YOLO ("you only look once") is a popular algoritm because it achieves high accuracy while also being able to run in real-time, almost clocking 45 frames per second. A smaller version of the network, Fast YOLO, processes an astounding 155 frames per second while still achieving double the mAP of other real-time detectors. This algorithm "only looks once" at the image in the sense that it requires only one forward propagation pass through the network to make predictions. After non-max suppression, it then outputs recognized objects together with the bounding boxes.
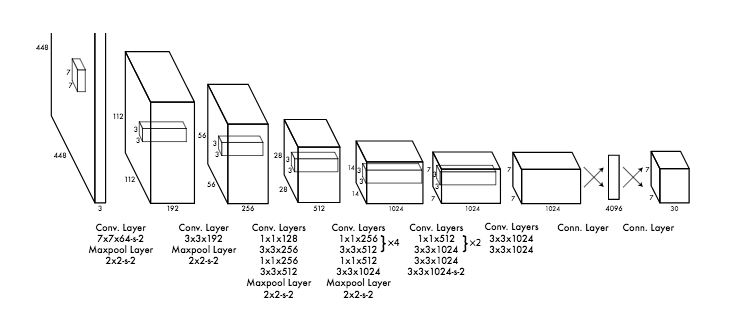
- The input is a batch of images of shape (m, 608, 608, 3)
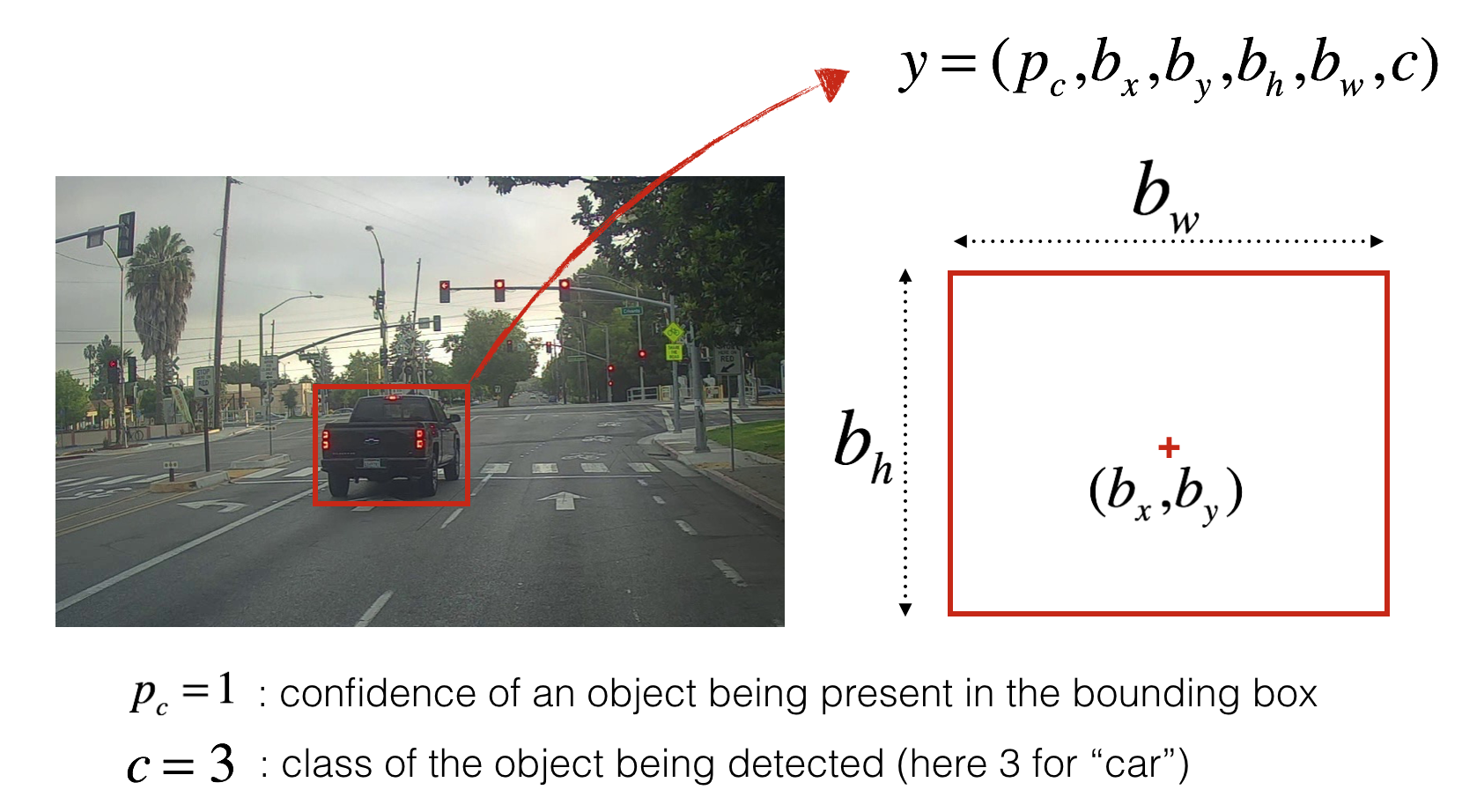
- The output is a list of bounding boxes along with the recognized classes. Each bounding box is represented by 6 numbers
(p_c, b_x, b_y, b_h, b_w, c)as explained above. If you expandcinto an 80-dimensional vector, each bounding box is then represented by 85 numbers. - The YOLO architecture if 5 anchor boxes are used is: IMAGE (m, 608, 608, 3) -> DEEP CNN -> ENCODING (m, 19, 19, 5, 85)
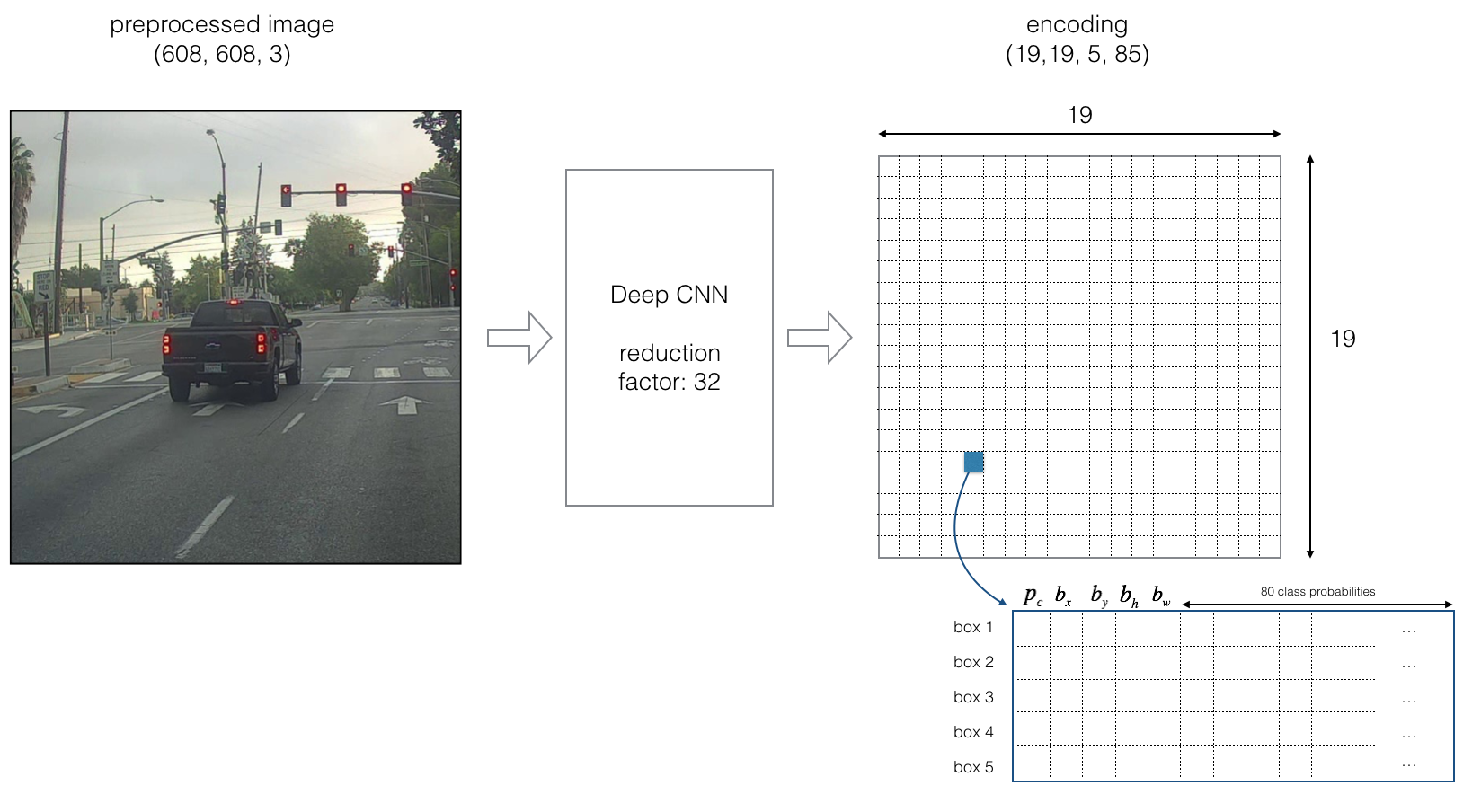
- Each cell gives you 5 boxes. In total, the model predicts: 19x19x5 = 1805 boxes just by looking once at the image (one forward pass through the network)! That is way too many boxes. Filter the algorithm's output down to a much smaller number of detected objects.
To reduce the number of detected objects, apply two techniques:
- Score-thresholding: Throw away boxes that have detected a class with a score less than the threshold
- Non-maximum suppression (NMS):

