Peacasso [Beta] is a UI tool to help you generate art (and experiment) with multimodal (text, image) AI models (stable diffusion). This project is still in development (see roadmap below).

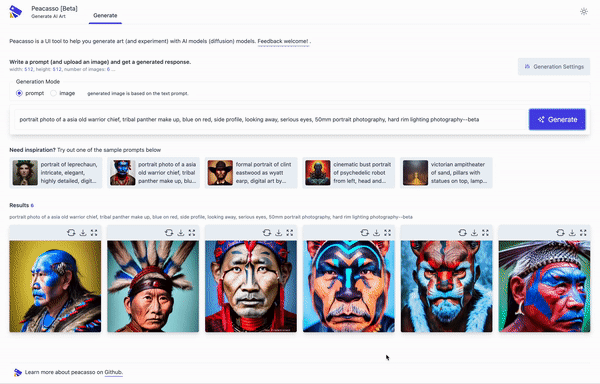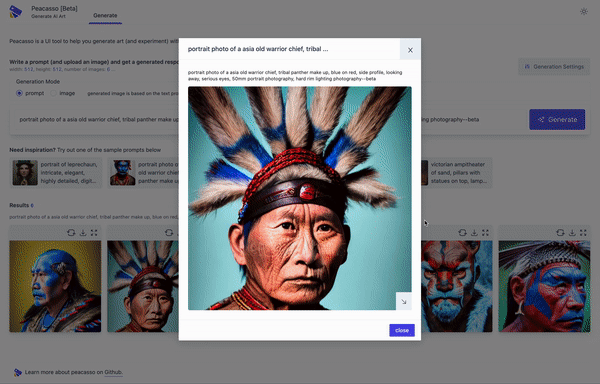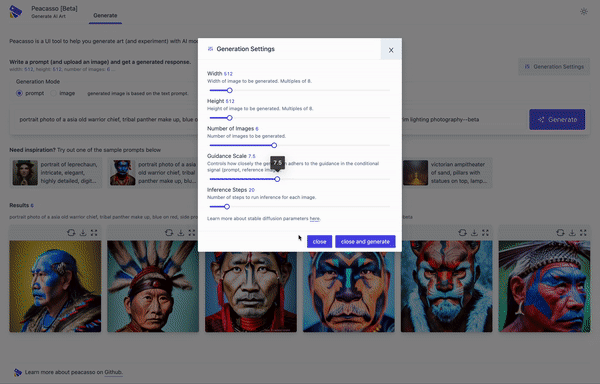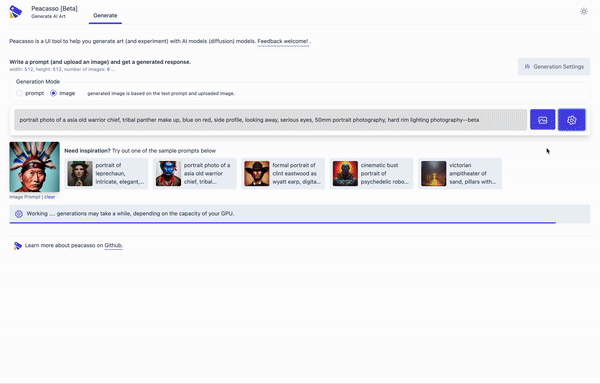
Because you deserve a nice UI and great workflow that makes exploring stable diffusion models fun! But seriously, here are a few things that make Peacasson interesting:
- Easy installation. Instead of cobbling together command line scripts, Peacasso provides a
pip installflow and a UI that supports a set of curated default operations. - UI with good defaults. The current implementation of Peacasso provides a UI for basic operations - text and image based prompting (+ inpainting), remixing generated images as prompts, model parameter selection, image download. Also covers the little things .. like light and dark mode.
- Python API. While the UI is the focus here, there is an underlying python api which will bake in experimentation features (e.g. saving intermediate images in the sampling loop, exploring model explanations etc. . see roadmap below).
Clearly, Peacasso (UI) might not be for those interested in low level code.
- Step 1: Verify Environment - Pythong 3.7+ and CUDA
Setup and verify that your python environment is
python 3.7or higher (preferably, use Conda). Also verify that you have CUDA installed correctly (torch.cuda.is_available()is true) and your GPU has about 7GB of VRAM memory.
Once requirements are met, run the following command to install the library:
pip install peacassoWant to stay on the bleeding edge of updates (which might be buggy)? Install directly from the repo:
git clone https://github.com/victordibia/peacasso.git
cd peacasso
pip install -e .Don't have a GPU, you can still use the python api and UI in a colab notebook. See this colab notebook for more details.
