
The Dataset used in this project is available on the UCI machine learning Repository. It can be found at: https://archive.ics.uci.edu/ml/datasets/Arrhythmia.
- It consists of 452 different examples spread over 16 classes. Of the 452 examples,245 are of "normal" people.
- We also have 12 different types of arrhythmias. Among all these types of arrhythmias, the most representative are the "coronary artery disease" and "Rjgbt boundle branch block".
- We have 279 features, which include age, sex, weight, height of patients and other related information.
- We explicitly observe that the number of features is relatively high compared to the number of examples we are available.
- Our goal was to predict if a person is suffering from arrhythmia or not, and if yes, classify it in to one of 12 available groups.
- 1- Reports and presentations - Contains project report, presentation and papers.
- Data Preprocessing Notebook
- Exploratory Data Analysis Notebook
- Final Notebook with pca
- Oversampled notebook at
- KNN Classifier
- Logestic Regression
- Decision Tree Classifier
- Linear SVC
- Kernelized SVC
- Random Forest Classifier
- Principal Component analysis (PCA)
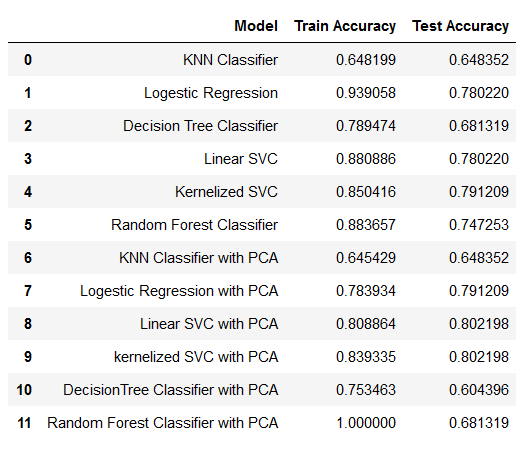
The models started performing better after we applied PCA on the resampled data. The reason behind this is, PCA reduces the complexity of the data. It creates components based on giving importance to variables with large variance and also the components which it creates are non collinear in nature which means it takes care of collinearity in large data set. PCA also improves the overall execution time and quality of the models and it is very beneficial when we are working with huge amount of variables.
The Best model in term of recall score is Kernalized SVM with PCA having accuracy of 80.21%.