A comprehensive travel time dataset for the entire landmass of the world to the nearest town.
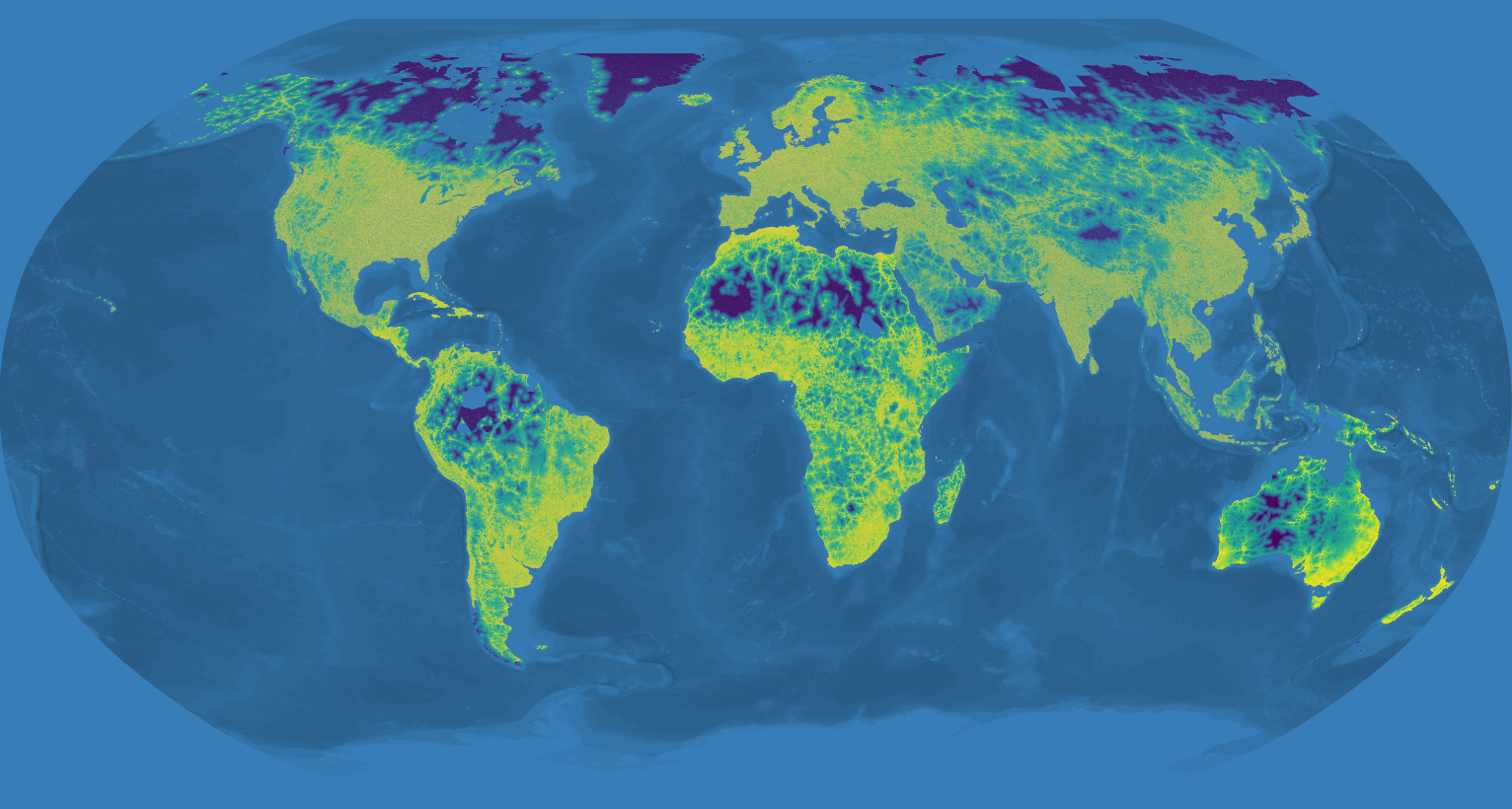
This project aims to create a dataset of actual traveltime from any area of the world to its nearest town. It uses OpenStreetMap and OSRM to calculate the traveltime by car from 6 million randomly distributed points on the globe's landmass and islands to their nearest town.
It is based on my work for the Rural Accessibility Map at the World Bank. It uses the same algorithm to calculate the travel time to the nearest POI (town in our case). But due to the sheer amount of data required and the limitations of Node and javascript it is as bare bones as possible to allow for as much memory and processing power as possible.
The towns are sourced from ... (TODO)
The 6 million points are randomly created by PostGIS's ST_GeneratePoints within the landmasses and islands from Natural Earth data. Due to the filesize limitations of Node these points have been divided into various continents.
Each continent has to be run separately and the resulting CSV files should be joined with awk 'FNR==1 && NR!=1{next;}{print}' *.csv > output.csv
- Download the OpenStreetMap data extract of the area you are interested in from geofabrik and put it in
osrm. The default settings expect the central-america-latest extract. - Prepare the OSRM routing graph. Note that preparing the entire world at once requires a lot of memory on your machine! Also the new OSRM seems to take a lot longer to generate the graphs :(. Beware: OSRM is really sensitive in its versions. Routing graphs created with one version of OSRM cannot be used by the node-binding with a different version. At the time of writing the working combination is v5.18.0:
cd osrm
docker run --rm -t -v $(pwd):/data osrm/osrm-backend:v5.18.0 osrm-extract -p /opt/car.lua /data/<osm data extract>.osm.pbf
docker run --rm -t -v $(pwd):/data osrm/osrm-backend:v5.18.0 osrm-contract /data/<osm data extract>.osrm
The docker version of OSRM is REALLY slow! If you are running it against entire continents it is better to build OSRM 5.8.0 locally and use osrm-extract and osrm-contract.
TODO: the output of the osrm docker has the wrong ownership, you need to chmod the files
Running is fairly easy - once you have the OSRM files setup. Currently only the data for Central America is in the repo. The other regions will follow soon.
nvm install 8npm installnode --max-old-space-size=4096 index.js <parameters>
The application takes up to three parameters. The region you are interested in (the name of the .osrm file), the name of the source file (the random points), the name of the destination file (the towns).
node index.jswill run with the default settings which means: it will look for the osrm filecentral-america-latest.osrm, the source filecentral-america-latest.json, the boundary filecentral-america-latest-boundary.geojsonand the default source filetowns.geojsonnode index.js europe-latestIt will use the region parameter to set the names for all the necessary files as such this will look for the osrm fileeurope-latest.osrm, the source fileeurope-latest.json, the boundary fileeurope-latest-boundary.geojsonand the default source filetowns.geojsonnode index.js asia-latest randompointsthis will look for the osrm fileasia-latest.osrm, the source filerandompoints.json, the boundary filerandompoints-boundary.geojsonand the default source filetowns.geojsonnode index.js africa-latest regularpoints mytowns.geojsonthis will look for the osrm fileafirca-latest.osrm, the source fileregularpoints.json, the boundary fileregularpoints-boundary.geojsonand the source filemytowns.geojson
The whole world-run was inspired by Bruno 's question on the original Rural Roads Accessibility (RRA) application I wrote for the Worldbank. It turned out that, apart from the difficulty of finding world wide data, the sheer size of the data was an issue for Node. In the end I created a stripped down version the would run one region of the world at a time. In the mean time I left DC and Developmentseed took over the development of RRA (rebranded Rural Accessibility Mapping - RAM) and created a solid database backed application out of it with a nice interface. They also cleaned up my code and brought it to modern day standards. I've taken their implementation of calculateETA and adapted for this usecase.