- intelligent defaults: it uses a combination of Pair Distance (2-gram) and Levenshtein Edit Distance to effectively match many examples with no configuration
- all-vs-all: it takes care of finding the optimal match by comparing everything against everything else (when that's necessary)
- refinable: you might get to 90% with no configuration, but if you need to go beyond you can use regexps, grouping, and stop words
It solves many mid-range matching problems — if your haystack is ~10k records — if you can winnow down the initial possibilities at the database level and only bring good contenders into app memory — why not give it a shot?
Find a needle in a haystack based on string similarity and regular expression rules.
Replaces loose_tight_dictionary because that was a confusing name.
Warning! normalizers are gone in version 2 and above! See the CHANGELOG and check out enhanced (and hopefully more intuitive) groupings.

>> require 'fuzzy_match'
=> true
>> FuzzyMatch.new(['seamus', 'andy', 'ben']).find('Shamus')
=> "seamus"
See also the blog post Fuzzy match in Ruby.
At the core, and even if you configure nothing else, string similarity (calculated by "pair distance" aka Dice's Coefficient) is used to compare records.
You can tell FuzzyMatch what field or method to use via the :read option... for example, let's say you want to match a Country object like #<Country name:"Uruguay" iso_3166_code:"UY">
>> fz = FuzzyMatch.new(Country.all, :read => :name)
=> #<FuzzyMatch: [...]>
>> fz.find('youruguay')
=> #<Country name:"Uruguay" iso_3166_code:"UY">
You can improve the default matchings with rules. There are 3 different kinds of rules. Each rule is a regular expression.
We suggest that you first try without any rules and only define them to improve matching, prevent false positives, etc.
Group records together. The two laws of groupings:
- If a needle matches a grouping, only compare it with straws in the same grouping; (the "buddies vs buddies" rule)
- If a needle doesn't match any grouping, only compare it with straws that also don't match ANY grouping (the "misfits vs misfits" rule)
The two laws of chained groupings: (new in v2.0 and rather important)
- Sub-groupings (e.g.,
/plaza/ibelow) only match if their primary (e.g.,/ramada/i) does - In final grouping decisions, sub-groupings win over primaries (so "Ramada Inn" is NOT grouped with "Ramada Plaza", but if you removed
/plaza/isub-grouping, then they would be grouped together)
Hopefully they are rather intuitive once you start using them.
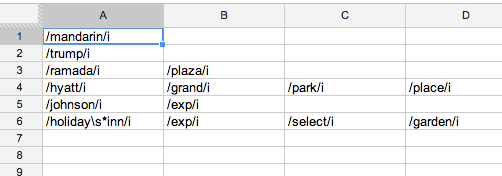
That will...
- separate "Orient Express Hotel" and "Ramada Conference Center Mandarin" from real Mandarin Oriental hotels
- keep "Trump Hotel Collection" away from "Luxury Collection" (another real hotel brand) without messing with the word "Luxury"
- make sure that "Ramada Plaza" are always grouped with other RPs—and not with plain old Ramadas—and vice versa
- splits out Hyatts into their different brands
- and more
You specify chained groupings as arrays of regexps:
groupings = [
/mandarin/i,
/trump/i,
[ /ramada/i, /plaza/i ],
...
]
fz = FuzzyMatch.new(haystack, groupings: groupings)
This way of specifying groupings is meant to be easy to load from a CSV, like bin/fuzzy_match does.
Formerly called "blockings," but that was jargon that confused people.
Prevent impossible matches. Can be very confusing—see if you can make things work with groupings first.
Adding an identity like /(f)-?(\d50)/i ensures that "Ford F-150" and "Ford F-250" never match.
Note that identities do not establish certainty. They just say whether two records could be identical... then string similarity takes over.
Ignore common and/or meaningless words when doing string similarity.
Adding a stop word like THE ensures that it is not taken into account when comparing "THE CAT", "THE DAT", and "THE CATT"
Stop words are NOT removed when checking :must_match_at_least_one_word and when doing identities and groupings.
read: how to interpret each record in the 'haystack', either a Proc or a symbolmust_match_grouping: don't return a match unless the needle fits into one of the groupings you specifiedmust_match_at_least_one_word: don't return a match unless the needle shares at least one word with the match. Note that "Foo's" is treated like one word (so that it won't match "'s") and "Bolivia," is treated as just "bolivia"gather_last_result: enablelast_result
String similarity is case-insensitive. Everything is downcased before scoring. This is a change from previous versions.
Be careful with uppercase letters in your rules; in general, things are downcased before comparing.
The algorithm is Dice's Coefficient (aka Pair Distance) because it seemed to work better than Longest Substring, Hamming, Jaro Winkler, Levenshtein (although see edge case below) etc.
Here's a great explanation copied from the wikipedia entry:
to calculate the similarity between:
night
nacht
We would find the set of bigrams in each word:
{ni,ig,gh,ht}
{na,ac,ch,ht}
Each set has four elements, and the intersection of these two sets has only one element: ht.
Inserting these numbers into the formula, we calculate, s = (2 · 1) / (4 + 4) = 0.25.
In edge cases where Dice's finds that two strings are equally similar to a third string, then Levenshtein distance is used. For example, pair distance considers "RATZ" and "CATZ" to be equally similar to "RITZ" so we invoke Levenshtein.
>> 'RITZ'.pair_distance_similar 'RATZ'
=> 0.3333333333333333
>> 'RITZ'.pair_distance_similar 'CATZ'
=> 0.3333333333333333 # pair distance can't tell the difference, so we fall back to levenshtein...
>> 'RITZ'.levenshtein_similar 'RATZ'
=> 0.75
>> 'RITZ'.levenshtein_similar 'CATZ'
=> 0.5 # which properly shows that RATZ should win
Make sure you add active_record_inline_schema to your gemfile.
TODO write documentation. For now, please see how we manually cache matches between aircraft and flight segments.
The admittedly imperfect metaphor is "look for a needle in a haystack"
- needle: the search term
- haystack: the records you are searching (your result will be an object from here)
You can optionally use amatch by Florian Frank (thanks Flori!) to make string similarity calculations in a C extension.
require 'fuzzy_match'
require 'amatch' # note that you have to require this... fuzzy_match won't require it for you
FuzzyMatch.engine = :amatch
Otherwise, pure ruby versions of the string similarity algorithms derived from the answer to a StackOverflow question and the text gem are used. Thanks marzagao and threedaymonk!

{kind=link}
{kind=link}
We use fuzzy_match for data science at Brighter Planet and in production at
We often combine it with remote_table and errata:
- download table with
remote_table - correct serious or repeated errors with
errata fuzzy_matchthe rest
- Seamus Abshere [email protected]
- Ian Hough [email protected]
- Andy Rossmeissl [email protected]
- Luke Rodgers @lukeasrodgers
Copyright 2013 Seamus Abshere