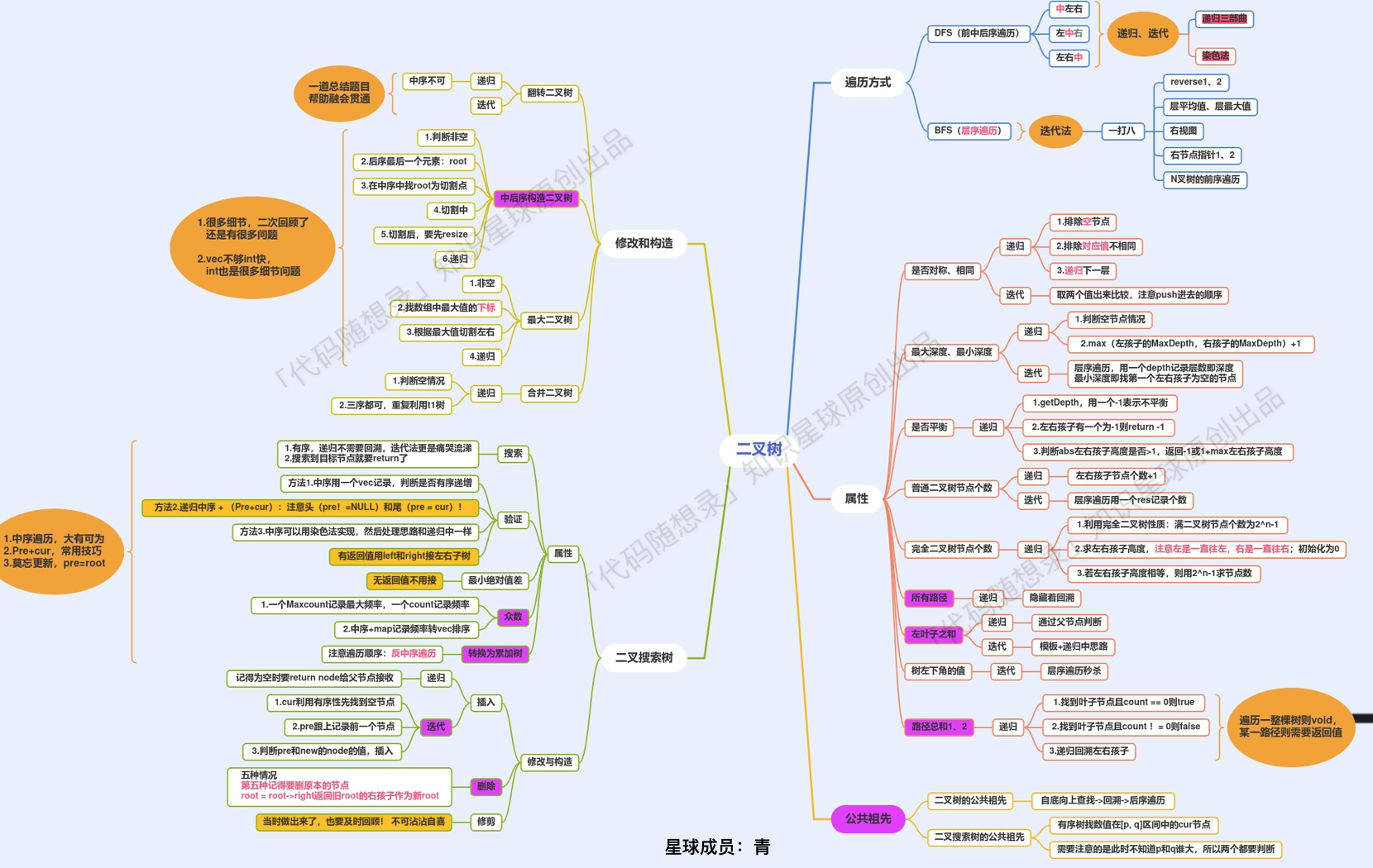
- todo
- 删除节点时,记得使用
free(node)释放节点空间 - 公共元素与公共节点不是同一概念,公共元素是指节点元素值相等,公共节点是指节点指针指向同一节点(即节点指针值相等)
- 对于有关2个元素值有序的线性表的问题,可以使用归并的思想
- 由于是单链表,所以每个node只有1个next指针,从第一个公共节点开始的所有节点都是公共节点
- 若只需判断是否有公共节点,只需分别遍历到2个单链表的最后一个节点并判断是否相同
- 若需求第一个公共节点,可以先分别求两个单链表的长度并求差值,对较长的单链表先遍历这个差值,再同步遍历同时判断next指针是否相等
- 不需要使用2个循环,只需记录两个链表的开始节点,每次匹配失败,通过开始节点恢复
- 队列是先进先出,栈是先进后出,可以通过2个栈1个负责进1个负责出来实现
- 进的时候就直接进,出的时候一开始将进的栈的元素全都push到另一个栈中,从而实现元素顺序反向,之后出的时候,若出的栈有元素,则直接出,否则将进的栈的元素全都push到出的栈之后再出元素
- 初步想法:使用2个队列,1个负责进栈和出栈,另一个辅助,关键在于维护进栈和出栈的队列中只有队尾的1个元素,其他元素按队列顺序保存在辅助队列中,当pop一个元素后,需将辅助队列的元素全部重新pop到主队列中,同时维护只有一个元素
- 优化:只使用1个队列,出栈时将出末尾元素都pop并重新push进入队列,值得注意的是top()只需返回队尾的元素back(),不应该使用pop出队列并重新入队列,否则多次top()会打乱顺序
- 显然使用栈实现,但有2种思路,将左括号入栈并将右括号与之匹配,或者将左括号对应的右括号入栈并看是否相等
- 字符都遍历完后,还需要判断栈是否为空
- 逆波兰表达式即后缀表达式,显然使用栈求解
- 需要注意的是,出栈2个操作数的顺序,后出栈的是左操作数
- 首先想到的是用队列维护当前窗口元素,但是如何维护最大值?
