New Ideas About Temporal Pooling
Discussion about this text is on the nupic-discuss mailing list.
Temporal Pooling, or TP, was described in the HTM/CLA whitepaper. However, the mechanism I proposed for TP always had problems (both biological and theoretical). It was close but we could never get it to work cleanly. I now have a new proposal for how temporal pooling works. It is more elegant and more powerful. I have not worked through all the details yet, but several people asked to hear my current thinking on this so that is what this email is about.
When working on the new temporal pooling mechanism I had further insights that led me to a better understanding of why the cortex has multiple layers of cells and how they interact. This is a major extension of HTM theory and I will also briefly describe that. The new ideas on temporal pooling and cortical layers in this email are untested; please consider them as speculative and unproven.
First a little background. The CLA consists of three components.
- Spatial Pooler: This SP converts a sparse distributed input into a new SDR with a fixed number of bits and a relatively fixed sparseness. Each bit output by the SP corresponds to a column of cells.
- Sequence memory: The CLA sequence memory learns sequences of SDRs. It uses the columns to represent inputs uniquely in different contexts.
- Temporal Pooler: The TP forms a stable representation over sequences.
(Unfortunately we got into the habit of using the term “temporal pooler” for both the sequence memory and temporal pooling proper. In this document temporal pooling will only refer to forming stable representations over a sequence of patterns.)
The basic idea of temporal pooling is patterns that occur adjacent in time probably have a common underlying cause and therefore the brain forms a stable representation for a series of input patterns. An example is a spoken word. If we hear a word several times we learn the sequence of sounds and then form a stable representation for the word. The input to the ears is changing but elsewhere there are cells that are stable throughout the word. Another example is when looking at an image of a familiar face. Several times a second your eyes fixate on a different part of the image causing a complete change of input. Despite this changing input stream your perception is stable. Several levels up in the cortical hierarchy there are cells that are selective for the particular person you are seeing and these cells stay active even though the input from the eyes are changing. (The most well-known of these experiments involve cells that are selective for images of celebrities, such as Jennifer Aniston. They were found while fully conscious humans had their brains exposed prior to surgery.) Of course, a single cell cannot learn to recognize an entire face. This requires a hierarchy where each level in the hierarchy is temporal pooling.
In both these cases cells remain active for multiple distinct feedforward input patterns. Cells learn to recognize and respond to different feedforward patterns when those patterns occur one after another in time. Temporal pooling is a deduced property, we can be confident it is happening throughout the cortex.
Temporal pooling occurs between layers of cells, not just between regions.
In On Intelligence I wrote that temporal pooling occurs between regions in the cortical hierarchy. As you ascend the hierarchy from region 1 to region 2, region 2 forms a stable representation of the changing patterns in region 1. Conversely, when a stable pattern in region 2 projects back to region 1 it invokes sequences of patterns in region 1.
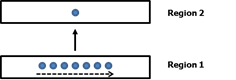
In this diagram the dots represent SDRs and the row of dots represents a sequence of SDRs over time.
I now believe that temporal pooling is also occurring between layers of cells within a region. The canonical feedforward flow of information in a cortical region is from layer 4 to layer 3 then to layer 4 of the next higher region. Layer 4 also projects to layer 5 and then to layer 6. I believe layers 5 and 6 are using the same basic mechanism and I am making some progress in understanding them. For now I will restrict my comments to layers 4 and 3Here is what I think is happening in layers 4 and 3.
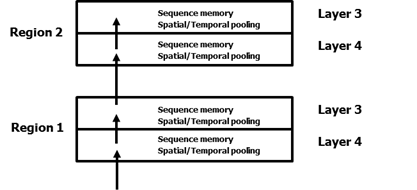
Why have two layers of sequence memory, 4 and 3, in a region? What is the difference between layer 4 and layer 3?
A region of cortex is trying to build a predictive model of the changing input it receives. Sensory input changes because of two fundamental reasons. One is because your body and sensors move, the other is because objects in the world change on their own. For example if you are walking alone in a house then all the changes that occur on your sensors are because you are moving your eyes, head, and body. If you stood still and didn’t move your eyes there would be no changes in your sensory input. Another example is as you are look at a picture the changes occurring on your retinas are solely because your eyes are moving several times a second. The second reason sensory data can change is because objects in the world are changing on their own. For example if there were a dog walking in the house with you or if it barked it would cause changes on your sensors that were not caused by your own movement.
As a general rule, sub-cortical neurons that generate behavior have split axons. One branch generates the behavior and the other is sent to the cortex. If the cortex didn’t get copies of motor commands you couldn’t function. Every time you moved your eyes or turned your head it would appear as if the world was spinning and shifting.
I believe layer 4 models the changes in the input due to the body’s behavior. Layer 3 models the changes in the input that cannot be predicted by layer 4. I am able to show that if you take the standard CLA sequence memory and feed it both sensory data and motor commands (such as a sparse coding of a saccade’s direction and distance) it can learn to predict changes due to behavior. For example it can learn to predict what the eyes will see after a saccade (something known to occur in V1 and elsewhere). If layer 4 can successfully predict changes due to the body’s own behavior then the representations in the layer 4 sequence memory will be very sparse (one cell per column). If we TP over these changing patterns then the representation in layer 3 will be stable. If you were looking at a still image layer 4 would change with each saccade and layer 3 would be relatively stable. The representation in layer 3 would be independent of where you are fixating on the image. (Again, to form a fully stable representation of an image requires a hierarchy of regions.)
