{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
My submission uses a stacked ensemble model combining XGBoost and LightGBM classifiers to enhance predictive performance. The stacking approach leverages multiple base models to improve overall accuracy by combining their strengths.
In this data preprocessing pipeline, several steps are undertaken to clean and prepare the dataset for machine learning:
Feature Importance:
Columns such as step, customer, zipcodeOri, and zipMerchant are dropped from the dataset as they may not provide meaningful insights for the model. Handling Missing and Categorical Data:
The age column, which contains the value 'U' for unknown ages, is cleaned by replacing 'U' with NaN, removing any quotation marks, and converting the data to a numerical format. Missing values in age are then filled with the median age.
Categorical columns like gender, merchant, and category are encoded using LabelEncoder to convert text labels into numerical values that can be used by machine learning models.
Scaling Numerical Data:
The amount column is standardized using StandardScaler to ensure that all features contribute equally to the model and to improve convergence during training.
Dealing with Class Imbalance
In this dataset, only 1.2% of the transactions are fraudulent, while 98.8% are not. Such a severe class imbalance can lead to misleading results if accuracy is used as the primary evaluation metric. For instance, a model that predicts all transactions as non-fraudulent would achieve 98.8% accuracy but would be completely ineffective at identifying fraud.
To address this, Synthetic Minority Over-sampling Technique (SMOTE) was used. SMOTE artificially increases the number of fraudulent transactions by generating synthetic samples, balancing the dataset and improving the model's ability to detect fraud. This technique helps ensure that the model learns from both classes effectively, making metrics like precision, recall, and F1 score more reliable indicators of performance in this context.
Insights from Data
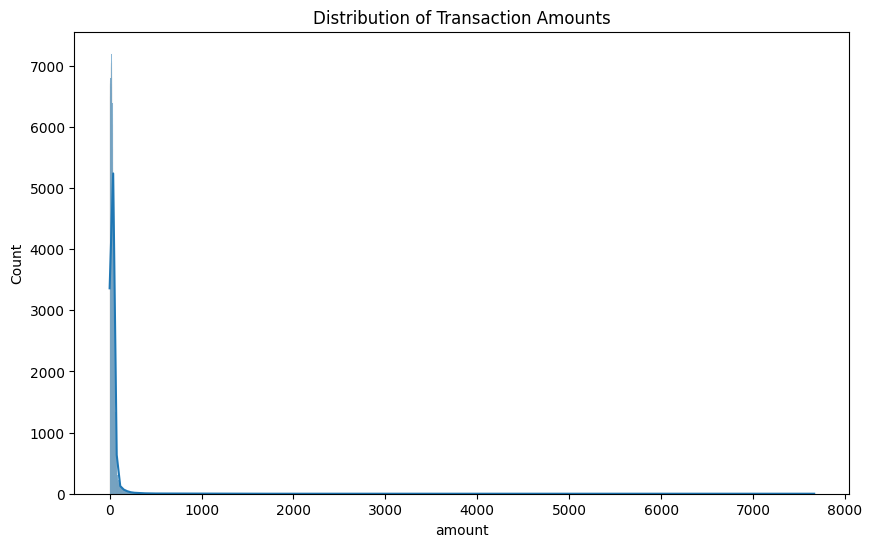
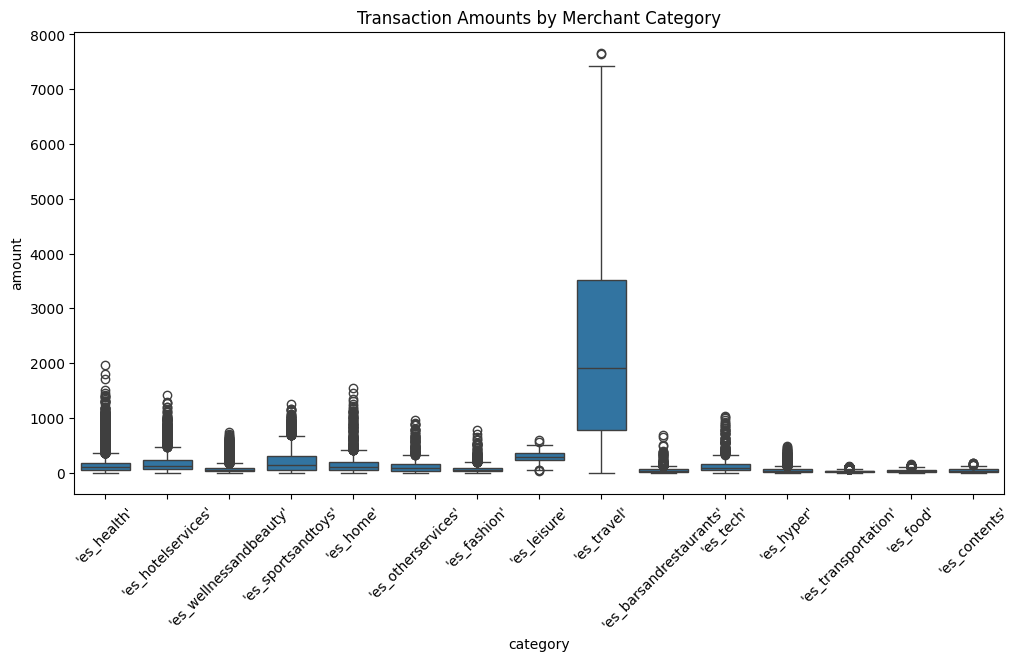
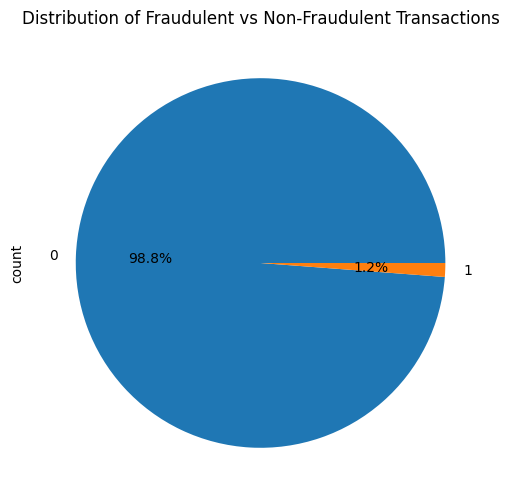
Type|XGBClassifier
Parameters:
- colsample_bytree: 1.0
- learning_rate: 0.3
- max_depth: 10
- n_estimators: 600
- subsample: 1.0
- gamma: 2.0
- min_child_weight: 1
- tree_method: 'gpu_hist'
- use_label_encoder: False
This model uses gradient boosting with GPU acceleration to handle large datasets and complex patterns efficiently. The chosen parameters aim to balance model complexity and training stability.
Type|LGBMClassifier
Parameters:
- n_estimators: 500
- learning_rate: 0.01
- max_depth: 10
LightGBM is used for its efficiency and speed in handling large datasets. The learning rate is set lower to ensure gradual model training and avoid overfitting.
Type|StackingClassifier
Base Models:
- xgb_model: XGBoost classifier
- lgbm_model: LightGBM classifier
Final Estimator: A second XGBoost model with the same parameters as xgb_model The stacking classifier combines the predictions from xgb_model and lgbm_model, using them as input to a final XGBoost model that refines the predictions for improved accuracy.
Type: Train
| Metric | Score |
|---|---|
| Precision | 0.9796 |
| Recall | 0.9915 |
| F1 Score | 0.9855 |
| AUC-ROC | 0.9987 |
| True Negatives (TN) | 99293 |
| False Positives (FP) | 2100 |
| False Negatives (FN) | 862 |
| True Positives (TP) | 100723 |
| True Positive Rate (TPR) / Recall | 0.9915 |
| False Positive Rate (FPR) | 0.0207 |