- 暴力求解,每次遍历k的值,时间复杂度O(nk)
- 由于每次只有一个元素的变化,似乎可以维护最大值和第二大值及其下标index。如果最大值移除且移入值小于第二大值,则第二大值更新为最大值,再遍历查找新的第二大值;如果最大值移除且移入值大于第二大值,则为最大值;如果最大值移除且移入值等于第二大值,则移入值为第二大值,原第二大值为最大值;如果有2个最大值,则应该index小的为最大值
- 使用最大堆维护最大值,移除元素时需要更新
- 使用双端队列维护最大值,双端队列元素的index递增,元素的值必须严格单调递减,因为,若相邻2个元素的下标为i和j,显然 i < j,只要i还在窗口中,j也一定还在窗口中,若nums[i] <= nums[j],则nums[i]必然不会为窗口中的最大值,应该删去
- 首先,记录不同元素的频率,O(n), O(n)
- 其次,使用排序算法对频率及其元素进行排序;似乎使用堆排序的复杂度较低,O(n log k), O(n);
- 也可以使用快排,不过我已经忘记什么是快排了🤣
- 要确定递归函数的参数和返回值; 要确定递归终止的条件; 要确定单层递归的逻辑。
- 有时可能需要写一个内部递归函数作为辅助
- 前序:
- 将当前节点(中节点)的值加入结果集中,依次加入不为空的右节点、左节点到栈中
- 中序:
- 空节点可以入栈
- 将当前节点(中节点,不为空)入栈,cur赋值为左节点,若当前节点为空,则cur赋值为栈弹出的节点,将值加入结果集,再cur赋值为右节点
- 相当于只处理中节点(值入结果集),左叶节点相当于左节点为空的中节点
- 后序:
- 法1:
- 前序的中左右顺序,调整为中右左顺序,再将结果集反向,变为左右中顺序,即后序
- 法2:
- 先直接遍历到最左叶节点的左节点(空节点)
- 用pre指针记录刚才处理的节点
- 若右节点为空或pre指针(刚才处理的节点)正好等于右节点,则处理当前节点(中节点)
- 法1:
- 栈中只存放非空节点
- 相当于统一只处理中节点,当前节点(中节点)放入栈中后紧接着要放入nullptr空节点作为标记,标志当前节点已访问,下次出栈时就直接处理,左右非空节点按照前中后序的顺序相应的入栈
- 使用队列辅助存储
- 处理每一层之前,使用int size记录当前层的节点数目
- 递归法、统一迭代法(前中后序)、广度优先搜索(层序遍历)都可以
- 可以使用递归法或迭代法
- 关键在于每次处理2个对称位置的节点,按对称顺序处理子节点(左左与右右、左右与右左)
- 首先,想到的是递归法(深度优先搜索)
- 还可以使用层序遍历,深度显然与层数直接相关
- 需要注意的是,最小深度是根节点到最近的叶子节点的路径的节点数,若左子树为空,则最小深度=1+右子树的最小深度
- 可以使用DFS(递归法)
- 也可以使用BFS(层序遍历),当第一次遇到叶子节点,就返回
- 若只当作普通二叉树,可以使用递归法:1+左子树节点数+右子树节点数,也可以使用迭代法,如层序遍历
- 若利用完全二叉树的性质,通过一直向左子树遍历、向右子树遍历来判断是不是满二叉树,如果是,则按照公式计算,如果不是,则使用递归:1+f(left)+f(right)
- 总体思路是自顶向下或自底向上
- 自顶向下若不记录已经计算过的值,则复杂度较高
- 自底向上可以使用后序遍历递归法
- 根节点到所有节点的路径:首先想到的是DFS,由于要记录经过路径的节点,所以使用前序遍历
- 可以使用递归法或迭代法。关键在于回溯,处理一个叶节点后需要回溯到父节点的路径。迭代法需要使用辅助栈记录每个节点的路径。
- 左叶子节点的判断需要从父节点开始判断,也可以通过引入应该bool参数判断该节点是否为左叶子节点
- dfs可以使用迭代法实现
- bfs可以使用迭代法实现
- 对于找最下一层最左边的值,首先想到的是层序遍历,可以每次记录一层中最左边的值,遍历结束后最后一个即为所求
- 也可以使用递归法,参数需要包含节点指针、当前深度,同时还要设置全局性的变量存储已知最大深度和最大深度最左边的节点值,需要保证优先搜索左边节点,前、中、后序都行
- 寻找是否存在一条由根节点到叶子节点的路径,使得节点值之和等于目标值
- 可以借助二叉树的所有路径部分,依次遍历所有路径并且节点值之和
- 中序遍历的顺序为:左中右,后序遍历的顺序为左右中,可以想象出,后序遍历的最后一个节点一定是根节点,由于没有重复元素,因此可以在中序遍历的数组中找到根节点,从而确定左子树和右子树的数组部分和大小,从而可以进行递归处理
- 此最大二叉树是递归定义的:找到数组中最大值作为根节点,然后左右子树分别使用根节点左右两边的数组递归构造
- 那么,如何寻找最大值很重要,由于原数组未排序,所以不能使用二分法,那么似乎只能一个一个比较
- 关键点在于如何同时同步遍历两个树
- 使用递归法较为简便,前中后序都可以
- 需要注意二叉搜索树BST的性质,左子树的值<根节点的值<右子树的值,递归定义
- 可以直接使用递归法
- 由于BST的性质导致节点值的顺序性,我们在确定搜索方向后就不需要再改变了(因为左子树的值<根节点的值<右子树的值),即不需要再回溯了,因此也可以使用迭代法通过while循环知道找到节点或nullptr
- 显然,根据BST的递归定义,可通过暴力搜索左子树最大值和右子树最小值进行判断并递归调用
- 进一步优化,暴力求最大最小的方法会重复遍历节点,递归时每次都求最大和最小,效率低,可以将递归函数设置为判断子树的值是不是在指定范围内,同时每次递归只比较一次根节点的值
- 根据BST的性质,则中序遍历的值一定是严格升序的,只需判断当前值是否大于之前的节点值
- 注意树是二叉搜索树,所以可以求 当前节点值-左子树最大值 和 右子树最小值-当前节点值 进行比较,并递归调用
- 还是可以利用中序遍历,先求出递增序列,然后遍历求最小绝对差就行
- 可以先中序遍历转换为升序数组 O(n),再遍历 O(n)
- 优化:无需转换为升序数组,直接在中序遍历时计数,再将map转换为vector,进行排序
- 优化:根据二叉搜索树的性质,中序遍历为非递减序列,我们只需在遍历时记录上一次的值,相等时计数+1,不等时结束上一个计数并与最大计数比较,开始当前计数
- 如果2个节点分别在当前节点的左右子树中,那么最近公共祖先就是当前节点;如果都在一个子树中,则可以递归判断该子树
- 如果先判断是否在子树中,再递归地在子树中搜索,复杂度太高
- 可以通过递归返回指针指示是否在子树中,同时通过后序遍历实现所谓的回溯(自底向上查找)
- 还可以先遍历一遍记录所有节点的父节点,从而实现像我们自己查找最近公共祖先那样自底向上查找
- 根据二叉搜索树的性质,只需当前节点值在p和q值之间就可以确定是最近公共祖先
- 递归比较大小进行插入
- 或者使用迭代法进行模拟
- 递归地找到要删除的节点,再将以此节点为根节点的树删除根节点后重构为二叉搜索树
- 递归法,遇到空节点直接返回nullptr;若当前节点值不在控制区间内,则返回对可能符合范围的左子树或右子树的递归调用;若当前节点值在控制区间内,则继续对左右儿子递归调用
- 由于二叉搜索树的有效性,可以直接使用迭代法进行处理
- 数组为升序,二叉搜索树要求为平衡
- 可以使用递归,每次选中间节点作为根节点,再对左右子树和左右子数组递归调用
- 累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
- 根据二叉搜索树的性质,可以按照由大到小的顺序即右、中、左的顺便遍历
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