Any change that a layer cannot predict will be passed on as a change in the next layer. Any change that a layer can predict will be pooled and not result in a change in the next layer. Put another way, any change that cannot be predicted will continue up the hierarchy, first layer 4 to layer 3 then region to region. If you were looking at a walking dog, layer 4 would provide an input to layer 3 that after temporal pooling would be partially stable (the image of the dog) and partly not stable because the dog is moving. Layer 3 would try to learn the pure high order sequence of walking. All these examples require a hierarchy, but applied to simple problems you might not need a hierarchy.
Note that in layer 4 the order of patterns does not have to be repeatable. It does not have to be a high order sequence. The order and direction of saccades does not have to follow a set pattern. Similarly if I was walking through a house the order in which I do it, turning left or right, can vary. Layer 4 can handle this because it has a copy of the motor command generating the change. Layer 3 on the other hand does not get a copy of a motor command. The only way it can model the data is to look for high order sequences.
The concept of modeling changes due to our own behavior can be applied to touch, audition, and vision. It is a powerful idea that explains how we form representations of the world that are not independent of our sensor or body positions and why the world seems stable even though the patterns on our sensors are rapidly changing. It explains how you perceive objects independent of where the object is and how you are currently sensing it. For example, imagine you reach into your purse to grab a pair of eye glasses. The actual sensations on your skin are a short sequence of edges, corners, and surfaces. But you perceive the entire glasses. This is directly analogous to moving your eyes over an image.
I am not going to go through exactly how I believe layer 4 works here. I will do that another time. But it looks like that by changing the contextual information available to the standard CLA sequence memory you will get the desired result. Today NuPIC is equivalent to layer 3.
This concept of layer 4 and layer 3 modeling different aspects of an input stream requires temporal pooling between layers, not just between regions. Layer 3 has to form a stable representation (temporal pooling) of predicted changes in layer 4.
Temporal Pooling can be combined with Spatial Pooling.
You might have noticed in the diagram above I labeled the first operation of a layer of cells “Spatial/Temporal Pooling”. It took me a long time to realize that a small change to the spatial pooler will allow it to do temporal pooling as well. And we need to do both spatial and temporal pooling as information moves from layer to layer and region to region. The required small change is to have the cells in a column to stay active longer so they learn to recognize multiple input patterns over time.
The standard SP does these steps.
- Receive as input a sequence of SDRs.
- Use a competitive process to learn a set of common spatial patterns in the input sequence.
- Assign a column of cells to be active for each spatial pattern in the set.
- Ensure each cell in a column learns the same feedforward response properties.
The trick to adding TP to the SP is the following. When the input to the SP was correctly predicted in the previous layer we want the cells in the column to remain active long enough to learn to respond to the next input pattern. If the input to the SP was not predicted in the previous layer then we don’t want cells in the column to remain active longer than the current input (the existing SP behavior). Temporal pooling is achieved by extending the activity of the cells in the column. But only when the input to the column was predicted in the previous layer.
It is easy to do this in software, but how might this happen with real neurons? (If you don’t care about the biology you might want to skip the next section.)
Temporal pooling uses metabotropic synapses to distinguish predicted vs. non-predicted inputs.
One of the key requirements of temporal pooling is that we only want to do it when a sequence is being correctly predicted. For example, we don’t want to form a stable representation of a sequence of random transitions.
The old TP mechanism, the one in the white paper, proposed that a cell would learn to fire longer and longer in advance by predicting further back in time. In this way a cell would stay active as long as the sequence was predictable. There were several problems with this method that I couldn’t resolve.
The new proposal, described above, says that when a column of cells becomes active due to feedforward input the cells in the column will remain active for longer than normal if the feedforward input was from cells that predicted their activity. If the input cells were not predicted then the cells in the column should stay active only briefly.
There is a biological mechanism for this that fits well, but I have not been able to verify all the details. Here is the biological mechanism. Active synapses open and close ion channels, this happens rapidly on the order of a few milliseconds. The effect of an active synapse on the destination cell is short lived. However many synapses are paired with another type of receptor called a metabotropic receptor. If the metabotropic receptor is activated it will have a long duration effect on the destination cell, from 100s of milliseconds to several seconds. Metabotropic receptors can provide the means for keeping a cell active for a second or more, exactly what we need for temporal pooling.
Metabotropic receptors are not always activated. They require a short burst of action potentials to be invoked. As little as two action potentials 10msec apart are sufficient. Without that short burst the a metabotropic receptor will remain inactive. There is a lot of literature on metabotropic receptors and these properties. They are common in cortical neurons and the locations where they are not present also makes sense from a theory point of view.
Does a cell that is in a predictive state (depolarized) generate a small burst of action potentials when it first fires? That is what is required for the new TP mechanism to work. There is some evidence for this. Layer 5 cells are well known for starting with a short burst of action potentials under certain conditions. They are sometimes labeled “intrinsically bursting neurons” to reflect this. Some scientists have reported short bursts in layer 4 and layer 3 cells but not consistently so, unlike layer 5. We wouldn’t expect to see bursts in layer 4 cells in an anesthetized animal which is not generating behavior. The majority of experiments where individual cells are recorded are done with animals that are anesthetized and unable to move. Evidence for short bursts of action potentials under the correct conditions is the biggest missing piece of the new proposed TP mechanism.
The new TP mechanism, the combination of SP and TP, and the ideas for layers 4 and 3 are compelling. They explain a lot of things. So I am going to try hard to find the biological mechanisms that support these ideas. A lot of neuroscience details match up well but there are more I need to verify.
This year I want to empirically test the layer 4 ideas combined with temporal pooling. It should be possible to build a powerful hierarchical vision system. If we restrict it to spatial images and use saccades for training we could build the entire thing with a hierarchy of layer 4-only regions. Training such a system might be slow but inference should be fast. Perhaps the NuPIC community could do this in collaboration with some Grok engineers.
Jeff Hawkins, Jan 22, 2014