also available as a Hugging Face dataset
The goal of this project is to provide a German dataset for DPR model training. DPR (Dense Passage Retrieval) is one of the most important components of RAG applications. Based on this dataset, German document retrieval models can be trained.
The unique feature of this data set is that it contains not only training data for questions, but also imperative questions. An imperative question is a type of question that is phrased as a command or an instruction. Since there is a formal and informal form of address in German, both cases are included in the case of imperative questions.
The source of our data is the German Wikipedia or, to be more precise, the data set Cohere/wikipedia-22-12-de-embeddings from Cohere.
This data set is compiled and open sourced by Philip May of Deutsche Telekom.
- the train dataset contains 129,591 context passages
- the test dataset contains 5000 context passages
While we select the context passages we limit the length of them.
The length is measured with the tokenizer of deepset/gbert-base.
We limit the maximum token count to 270.
A histogram of the context token counts can be found below:
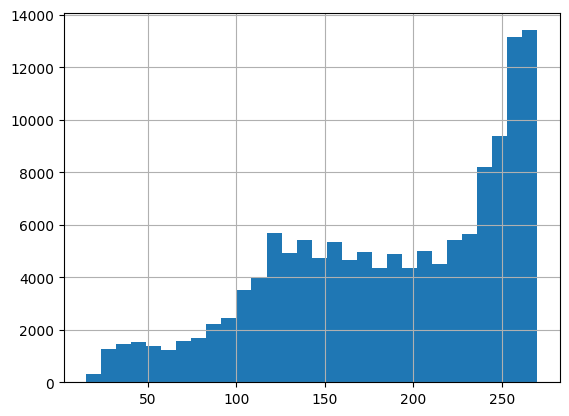
We are aware that there is a tendency to train and publish embedding models with ever increasing context lengths. However, we are of the opinion that the retrieval performance becomes too poor if the context is too large. We draw the line at 270 tokens. More on this topic, especially from Nils Reimers in the discussion of this LinkedIn post.
- the train dataset contains 757,167 questions
- the test dataset contains 29,186 questions
We have a maximum of 6 questions per context.
- the train dataset contains 762,076 formal imperative questions
- the test dataset contains 29,404 formal imperative questions
An imperative question is a type of question that is phrased as a command or an instruction. We have a maximum of 6 formal imperative questions per context.
- the train dataset contains 712,383 informal imperative questions
- the test dataset contains 27,548 informal imperative questions
An imperative question is a type of question that is phrased as a command or an instruction. We have a maximum of 6 informal imperative questions per context.
- training data:
data/wikipedia-22-12-de-train-data-v2.json.gz - test data:
data/wikipedia-22-12-de-test-data-v2.json.gz
- training data (129,591 context passages):
data/wikipedia-22-12-de-train-data.json.gz - test data (5,000 context passages):
data/wikipedia-22-12-de-test-data.json.gz
Below is a data loading example:
import gzip
import json
# load train data
with gzip.GzipFile("./data/wikipedia-22-12-de-train-data-v2.json.gz", "r") as f:
train_data = json.loads(f.read().decode('utf-8'))
assert len(train_data) == 129_591
# load test data
with gzip.GzipFile("./data/wikipedia-22-12-de-test-data-v2.json.gz", "r") as f:
test_data = json.loads(f.read().decode('utf-8'))
assert len(test_data) == 5_000This prompt was executed with GPT-4 and GPT-3.5-turbo.
Create a list of 6 questions in German language. \
It must be possible to answer the questions based on the given text. \
The question must not contain the word "and" (German "und").
The given text in German language:
{context}
The list of 6 different questions in German language without the word "and" (German "und"):
This prompt was executed with GPT-4.
Create a list of 6 short questions in imperative form. \
An imperative question is a type of question that is phrased as a command or an instruction. \
It must be possible to answer the imperative questions based on the given text. \
The imperative question must not contain the word "and" (German "und").
The given text in German language:
{context}
The list of 6 short questions in imperative form and German language:
Gegeben ist ein Satz im Imperativ. \
Dieser Satz benutzt die formelle Anrede "Sie". \
Wandle den Satz um, sodass er die informelle Anrede ohne "Sie" beinhaltet. \
Erkläre nichts weiter und gib nichts Zusätzliches aus.
Der Satz: Geben Sie das Geburtsjahr von Karl Heinz an.
Der Satz ohne das "Sie": Gebe das Geburtsjahr von Karl Heinz an.
Der Satz: Sagen Sie, welches Modell das iPhone 11 abgelöst hat.
Der Satz ohne das "Sie": Sage, welches Modell das iPhone 11 abgelöst hat.
Der Satz: {sentence}
Der Satz ohne das "Sie":
Copyright (c) 2023-2024 Philip May, Deutsche Telekom AG
Licensed under the MIT License (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License by reviewing the file LICENSE in the repository.
The Wikipedia texts are licensed under CC BY-SA 4.0 Deed by the corresponding authors of the German Wikipedia. The questions and imperative questions are copyright (CC BY-SA 4.0 Deed) by Philip May, Deutsche Telekom AG. Indication of changes:
- data source is the Cohere/wikipedia-22-12-de-embeddings dataset on Hugging Face Hub
- we took
wiki_id,titleandtext - did some normalization and filtering
- and merged the texts to an appropriate token count
- details can be found in the respective notebooks