- 由于每个数可以重复使用,所以每次递归元素范围不会缩减,而是通过元素之和大于给定值来终止
- 元素可以有重复,但每个元素只能用1次,同时结果中不能有重复
- 需要进行去重,可以考虑使用set或map等结构,但可能需要进行类型转换,可能超时
- 可以先对数组进行排序,然后使用bool数组进行标记,通过比较当前元素是否等于前一个元素同时前一个相等元素是否在当前路径中用过,来排除重复
- 输入字符串只包含数字,要求输出所有可能的有效IP地址
- 可以先根据输入字符串的长度确定对应4个整数的分割,再进行有效性判断
- 考虑包含重复元素值的集合,求幂集,
- 所求子集要去重,将过程用树表示,树层去重、树枝去重
- 给你一个整数数组 nums ,找出并返回所有该数组中不同的递增子序列,递增子序列中 至少有两个元素 。你可以按 任意顺序 返回答案。数组中可能含有重复元素,如出现两个整数相等,也可以视作递增序列的一种特殊情况。
- 与子集2不同,不能对数据进行排序,去重逻辑不同
- 要将树上的所有超过1个元素的节点加到结果中
- 去重逻辑:同一父节点的同层节点是否已经使用过该元素
- 需要使用一个数组used用于记录已使用的元素
- 有重复元素,所以需要去重,思路还是同一层和同一path上的重复元素的区别
- 按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
- 数独定义:每一行不能有相同数字,每一列不能有相同数字,每个3x3的块不能有相同数字
- 易错点:3x3判断中索引范围
- 可以优化的点:backtracking通过返回bool值结束递归,没有使用单独的索引和判断递归中止的语句,之后可以加上进行性能比较
- 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
- 子数组是数组中的一个连续部分。
- 此题使用贪心算法的关键在于如果当前连续子序列的和为负数,就不应该再使用当前子序列了,而是重新开始,因为负数和已经拉低了总和; 同时,不用担心重新开始子序列会导致漏掉可能的子序列,因为假如之前负数和的子序列存在非负的子子序列,要么已经记录了子子序列的最大和,要么是前半部为负数和(序列已经重新开始了,所以不存在这种情况)。
- 给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。 在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。 返回 你能获得的 最大 利润 。
- 基于贪心算法,谷底买峰顶卖
- 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
- 可以模拟人工判断时的暴力求解,从起始位置开始计算可以到达的最远位置,直到终止(其实就是贪心的算法)
- 一个重要的性质:只要有1条到达某个index的路径,那么该index之前的任何位置都可以到达,所以只需要关心可以到达的最远位置就行
- 返回到达 nums[n - 1] 的最小跳跃次数。生成的测试用例可以到达 nums[n - 1]。
- 根据直觉,从0位置开始每次选择跳到最远的距离,但是似乎有反例
- 由于肯定能到达n-1的位置,在之前的求是否可以到达n-1的算法中每次更新max_index时计数+1,但是似乎不行
- 根据随想录,贪心贪在步数什么时候+1,若终点在当前位置所辐射的范围内,则终止,否则步数+1
- 给你一个整数数组 nums 和一个整数 k ,按以下方法修改该数组:选择某个下标 i 并将 nums[i] 替换为 -nums[i] 。重复这个过程恰好 k 次。可以多次选择同一个下标 i 。以这种方式修改数组后,返回数组 可能的最大和 。
- 设数组中负数的个数为 num_neg,若 k<=num_neg,则取反最小的k个负数;若k>num_neg,则看数组中是否有0,若有0则先将所有负数取反,再将k剩余的次数用到0上,若没有0,则看k-num_neg的奇偶性,若k-num_neg为奇数,则选择最小的正数将其反转为负数,若k-num_neg为偶数,则不反转
- 随想录的思路也类似,不过我最开始没想到可以相对数组进行排序(题目没要求不能改变数组),排序后就很容易找到最小的k个负数
- 在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。给定两个整数数组 gas 和 cost ,如果你可以按顺序绕环路行驶一周,则返回出发时加油站的编号,否则返回-1 。如果存在解,则 保证 它是 唯一 的。
- 对于像
gas = [1,2,3,4,5], cost = [3,4,5,1,2]之类的输入,首先需要遍历找到一个开始的 gas[i]>=cost[i],之后每次计算gas之和与cost之和,始终保证gas之和>=cost之和就能保证能够正常行驶,但是时间复杂度为O(n^2) - O(n)的算法:如果在i处发生剩余的油量rest[i]<0,则说明i及之前的位置都不能作为起始点(反证法),将i+1作为新的起始点,同时记录总的剩余量,如果遍历一圈后总剩余量<0,则必然无法走一周。
- n 个孩子站成一排。给你一个整数数组 ratings 表示每个孩子的评分。你需要按照以下要求,给这些孩子分发糖果:每个孩子至少分配到 1 个糖果。相邻两个孩子评分更高的孩子会获得更多的糖果。请你给每个孩子分发糖果,计算并返回需要准备的 最少糖果数目 。
- 随想录的思路:若孩子i右边的孩子i+1评分比i大,则糖果数candy[i+1]必定>candy[i],由于要求最少糖果数目,所以相邻取candy[i+1]=candy[i];同时从左到右与从右到左都分别有连续的评分关系,所以需要分别从右到左和从左到右遍历,初始化时将每个孩子的糖果数都初始化为1;同时,第二次遍历时,糖果数目不仅要取candy[i+1]+1和candy[i]的最大值,以保证即大于右边又大于左边
- 在柠檬水摊上,每一杯柠檬水的售价为 5 美元。顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。注意,一开始你手头没有任何零钱。给你一个整数数组 bills ,其中 bills[i] 是第 i 位顾客付的账。如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
- 10元需要有至少1张5元,20元需要1张10元1张5元 或 3张5元
- 有一些球形气球贴在一堵用 XY 平面表示的墙面上。墙面上的气球记录在整数数组 points ,其中points[i] = [xstart, xend] 表示水平直径在 xstart 和 xend之间的气球。你不知道气球的确切 y 坐标。一支弓箭可以沿着 x 轴从不同点 完全垂直 地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被 引爆 。可以射出的弓箭的数量 没有限制 。 弓箭一旦被射出之后,可以无限地前进。给你一个数组 points ,返回引爆所有气球所必须射出的 最小 弓箭数 。
- 给定一个区间的集合 intervals ,其中 intervals[i] = [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。