You can use the library from the ui by running the following command:
peacasso ui --port=8080Then navigate to http://localhost:8080/ in your browser. Note that you can also pass flags like --model (huggingface model) and --device (cuda, cpu, mps) to the command above to specify the model and device to use.
You can also use the python api by running the following command.
Note that each generation is parameterized by a GeneratorConfig object.
from peacasso.generator import ImageGenerator
from peacasso.datamodel import GeneratorConfig, ModelConfig
# model configuration
model_config: ModelConfig = ModelConfig(
device="cuda:0" , # device ..cpu, cuda, cuda:0
model="nitrosocke/mo-di-diffusion",
revision="main", # HF model branch
token=None, # HF_TOKEN here if needed
)
prompt = "victorian ampitheater of sand, pillars with statues on top, lamps on ground, by peter mohrbacher dan mumford craig mullins nekro, cgsociety, pixiv, volumetric light, 3 d render"
prompt_config = GeneratorConfig(
prompt=prompt,
num_images=3,
width=512,
height=512,
guidance_scale=7.5,
num_inference_steps=20,
return_intermediates=True, # return intermediate images during diffusion sampling
seed=6010691039
)
result = gen.generate(prompt_config)
result = gen.generate(prompt_config)
for i, image in enumerate(result["images"]):
image.save(f"image_{i}.png")
# result["intermediates"] contains the intermediate images
Visualizing intermediate images during the diffusion loop.
You can also interpolate between along several dimensions e.g., latents used in the diffusion process (based on seed, image, mask or combinations) and text embeddings used to guide the diffusion process. You can do this by modifying the application field in GeneratorConfig. See the colab notebook for more details.
The config below shows how to interpolate between two prompts and two latents (based on provided start and end images).
interpolation_config = GeneratorConfig(
prompt=start_prompt,
num_inference_steps=40,
seed=3167288399,
strength=1,
application={
"type": "interpolate",
"config": {"num_steps": 60,
"image": {"start": start_image, "end":end_image} ,
"prompt": {"start": start_prompt, "end": end_prompt}
}
})
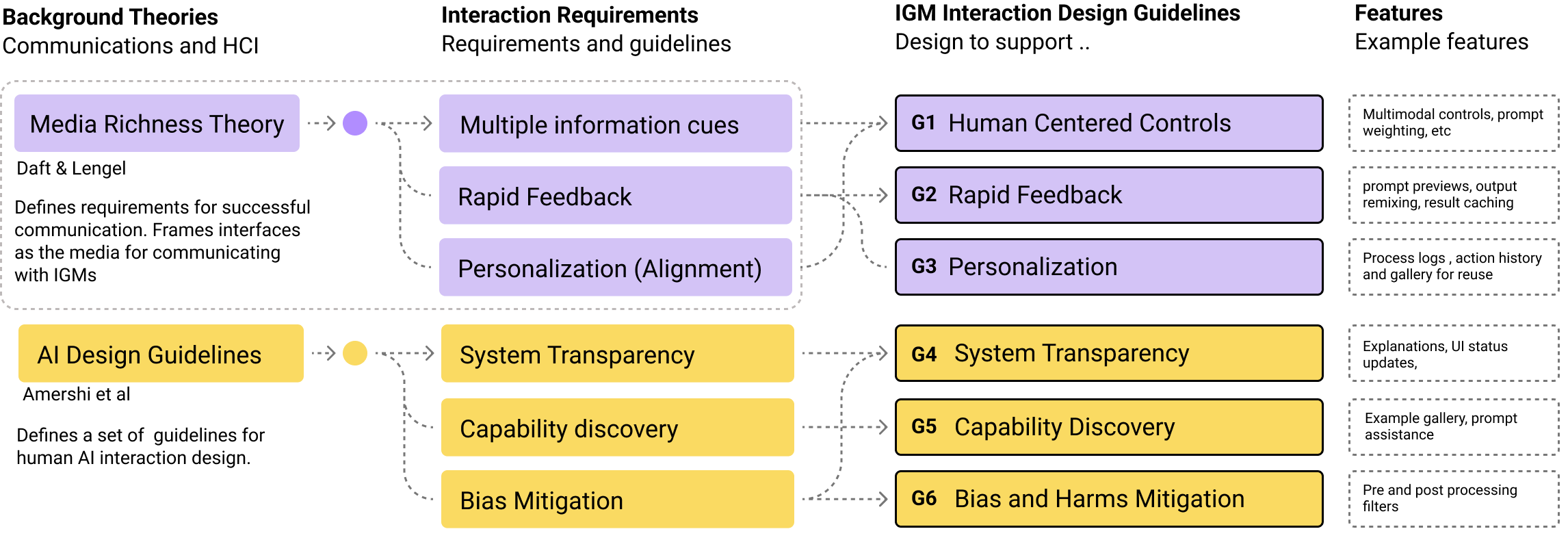
Features in Peacasso are being designed based on insights from communication theory 1 and also research on Human-AI interaction design 2. Learn more about the design and components in peacasso in the paper draft here.
