-
Notifications
You must be signed in to change notification settings - Fork 28
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge pull request #244 from roscisz/develop
r0.3.3
- Loading branch information
Showing
18 changed files
with
286 additions
and
57 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,95 @@ | ||
| # Using TensorHive for running distributed trainings in PyTorch | ||
|
|
||
| ## Detailed example description | ||
|
|
||
| In this example we show how the TensorHive `task execution` module can be | ||
| used for convenient configuration and execution of distributed trainings | ||
| implemented in PyTorch. For this purpose, we run | ||
| [this PyTorch DCGAN sample application](https://github.com/roscisz/dnn_training_benchmarks/tree/master/PyTorch_dcgan_lsun/README.md) | ||
| in a distributed setup consisting of a NVIDIA DGX Station server `ai` and NVIDIA DGX-1 server `dl`, | ||
| equipped with 4 and 8 NVIDIA Tesla V100 GPUs respectively. | ||
|
|
||
| In the presented scenario, the servers were shared by a group of users using TensorHive | ||
| and at the moment we were granted reservations for GPUs 1 and 2 on `ai` and GPUs 1 and 7 on `dl`. | ||
| The python environment and training code were available on both nodes and | ||
| fake training dataset was used. | ||
|
|
||
|
|
||
| ## Running without TensorHive | ||
|
|
||
| In order to enable networking, we had to set the `GLOO_SOCKET_IFNAME` | ||
| environment variable to proper network interface names on both nodes. | ||
| We selected the 20011 TCP port for communication. | ||
|
|
||
| For our 4 GPU scenario, the following 4 processes had to be executed, | ||
| taking into account setting consecutive `rank` parameters starting from 0 and the `world-size` | ||