- 首先,需要给出重叠的定义:对于[start_i, end_i]和[start_j, end_j], 若start_j < end_i && end_j > start_i 或者是i和j对调,则两个intervals重叠。若按照此定义,判断重叠时则需要进行i和j对调的两种比较,因此可以想到在比较判断之前先通过interval的左边界或右边界进行排序,那么在对2个intervals进行比较时就可以少去1个判断。
- 假设对左边界进行排序,就会存在左边界相等右边界不等的情况,根据贪心的思想,此时要尽可能使得右边界变小,从而到最终的右边界的剩余空间就越大,由于intervals已经进行了排序,所以剩余空间越大,可容纳的不重叠区域的个数就越多
- 给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是 s 。返回一个表示每个字符串片段的长度的列表。
- 如果一个字母出现在index为i和j的位置,那么[i, j]必定包含在一个片段中,那么可以先记录26个字母最开始和结束的位置,然后进行片段的划分——可分为3种情况,该字母没有出现、只出现1次和出现2次及以上,由此得到的若干个区间,重叠的区间合并为一个大区间,类似于求无重叠区域的问题,但是右边界要求较大值
- 进一步优化,只需记录每个字母最后出现的位置,对于每一个片段,若index达到当前片段的最右边界,则说明片段结束
- 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。区间 [1,4] 和 [4,5] 可被视为重叠区间。
- 可以直接使用划分字母区间问题中最初使用方法,先排序,再遍历,记录右边界最大值用于判断是否重叠
- 当且仅当每个相邻位数上的数字 x 和 y 满足 x <= y 时,我们称这个整数是单调递增的。给定一个整数 n ,返回 小于或等于 n 的最大数字,且数字呈 单调递增 。
- 对于一个数字abc,单调递增需要满足a<=b<=c,可以从右向左进行比较,若b > c,则需要b减小或c增大,但是不能只是c增大因为要求小于等于n的最大数字,所以可以使得b只减小1而c增大至9,同时c右边的所有数字都要增大至9,以达到最大值
- 若每次不满足递增条件时都进行变大至9,则复杂度为 O(d^2),可以用mark记录最左边的不满足递增条件的位置,然后一次性将mark右边所有的数字都变为9,复杂度可以降低为 O(d)
- 给定一个二叉树,我们在树的节点上安装摄像头。节点上的每个摄影头都可以监视其父对象、自身及其直接子对象。计算监控树的所有节点所需的最小摄像头数量。
- 根据贪心的思想,应该自下而上从叶子节点开始遍历二叉树,摄像头应该放在叶子节点的父节点上,可以使用中序遍历;对于如何判断要不要放置摄像头,需要判断节点的状态,对于节点的状态有3种:放了摄像头、被摄像头覆盖、当前还未被覆盖,空节点的状态可以等效于被摄像头覆盖的节点的状态
- 斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:F(0) = 0,F(1) = 1,F(n) = F(n - 1) + F(n- 2),其中 n > 1,给定 n ,请计算 F(n) 。
- 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
- 构造dp数字 dp[n],表示有多少种方法爬到n阶楼梯; 递推公式:dp[n]=dp[n-1]+dp[n-2],表示必定是通过爬1个台阶或2个台阶到达n阶楼梯; 初始化:dp[0]=1, dp[1]=1
- 给你一个整数数组 cost ,其中 cost[i] 是从楼梯第 i 个台阶向上爬需要支付的费用。一旦你支付此费用,即可选择向上爬一个或者两个台阶。你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。请你计算并返回达到楼梯顶部的最低花费。
- dp数组:dp[n]=min{dp[n-1]+cost[n-1], dp[n-2]+cost[n-2]} 初始化:dp[0]=0, dp[1]=0
- 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。问总共有多少条不同的路径?
- dp数组:dp[m, n] = dp[m-1, n] +dp[m, n-1] 初始化:dp[m, 1] = 1, dp[1, n] = 1
- 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish”)。现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?网格中的障碍物和空位置分别用 1 和 0 来表示。
- dp数组:dp[m, n] = dp[m-1, n] +dp[m, n-1],如果obstacleGrid[m, n]==1,则dp[m, n]=0
- 给定一个正整数 n ,将其拆分为 k 个 正整数 的和( k >= 2 ),并使这些整数的乘积最大化。返回 你可以获得的最大乘积 。
- dp[n] = max{ dp[n], max{i*(n-i), i*dp[n-i] }} for i=1 to n-1 初始化:dp[1]=0, dp[2]=1
- 给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
- dp[n] = 1 * dp[n-1] + dp[1] * dp[n-2] + ... + dp[i-1] * dp[n-i] +...+ dp[n-1]*1 初始化:dp[0]=1
- 小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。他需要带一些研究材料,但是他的行李箱空间有限。这些研究材料包括实验设备、文献资料和实验样本等等,它们各自占据不同的空间,并且具有不同的价值。 小明的行李空间为 N,问小明应该如何抉择,才能携带最大价值的研究材料,每种研究材料只能选择一次,并且只有选与不选两种选择,不能进行切割。
- 输入描述 第一行包含两个正整数,第一个整数 M 代表研究材料的种类,第二个正整数 N,代表小明的行李空间。 第二行包含 M 个正整数,代表每种研究材料的所占空间。 第三行包含 M 个正整数,代表每种研究材料的价值。
- 输出描述 输出一个整数,代表小明能够携带的研究材料的最大价值。
- 显然对应0-1背包问题,使用动态规划
- 给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
- 若两个子集元素和相等,则子集元素和为数组总和的一半
- 可以使用回溯法暴力求解,但是会超时
- 使用动态规划,即求是否能选若干个数使得元素和为指定数
- 有一堆石头,用整数数组 stones 表示。其中 stones[i] 表示第 i 块石头的重量。 每一回合,从中选出任意两块石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 x <= y。那么粉碎的可能结果如下: 如果 x == y,那么两块石头都会被完全粉碎; 如果 x != y,那么重量为 x 的石头将会完全粉碎,而重量为 y 的石头新重量为 y-x。 最后,最多只会剩下一块 石头。返回此石头 最小的可能重量 。如果没有石头剩下,就返回 0。
- 可能的思路:先从小到大排序,依次尾部最大减去头部最小,得到新的序列;再排序,递归进行,直到只有1个或0个元素(!!!错误!!!)