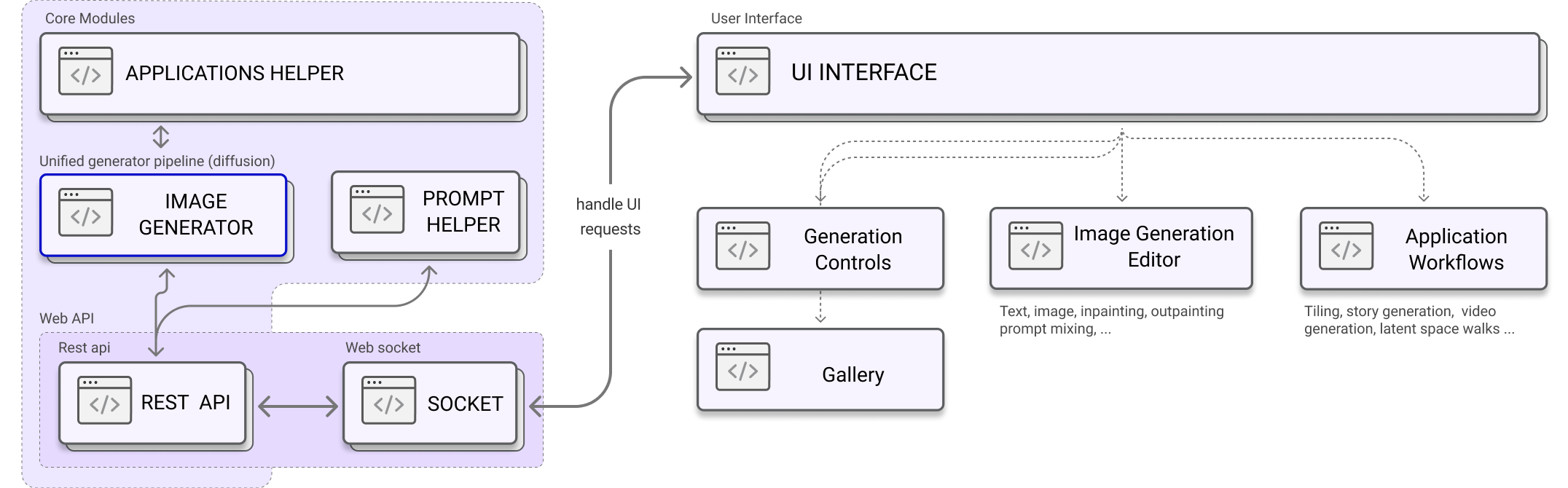
A general vision for the Peacasso architecture is shown below (parts of this are still being implemented):
- Command line interface
- UI Features. Query models with multiple parametrs
- Experimentation tools
- Save intermediate images in the sampling loop
- Weighted prompt mixing
- Prompt recommendation
- Curation/sharing experiment results
- Defined Workflows (e.g., tiles, composition etc.)
- Model explanations
This work builds on the stable diffusion model and code is adapted from the HuggingFace implementation. Please note the - CreativeML Open RAIL-M license associated with the stable diffusion model.
If you use peacasso for in your research or adopt the design guidelines used to build peacasso, please consider citing the paper as follows:
@misc{dibia2022peacasso,
title={Interaction Design for Systems that Integrate Image Generation Models: A Case Study with Peacasso},
author={Victor Dibia},
year={2022},
publisher={GitHub},
journal={GitHub repository},
primaryClass={cs.CV}
}Footnotes
-
Richard L Daft and Robert H Lengel. 1986. Organizational information require- ments, media richness and structural design. Management science ↩
-
Saleema Amershi, Dan Weld, Mihaela Vorvoreanu, Adam Fourney, Besmira Nushi, Penny Collisson, Jina Suh, Shamsi Iqbal, Paul N Bennett, Kori Inkpen, et al. 2019. Guidelines for human-AI interaction. In Proceedings of the 2019 chi conference on human factors in computing systems. ↩