTorch Frame in your work, please cite our paper (Bibtex below).
@article{hu2024pytorch,
title={PyTorch Frame: A Modular Framework for Multi-Modal Tabular Learning},
author={Hu, Weihua and Yuan, Yiwen and Zhang, Zecheng and Nitta, Akihiro and Cao, Kaidi and Kocijan, Vid and Leskovec, Jure and Fey, Matthias},
journal={arXiv preprint arXiv:2404.00776},
year={2024}
}