- 可以将问题转化为将数组分为2个子集,使得这2个子集的元素和之差尽可能小,stones = S1 + S2,| S1-S2 | = | stones-2S2|,即使得子集的元素之和尽可能接近 总和的一半,从而问题就转化为上一个求分割等和子集的问题
- 给你一个非负整数数组 nums 和一个整数 target 。 向数组中的每个整数前添加 '+' 或 '-' ,然后串联起所有整数,可以构造一个 表达式 : 例如,nums = [2, 1] ,可以在 2 之前添加 '+' ,在 1 之前添加 '-' ,然后串联起来得到表达式 "+2-1" 。 返回可以通过上述方法构造的、运算结果等于 target 的不同 表达式 的数目。
- 将nums分为2组A和B,sum = A + B,A - B = sum - 2 * B = target,B = (sum - target)/2,所以问题转化为求元素之和为(sum-target)/2的子数组的个数,类似于0-1背包问题,但是是求可能解的个数
- 可以使用回溯算法中组合总和问题的暴力求解
- 也可以使用动态规划,dp[j] 此时的含义是装满容量为j的背包的方法的数目
- 给你一个二进制字符串数组 strs 和两个整数 m 和 n 。 请你找出并返回 strs 的最大子集的长度,该子集中 最多 有 m 个 0 和 n 个 1 。 如果 x 的所有元素也是 y 的元素,集合 x 是集合 y 的 子集 。
- dp[i, m, n] = max{ dp[i-1, m, n], dp[i-1, m-strs[i]中0的个数, n-strs[i]中1的个数]+1 } 初始化:dp[0, m, n] = 0
- 题目描述 小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。他需要带一些研究材料,但是他的行李箱空间有限。这些研究材料包括实验设备、文献资料和实验样本等等,它们各自占据不同的重量,并且具有不同的价值。 小明的行李箱所能承担的总重量为 N,问小明应该如何抉择,才能携带最大价值的研究材料,每种研究材料可以选择无数次,并且可以重复选择。 输入描述 第一行包含两个整数,N,V,分别表示研究材料的种类和行李空间 接下来包含 N 行,每行两个整数 wi 和 vi,代表第 i 种研究材料的重量和价值 输出描述 输出一个整数,表示最大价值。
- 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带符号整数。
- 类似于完全背包问题,不过是要求可能的组合数。 dp[i, j] += d[i-1, j-coins[i]] 初始化:dp[i, 0] = 1
- 给你一个由 不同 整数组成的数组 nums ,和一个目标整数 target 。请你从 nums 中找出并返回总和为 target 的元素组合的个数。 题目数据保证答案符合 32 位整数范围。 示例 1: 输入:nums = [1,2,3], target = 4 输出:7 解释: 所有可能的组合为: (1, 1, 1, 1) (1, 1, 2) (1, 2, 1) (1, 3) (2, 1, 1) (2, 2) (3, 1) 请注意,顺序不同的序列被视作不同的组合。 示例 2: 输入:nums = [9], target = 3 输出:0
- 说是组合数实际要求是求排列数
- 使用动态规划,for循环外层遍历背包空间、内层遍历不同物品
- 题目描述 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬至多m (1 <= m < n)个台阶。你有多少种不同的方法可以爬到楼顶呢? 注意:给定 n 是一个正整数。 输入描述 输入共一行,包含两个正整数,分别表示n, m 输出描述 输出一个整数,表示爬到楼顶的方法数。 输入示例 3 2 输出示例 3 提示信息 数据范围: 1 <= m < n <= 32; 当 m = 2,n = 3 时,n = 3 这表示一共有三个台阶,m = 2 代表你每次可以爬一个台阶或者两个台阶。 此时你有三种方法可以爬到楼顶。 1 阶 + 1 阶 + 1 阶段 1 阶 + 2 阶 2 阶 + 1 阶
- dp秒解
- 给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。 计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。 你可以认为每种硬币的数量是无限的。
- 由于每种硬币数量是无限的,所以是完全背包问题。要求的是最少的硬币数目,递推公式 dp[j] = min { dp[j-coins[i]]+1, dp[j]} 初始化:dp[0]=0,因为是求最小数目,所以其他元素初始化为较大值,可以是amount+1
- 由于本题是求最小数目,而不是求组合数或排列数,所以2层循环遍历的顺序没有关系
- 给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。 完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
- 由于1是完全平方数,所以输入的任意正整数都有合理的结果
- 对应于完全背包问题,要求物品数目最小,与之前的零钱兑换问题类似,dp[j] = min { dp[j-square_nums]+1, dp[j]}, dp[0]=0, dp[i]=n+1(i!=0)
- 给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。 注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
- 对应于完全背包问题,每个单词可以使用多次。
- if(endWith(j, wordDict[i])) { dp[j] = dp[j-worDict[i]] || dp[j];} else dp[j]=dp[j];
- 题目描述 你是一名宇航员,即将前往一个遥远的行星。在这个行星上,有许多不同类型的矿石资源,每种矿石都有不同的重要性和价值。你需要选择哪些矿石带回地球,但你的宇航舱有一定的容量限制。 给定一个宇航舱,最大容量为 C。现在有 N 种不同类型的矿石,每种矿石有一个重量 w[i],一个价值 v[i],以及最多 k[i] 个可用。不同类型的矿石在地球上的市场价值不同。你需要计算如何在不超过宇航舱容量的情况下,最大化你所能获取的总价值。 输入描述 输入共包括四行,第一行包含两个整数 C 和 N,分别表示宇航舱的容量和矿石的种类数量。 接下来的三行,每行包含 N 个正整数。具体如下: 第二行包含 N 个整数,表示 N 种矿石的重量。 第三行包含 N 个整数,表示 N 种矿石的价格。 第四行包含 N 个整数,表示 N 种矿石的可用数量上限。 输出描述 输出一个整数,代表获取的最大价值。 输入示例 10 3 1 3 4 15 20 30 2 3 2 输出示例 90 提示信息 数据范围: 1 <= C <= 10000; 1 <= N <= 10000; 1 <= w[i], v[i], k[i] <= 10000;
- 你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。 给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