| parameter to 4: | ||
|
|
||
| worker 0 on `ai`: | ||
| ``` | ||
| export CUDA_VISIBLE_DEVICES=1 | ||
| export GLOO_SOCKET_IFNAME=enp2s0f1 | ||
| ./dnn_training_benchmarks/PyTorch_dcgan_lsun/examples/dcgan/venv/bin/python dnn_training_benchmarks/PyTorch_dcgan_lsun/examples/dcgan/main.py --init-method tcp://ai.eti.pg.gda.pl:20011 --backend=gloo --rank=0 --world-size=4 --dataset fake --cuda | ||
| ``` | ||
|
|
||
| worker 1 on `ai`: | ||
| ``` | ||
| export CUDA_VISIBLE_DEVICES=2 | ||
| export GLOO_SOCKET_IFNAME=enp2s0f1 | ||
| ./dnn_training_benchmarks/PyTorch_dcgan_lsun/examples/dcgan/venv/bin/python dnn_training_benchmarks/PyTorch_dcgan_lsun/examples/dcgan/main.py --init-method tcp://ai.eti.pg.gda.pl:20011 --backend=gloo --rank=1 --world-size=4 --dataset fake --cuda | ||
| ``` | ||
|
|
||
| worker 2 on `dl`: | ||
| ``` | ||
| export CUDA_VISIBLE_DEVICES=1 | ||
| export GLOO_SOCKET_IFNAME=enp1s0f0 | ||
| ./dnn_training_benchmarks/PyTorch_dcgan_lsun/examples/dcgan/venv/bin/python dnn_training_benchmarks/PyTorch_dcgan_lsun/examples/dcgan/main.py --init-method tcp://ai.eti.pg.gda.pl:20011 --backend=gloo --rank=2 --world-size=4 --dataset fake --cuda | ||
| ``` | ||
|
|
||
| worker 3 on ai: | ||
| ``` | ||
| export CUDA_VISIBLE_DEVICES=7 | ||
| export GLOO_SOCKET_IFNAME=enp1s0f0 | ||
| ./dnn_training_benchmarks/PyTorch_dcgan_lsun/examples/dcgan/venv/bin/python dnn_training_benchmarks/PyTorch_dcgan_lsun/examples/dcgan/main.py --init-method tcp://ai.eti.pg.gda.pl:20011 --backend=gloo --rank=3 --world-size=4 --dataset fake --cuda | ||
| ``` | ||
|
|
||
|
|
||
| ## Running with TensorHive | ||
|
|
||
| Because running the distributed training required in our scenario means | ||
| logging into multiple nodes, configuring environments and running processes | ||
