使用指针范式进行NER识别的两种经典方法,分别是BinaryPointer(SpanBert)和苏神的GlobalPointer,项目基于torch编写,提供可配置文件,项目已经提供了三种不同领域的数据,格式都一样,使用自己数据时请按照对应的数据格式整理好数据,并且按照配置要求填写参数,配置后直接运行main.py即可。
关于CRF范式的NER抽取实现请参考仓库里的另外一个项目基于Tensorflow2.3的NER任务项目。
2023年更新:仓库entity_extractor使用torch2把CRF范式还有指针范式进行了整合,并引入了更多tricks,是chatgpt时代以前用来打ner比赛用的,也可以使用和参考。
- torch==1.13.1
- tqdm==4.65.0
- transformers==4.27.3
其他环境见requirements.txt
| 日期 | 版本 | 描述 |
|---|---|---|
| 2020-08-23 | v1.0.0 | 初始仓库 |
| 2020-12-05 | v1.1.0 | 代码结构调整 |
| 2021-07-08 | v2.0.0 | 修改成BinaryPointer为Bert微调 |
| 2022-03-27 | v2.1.0 | 代码重构 |
| 2022-06-15 | v3.0.0 | 加入GlobalPointer方法、加入对抗、断点续训等 |
| 2022-06-17 | v3.0.1 | 转onnx时候tril的实现问题、加入批量测试 |
-
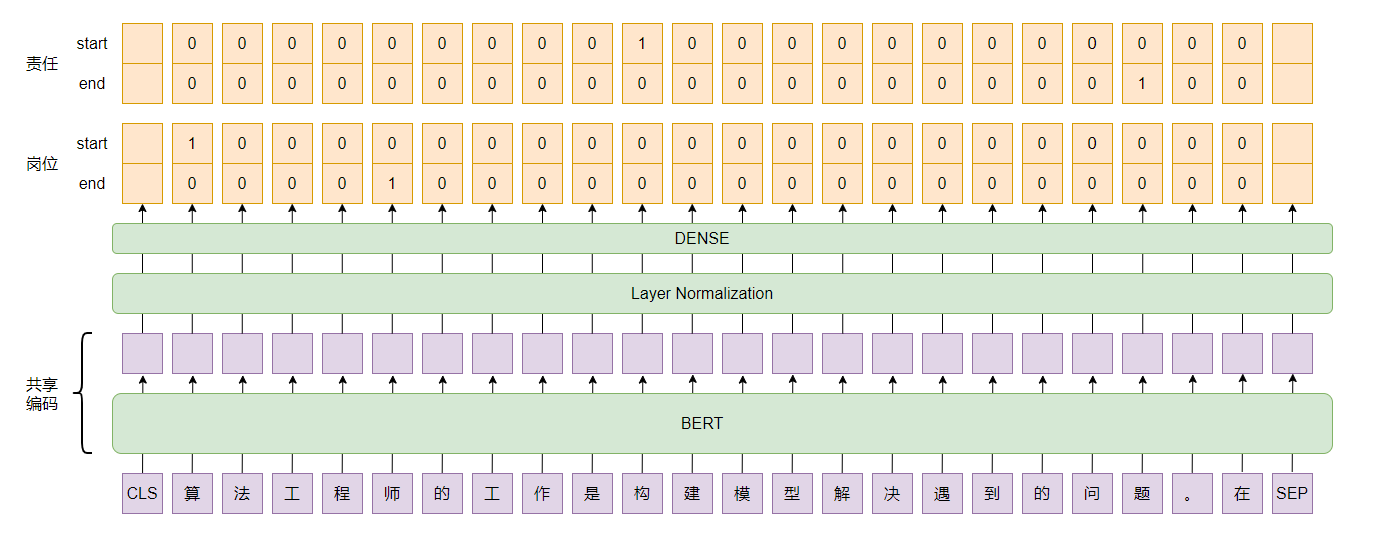
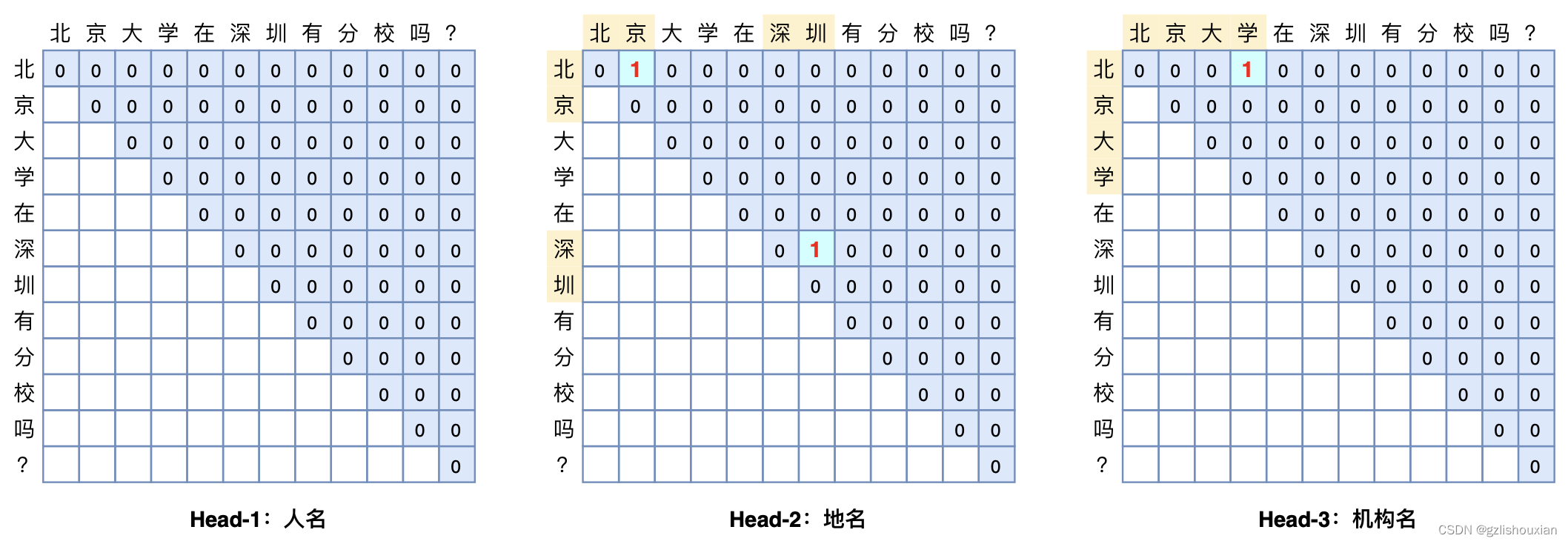
Binary Pointer
-
Global Pointer(图片来自于苏神科学空间)
完成环境安装后,需要在configure.py文件中修改配置
configure = {
# 训练数据集
'train_file': 'data/example_datasets2/train_data.json',
# 验证数据集
'dev_file': 'data/example_datasets2/dev_data.json',
# 没有验证集时,从训练集抽取验证集比例
'validation_rate': 0.15,
# 测试数据集
'test_file': '',
# 使用的模型
# bp: binary pointer
# gp: global pointer
'model_type': 'gp',
# 模型保存的文件夹
'checkpoints_dir': 'checkpoints/example_datasets2',
# 模型名字
'model_name': 'best_model.pkl',
# 类别列表
'classes': ['person', 'location', 'organization'],