- dp[j] = max{ dp[j-1], value[j]+dp[j-2]}
- 你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警 。 给定一个代表每个房屋存放金额的非负整数数组,计算你 在不触动警报装置的情况下 ,今晚能够偷窃到的最高金额。
- 第一个房间和最后一个房间不能同时选,所以转化为求2个子问题 nums[0:n-1] 和 nums[1:n]
- 小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。 除了 root 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果 两个直接相连的房子在同一天晚上被打劫 ,房屋将自动报警。 给定二叉树的 root 。返回 在不触动警报的情况下 ,小偷能够盗取的最高金额 。
- 对根节点有2种选择,若偷根节点,则递归选择grandchildren节点;否则递归选择children节点,但是会超时,可以使用记忆化递归将已经计算过的存储下来
- 如果使用动态规划,需要重新构造一个辅助递归函数,返回值为偷当前节点和不偷当前节点的最大钱数的数组,dp数组实际上就是大小为2的返回值数组
- 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。 返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
- 看题目的意思是只能一天买入之后的某一天卖出。
- 直接做就是记录已遍历元素中最小值,只用当前值减去记录的最小值与之前记录的差值比较大小,这样就保证了得到的差值一定是右边的值减去左边的值,时间复杂度O(n),空间复杂度O(1)
- 动态规划则不容易想出来,对于每一个天数,某天有持有股票和不持有股票2种可能的状态,用 dp[j][0] 和 dp[j][1] 表示,若某天不持有股票,可能是之前就已经不持有股票了或者是正好这一天把股票卖了,dp[j][0] = max{ dp[j-1][0], dp[j-1][1]+prices[i]}; 若某天持有股票,可能是之前就持有股票了或正好这一天买入股票 dp[j][1] = max {dp[j-1][1], -prices[i]},注意是 -prices[i] 而不是 dp[j-1][0]-prices[i],那样就变成了可以多次买入卖出;初始化,dp[0][0]=0, dp[0][1]=-prices[0];自己在脑海里过一遍,大概是求最大-最小
- 给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。 在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。 返回 你能获得的 最大 利润 。
- 题目修改为可以多次买入和卖出。
- 贪心算法:1次买入卖出可以分解为多个相邻2天的分别买入和卖出,因此贪心地看每天的价格是否比前一天高,即差值大于0就要前一天买入今天卖出。
- 动态规划:dp[j][0] = max{ dp[j-1][0], dp[j-1][1]+prices[i]}, dp[j][1] = max{dp[j-1][1], dp[j-1][0]-prices[i]},唯一的区别就在于某天持有可能是前一天不持有的价值加上今天再买入,即之前几天可能已经进行了买入卖出
- 给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。 设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。 注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
- 注意到,如果再某天先卖出后买入,等效于没有进行买卖股票,因此如果进行两笔交易则这两笔交易的买卖天数范围没有交集
- 思路:可以在dp数组中再添加一个维度,表示已经完成的交易数。 第j天没有持有股票且已完成0个交易:dp[j][0][0] = dp[j-1][0][0]; 第j天没有持有股票且已完成1个交易:dp[j][0][1] = max{ dp[j-1][0][1], dp[j-1][1][0]+prices[j] }; 第j天没有持有股票且已完成2个交易:dp[j][0][2] = max{ dp[j-1][0][2], dp[j-1][1][1]+prices[j] }; 第j天持有股票且已完成0个交易:dp[j][1][0] = max{dp[j-1][1][0], dp[j-1][0][0]-prices[j]}; 第j天持有股票且已完成1个交易:dp[j][1][1] = max{ dp[j-1][1][1], dp[j-1][0][1]-prices[j] }; 第j天持有股票且已完成2个交易:dp[j][1][2] = max{ dp[j-1][1][2], dp[j-1][0][2]-prices[j] }; 初始化:dp[0][0][0]=0, dp[0][1][0]=-prices[0], dp[0][0][1]=dp[0][1][1]=dp[0][0][2]=dp[0][1][2]=<无效值>,
- 给你一个整数数组 prices 和一个整数 k ,其中 prices[i] 是某支给定的股票在第 i 天的价格。 设计一个算法来计算你所能获取的最大利润。你最多可以完成 k 笔交易。也就是说,你最多可以买 k 次,卖 k 次。 注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
- 可以设置:没有买入卖出、第一次买入、第一次卖出、... 、第k次卖出共2*k+1种状态,二维数组表示天数和状态。。。其余的都类似
- 给定一个整数数组prices,其中第 prices[i] 表示第 i 天的股票价格 。 设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票): 卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)。 注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
- dp[j][0] = max{dp[j-1][0], dp[j-1][1]+prices[j]} dp[j][1] = max{dp[j-1][1], dp[j-2][0]-prices[j]} 初始化:dp[0][0]=0, dp[0][1]=-prices[0], dp[1][0]=max{dp[0][0], dp[0][1]+prices[1]}, dp[1][1]=max{dp[0][1], -prices[1]}
- 给定一个整数数组 prices,其中 prices[i]表示第 i 天的股票价格 ;整数 fee 代表了交易股票的手续费用。 你可以无限次地完成交易,但是你每笔交易都需要付手续费。如果你已经购买了一个股票,在卖出它之前你就不能再继续购买股票了。 返回获得利润的最大值。 注意:这里的一笔交易指买入持有并卖出股票的整个过程,每笔交易你只需要为支付一次手续费。