| with multiple, similar parameters, differing only slightly, it is a good | ||
| use case for the TensorHive `task execution` module. | ||
|
|
||
| To use it, first head to `Task Overview` and click on `CREATE TASKS FROM TEMPLATE`. Choose PyTorch from the drop-down list: | ||
|
|
||
|  | ||
|
|
||
| Fill the PyTorch process template with your specific python command, command-line | ||
| parameters and environment variables. | ||
| You don't need to fill in rank or world-size parameters as TensorHive will do that automatically for you: | ||
|
|
||
| 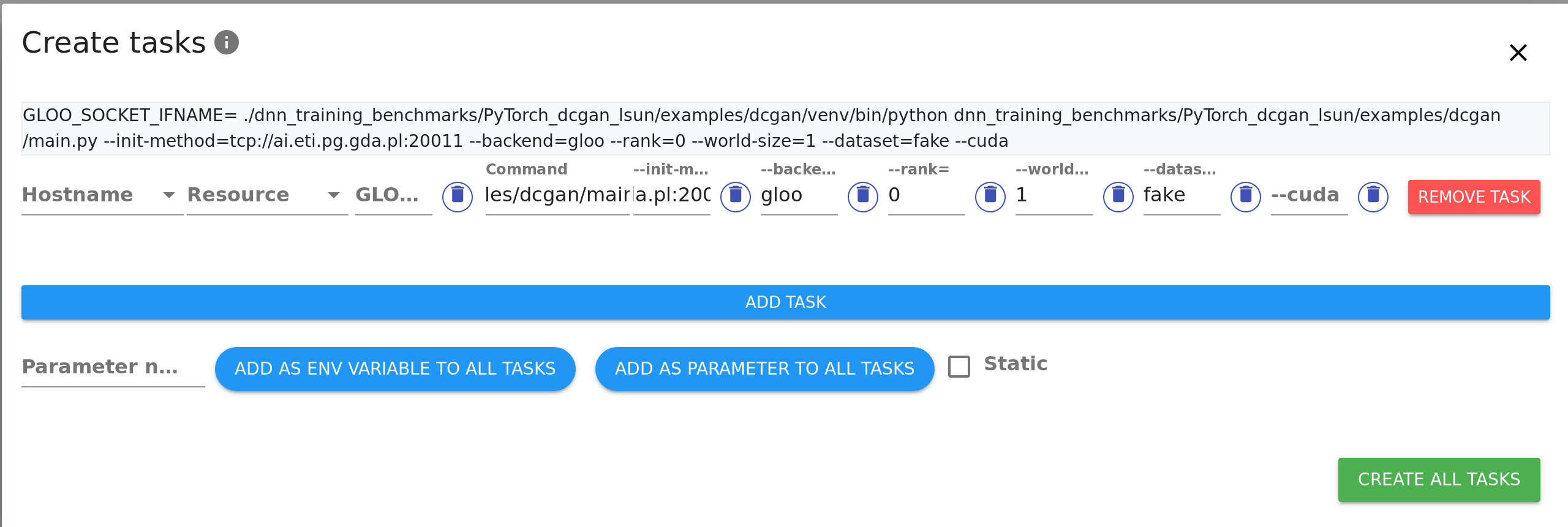 | ||
|
|
||
| Add as many tasks as resources you wish the code to run on using `ADD TASK` button. You can see that every parameter filled is copied to newly created tasks to save time. Adjust hostnames and resources on the added tasks as needed. | ||
|
|
||
| 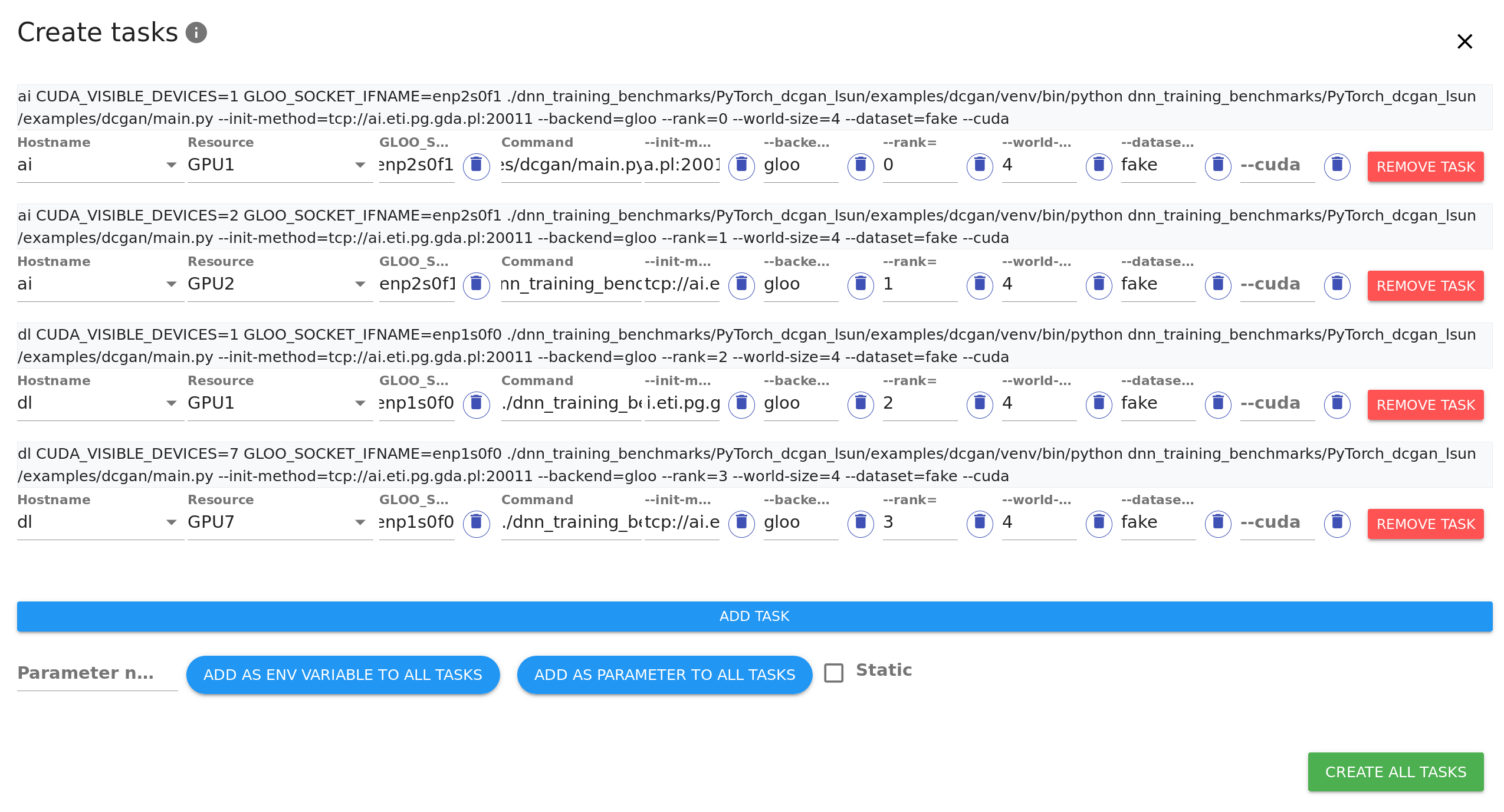 | ||
|
|
||
|
|
||
| Click `CREATE ALL TASKS` button in the right bottom corner to create the tasks. | ||
| Then, select them in the process table and use the `Spawn selected tasks` button, | ||
| to run them on the appropriate nodes: | ||
|
|
||
| 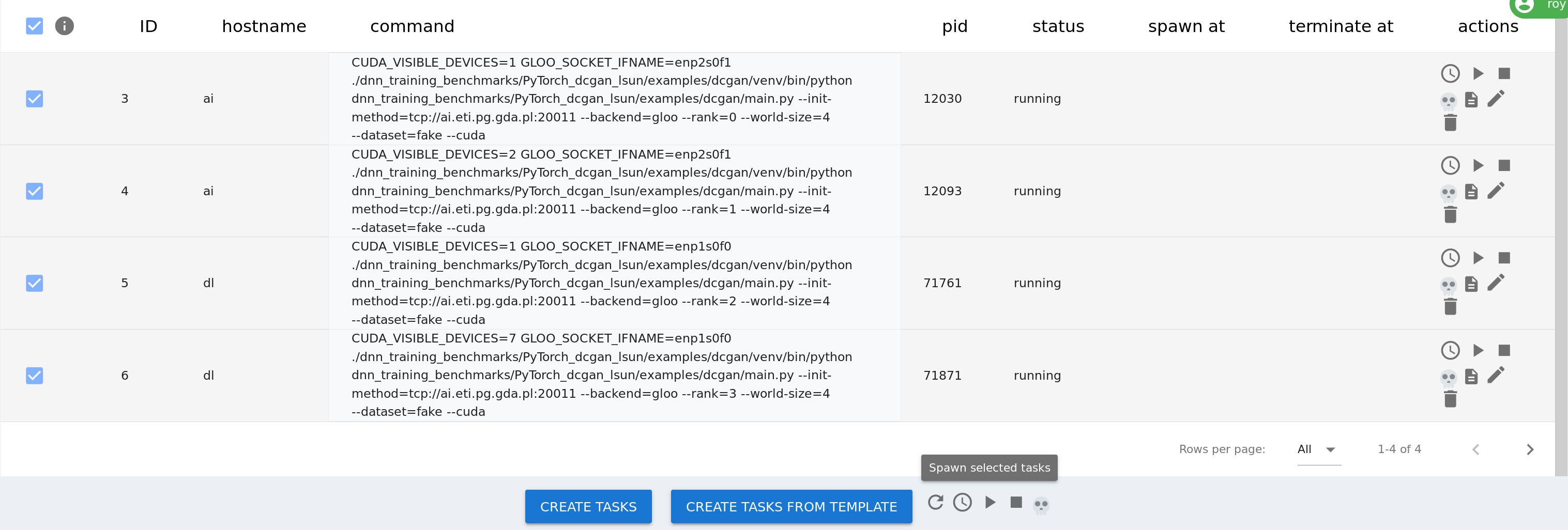 | ||
|
|
||
| After that, the tasks can be controlled from `Task Overview`. | ||
| The following actions are currently available: | ||
| - Schedule (Choose when to run the task) | ||
| - Spawn (Run the task now) | ||
| - Terminate (Send terminate command to the task) | ||
| - Kill (Send kill command) | ||
| - Show log (Read output of the task) | ||
| - Edit | ||
| - Remove | ||
|
|
||
| Having that high level control over all of the tasks from a single place can be extremely time-saving! |
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,16 +1,11 @@ | ||