The steps to perform NMS are:
- Select the box that has the highest score.
- Compute its overlap with all other boxes, and remove boxes that overlap it more than iou_threshold.
- Iterate over all the boxes which have an overlap with the selected box until there are no more boxes with a lower score than the current selected box.
For example, suppose there are two boxes, box1 and box2. p(box1) = 0.9 p(box2) = 0.6 iou(box1, box2) = 0
Steps followed:
- Select box1 since it has the highest probability among the available scores.
- Since there's no overlap, box1 is selected.
- Iterating, box2 has the highest probability now. Select box2.
- End of the loop.
For a more detailed discussion, follow issue
Input image:

Output image:

- Training a YOLO model takes a very long time and requires a fairly large dataset of labelled bounding boxes for a large range of target classes. This project uses existing pretrained weights from the official YOLO website, and further processed using a function written by Allan Zelener.
- Complete model architecture can be found here
- Instructions to generate
yolo.h5file can be found here. Place that inmodel_datafolder - Input images can be found in
imagesdirectory. Corresponding output images can be found inoutdirectory.
{kind=link}
- Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi - You Only Look Once: Unified, Real-Time Object Detection (2015)
- Joseph Redmon, Ali Farhadi - YOLO9000: Better, Faster, Stronger (2016)
- Allan Zelener - YAD2K: Yet Another Darknet 2 Keras
- The official YOLO website (https://pjreddie.com/darknet/yolo/)