- 由于每一笔交易都需支付手续费,所以不存在某天卖出又买入的情况,因为 b-a-fee + c-b-fee < c-a。添加了手续费这一项,也就意味着在递推公式中卖出股票时要多减去一次手续费。
- 贪心算法更快:我们用 buy 表示在最大化收益的前提下,如果我们手上拥有一支股票,那么它的最低买入价格是多少。在初始时,buy 的值为 prices[0] 加上手续费 fee。那么当我们遍历到第 i (i>0) 天时: 如果当前的股票价格 prices[i] 加上手续费 fee 小于 buy,那么与其使用 buy 的价格购买股票,我们不如以 prices[i]+fee 的价格购买股票,因此我们将 buy 更新为 prices[i]+fee; 如果当前的股票价格 prices[i] 大于 buy,那么我们直接卖出股票并且获得 prices[i]−buy 的收益。但实际上,我们此时卖出股票可能并不是全局最优的(例如下一天股票价格继续上升),因此我们可以提供一个反悔操作,看成当前手上拥有一支买入价格为 prices[i] 的股票,将 buy 更新为 prices[i]。这样一来,如果下一天股票价格继续上升,我们会获得 prices[i+1]−prices[i] 的收益,加上这一天 prices[i]−buy 的收益,恰好就等于在这一天不进行任何操作,而在下一天卖出股票的收益; 对于其余的情况,prices[i] 落在区间 [buy−fee,buy] 内,它的价格没有低到我们放弃手上的股票去选择它,也没有高到我们可以通过卖出获得收益,因此我们不进行任何操作。 上面的贪心思想可以浓缩成一句话,即当我们卖出一支股票时,我们就立即获得了以相同价格并且免除手续费买入一支股票的权利。在遍历完整个数组 prices 之后之后,我们就得到了最大的总收益。
- 给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
- 首先,要确定dp[i]的含义,dp[i]应是以nums[i]结尾的最长子序列的长度,这样就可以直接比较相邻的元素来进行递推了。
if(nums[i]>nums[j]){
dp[i]=std::max(dp[i], dp[j]+1);
}- 给定一个未经排序的整数数组,找到最长且 连续递增的子序列,并返回该序列的长度。 连续递增的子序列 可以由两个下标 l 和 r(l < r)确定,如果对于每个 l <= i < r,都有 nums[i] < nums[i + 1] ,那么子序列 [nums[l], nums[l + 1], ..., nums[r - 1], nums[r]] 就是连续递增子序列。
if(nums[i]>nums[i-1]){
dp[i]=std::max(dp[i], dp[i-1]+1);
}- 给两个整数数组 nums1 和 nums2 ,返回 两个数组中 公共的 、长度最长的子数组的长度 。
- 经典的动态规划问题,之前算法课上讲过,但竟然忘了😂
if(nums[i]==nums[j]) {
dp[i][j]=dp[i-1][j-1]+1;
}- dp[i][j]代表必须分别以nums1[i]与nums2[j]结尾的最长子数组的长度
- 给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。 一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。 例如,"ace" 是 "abcde" 的子序列,但 "aec" 不是 "abcde" 的子序列。 两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
if(nums[i]==nums[j]) {
dp[i][j]=dp[i-1][j-1]+1;
}else{
dp[i][j]=std::max(dp[i][j-1], dp[i-1][j]);
}- 在两条独立的水平线上按给定的顺序写下 nums1 和 nums2 中的整数。 现在,可以绘制一些连接两个数字 nums1[i] 和 nums2[j] 的直线,这些直线需要同时满足: nums1[i] == nums2[j] 且绘制的直线不与任何其他连线(非水平线)相交。 请注意,连线即使在端点也不能相交:每个数字只能属于一条连线。 以这种方法绘制线条,并返回可以绘制的最大连线数。
- 等价于最长公共子数组
- 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 子数组是数组中的一个连续部分。
dp[j]=std::max(nums[j], dp[j-1]+nums[j]);- dp[j]代表必须以nums[j]结尾的连续子数组的最大和
- 给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。 进阶: 如果有大量输入的 S,称作 S1, S2, ... , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?
- 转化为求最长公共子序列是否为s
- 也可以直接使用双指针
- 给你两个字符串 s 和 t ,统计并返回在 s 的 子序列 中 t 出现的个数,结果需要对 10^9 + 7 取模。
- dp[i][j]表示以s[i]结尾的s的子序列出现以t[j]结尾的t的前部分的个数
if(s[i]==t[j]) {
dp[i][j]=dp[i-1][j-1]+dp[i-1][j]
}else{
dp[i][j]=dp[i-1][j]
}- 给定两个单词 word1 和 word2 ,返回使得 word1 和 word2 相同所需的最小步数。 每步 可以删除任意一个字符串中的一个字符。
- 经过删除后,剩下的就是这两个单词中共同的部分,所以可以将此问题转化为求最长公共子序列的长度,将两个单词的长度分别减去最长公共子序列的长度再相加即为所求。
// 最长公共子序列:dp[i][j]=表示以word1[i]和word2[j]结尾的子字符串的最长公共子序列的长度
if(word1[i]==word2[j]) {
dp[i][j]=dp[i-1][j-1]+1;
}else{
dp[i][j]=std::max(dp[i-1][j], dp[i][j-1]);
}- 给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数。 你可以对一个单词进行如下三种操作: 插入一个字符 删除一个字符 替换一个字符
- dp[i][j]表示以word1[i]和word2[j]结尾的子单词的最少操作数
if(word1[i-1]==word2[j-1]) {
dp[i][j]=dp[i-1][j-1];
}else{
dp[i][j]=std::min(dp[i-1][j-1], dp[i-1][j], dp[i][j-1])+1;
}- 给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。 回文字符串 是正着读和倒过来读一样的字符串。 子字符串 是字符串中的由连续字符组成的一个序列。
- 与之前都是只看以word[i]结尾的子串不同,根据回文的对称性质,本题需要考虑左右两边的范围,dp[i][j]表示[s[i], s[j]]闭区间内的子串是否是回文。