# decision_threshold
'decision_threshold': 0.5,
# 是否使用苏神的多标签分类的损失函数,默认使用BCELoss
'use_multilabel_categorical_cross_entropy': True,
# 使用对抗学习
'use_gan': False,
# 目前支持FGM和PGD两种方法
# fgm:Fast Gradient Method
# pgd:Projected Gradient Descent
'gan_method': 'pgd',
# 对抗次数
'attack_round': 3,
# 是否进行warmup
'warmup': False,
# warmup方法,可选:linear、cosine
'scheduler_type': 'linear',
# warmup步数,-1自动推断为总步数的0.1
'num_warmup_steps': -1,
# 句子最大长度
'max_sequence_length': 200,
# epoch
'epoch': 50,
# batch_size
'batch_size': 16,
# dropout rate
'dropout_rate': 0.5,
# 每print_per_batch打印损失函数
'print_per_batch': 100,
# learning_rate
'learning_rate': 5e-5,
# 优化器选择
'optimizer': 'AdamW',
# 训练是否提前结束微调
'is_early_stop': True,
# 训练阶段的patient
'patient': 5,
}
修改mode为train
# 模式
# train:训练分类器
# interactive_predict:交互模式
# test:跑测试集
# convert2tf:将torch模型保存为tf框架的pb格式文件
# [train, interactive_predict, test, convert_onnx]
mode = 'train'
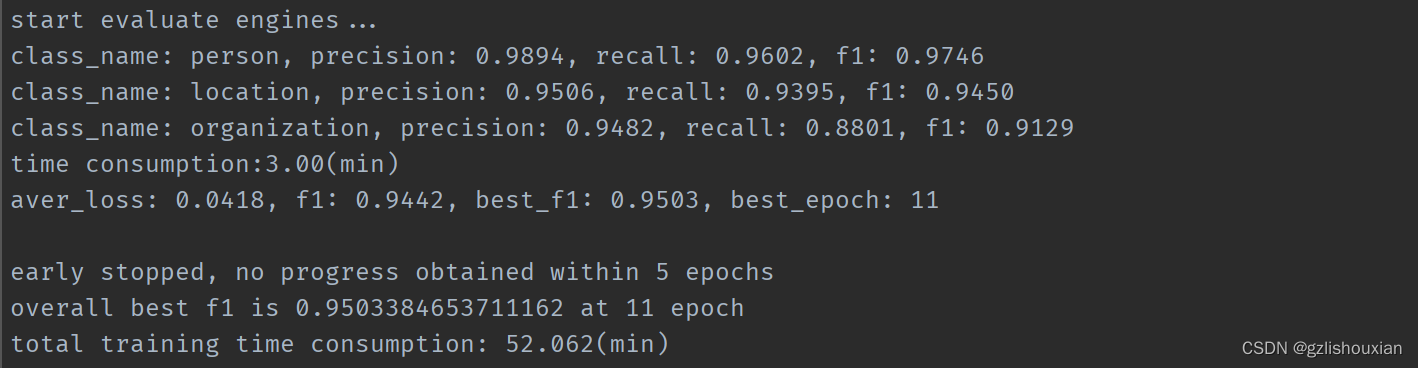
修改mode为interactive_predict
# 模式
# train:训练分类器
# interactive_predict:交互模式
# test:跑测试集
# convert_onnx:将torch模型保存为onnx格式文件
# [train, interactive_predict, test, convert2tf]
mode = 'interactive_predict'

公众号文章:基于首尾标注的实体抽取开源工具
苏神文章:科学空间-Efficient GlobalPointer:少点参数,多点效果
GitHub:Efficient-GlobalPointer-torch的torch实现