| # Examples | ||
| This directory contains examples of deep neural network training applications that serve as | ||
| requirement providers towards TensorHive. We are testing their performance and ease of use depending | ||
| on computing resource management software used. This allows us to learn about various features of | ||
| existing resource management systems and base our design decisions on the experiences with approaches | ||
| such as native application execution, application-specific scripts, Docker and | ||
| [Kubernetes](https://gist.github.com/PiotrowskiD/1e3f659a8ac7db1c2ca02ba0ae5fcfaf). | ||
|
|
||
| The applications can be also useful for others as benchmarks. Our benchmark results, useful resources | ||
| and more info about configuration and running examples can be found in corresponding folders. | ||
| We plan to add TensorHive usage examples to the individual directories when distributed training deployment | ||
| is supported by TensorHive | ||
|
|
||
|
|
||
|
|
||
|
|
||
| This directory contains usage examples of the TensorHive task execution | ||
| module for chosen DNN training scenarios: | ||
|
|
||
| Directory | Description | ||
| --- | --- | ||
| TF_CONFIG | Using the default cluster configuration method in TensorFlowV2 - the TF_CONFIG environment variable. | ||
| TensorFlow_ClusterSpec | Using the standard ClusterSpec parameters, often used in TensorFlowV1 implementations. | ||
| PyTorch | Using standard parameters used in PyTorch implementations. | ||
| deepspeech | Redirection to the DeepSpeech test application, kept for link maintenance. | ||
| t2t_transformer | Redirection to the DeepSpeech test application, kept for link maintenance. |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.