vector<vector<int>> dp(s.size(), vector<int>(s.size(), 0));
for(int i=s.size()-1; i>=0; --i){
for(int j=i; j<s.size(); ++j) {
if(s[i]==s[j]) {
if(j-i<=1){
++result;
dp[i][j]=1;
}else if(dp[i+1][j-1]){ // 据此,遍历顺序从下向上,从左到右
++result;
dp[i][j]=1;
}
}
}
} - 给你一个字符串 s ,找出其中最长的回文子序列,并返回该序列的长度。 子序列定义为:不改变剩余字符顺序的情况下,删除某些字符或者不删除任何字符形成的一个序列。
if(s[i]==s[j]){
if(j==i){
dp[i][j]=1;
}else if(j-i==1){
dp[i][j]=2;
}else{
dp[i][j]=dp[i+1][j-1]+2;
}
}else{
if(j-i==1){
dp[i][j]=1;
}else{
dp[i][j]=std::max(dp[i+1][j], dp[i][j-1]); // 递推关系
}
}- 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。
- 使用单调栈,从栈顶到栈底递增
- nums1 中数字 x 的 下一个更大元素 是指 x 在 nums2 中对应位置 右侧 的 第一个 比 x 大的元素。 给你两个 没有重复元素 的数组 nums1 和 nums2 ,下标从 0 开始计数,其中nums1 是 nums2 的子集。 对于每个 0 <= i < nums1.length ,找出满足 nums1[i] == nums2[j] 的下标 j ,并且在 nums2 确定 nums2[j] 的 下一个更大元素 。如果不存在下一个更大元素,那么本次查询的答案是 -1 。 返回一个长度为 nums1.length 的数组 ans 作为答案,满足 ans[i] 是如上所述的 下一个更大元素 。
- 还是用递增栈,不过需要使用 unordered_map<int, int> 记录 nums1 中元素值对应的下标,而遍历是在 nums2 上进行的。
- 给定一个循环数组 nums ( nums[nums.length - 1] 的下一个元素是 nums[0] ),返回 nums 中每个元素的 下一个更大元素 。 数字 x 的 下一个更大的元素 是按数组遍历顺序,这个数字之后的第一个比它更大的数,这意味着你应该循环地搜索它的下一个更大的数。如果不存在,则输出 -1 。
- 由于是循环数组,意味着比当前元素大的下一个元素的index可以在前面。那么如果遍历2次数组,那么就可以完成找到所有元素的下一个更大元素。
- 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
- 分别求右边最大元素和左边更大元素的index两个数组,再进行比较计算
- 给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。 求在该柱状图中,能够勾勒出来的矩形的最大面积。
- 题目描述
给定一个有 n 个节点的有向无环图,节点编号从 1 到 n。请编写一个函数,找出并返回所有从节点 1 到节点 n 的路径。每条路径应以节点编号的列表形式表示。
输入描述
第一行包含两个整数 N,M,表示图中拥有 N 个节点,M 条边
后续 M 行,每行包含两个整数 s 和 t,表示图中的 s 节点与 t 节点中有一条路径
输出描述
输出所有的可达路径,路径中所有节点之间空格隔开,每条路径独占一行,存在多条路径,路径输出的顺序可任意。如果不存在任何一条路径,则输出 -1。
注意输出的序列中,最后一个节点后面没有空格! 例如正确的答案是
1 3 5,而不是1 3 5, 5后面没有空格!
- 题目描述 给定一个由 1(陆地)和 0(水)组成的矩阵,你需要计算岛屿的数量。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。你可以假设矩阵外均被水包围。 输入描述 第一行包含两个整数 N, M,表示矩阵的行数和列数。 后续 N 行,每行包含 M 个数字,数字为 1 或者 0。 输出描述 输出一个整数,表示岛屿的数量。如果不存在岛屿,则输出 0。
- 题目描述 给定一个由 1(陆地)和 0(水)组成的矩阵,计算岛屿的最大面积。岛屿面积的计算方式为组成岛屿的陆地的总数。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。你可以假设矩阵外均被水包围。 输入描述 第一行包含两个整数 N, M,表示矩阵的行数和列数。后续 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。 输出描述 输出一个整数,表示岛屿的最大面积。如果不存在岛屿,则输出 0。
- 每遇到一个陆地,对此陆地及其周围陆地进行dfs或bfs并标记
- 题目描述 给定一个由 1(陆地)和 0(水)组成的矩阵,岛屿指的是由水平或垂直方向上相邻的陆地单元格组成的区域,且完全被水域单元格包围。孤岛是那些位于矩阵内部、所有单元格都不接触边缘的岛屿。 现在你需要计算所有孤岛的总面积,岛屿面积的计算方式为组成岛屿的陆地的总数。 输入描述 第一行包含两个整数 N, M,表示矩阵的行数和列数。之后 N 行,每行包含 M 个数字,数字为 1 或者 0。 输出描述 输出一个整数,表示所有孤岛的总面积,如果不存在孤岛,则输出 0。
- 使用dfs或bfs进行遍历,遍历过程中若发现不是孤岛则将record清零
- 同时bfs或dfs不要因为不是孤岛就立即停止,还要继续将该岛屿的所有陆地都访问并标识到
- 随想录的思路是:从最外圈边界开始,找到陆地,并将此陆地所在的岛屿的所有陆地都修改为海洋,剩下的陆地就都属于孤岛的陆地
- 题目描述 给定一个由 1(陆地)和 0(水)组成的矩阵,岛屿指的是由水平或垂直方向上相邻的陆地单元格组成的区域,且完全被水域单元格包围。孤岛是那些位于矩阵内部、所有单元格都不接触边缘的岛屿。 现在你需要将所有孤岛“沉没”,即将孤岛中的所有陆地单元格(1)转变为水域单元格(0)。 输入描述 第一行包含两个整数 N, M,表示矩阵的行数和列数。 之后 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。 输出描述 输出将孤岛“沉没”之后的岛屿矩阵。 注意:每个元素后面都有一个空格
- 按照回想录的思路,先使用dfs或bfs从矩阵周围将不是孤岛的岛屿的陆地都做标记,然后再遍历未做标记的陆地
- 题目描述 现有一个 N × M 的矩阵,每个单元格包含一个数值,这个数值代表该位置的相对高度。矩阵的左边界和上边界被认为是第一组边界,而矩阵的右边界和下边界被视为第二组边界。 矩阵模拟了一个地形,当雨水落在上面时,水会根据地形的倾斜向低处流动,但只能从较高或等高的地点流向较低或等高并且相邻(上下左右方向)的地点。我们的目标是确定那些单元格,从这些单元格出发的水可以达到第一组边界和第二组边界。 输入描述 第一行包含两个整数 N 和 M,分别表示矩阵的行数和列数。 后续 N 行,每行包含 M 个整数,表示矩阵中的每个单元格的高度。 输出描述 输出共有多行,每行输出两个整数,用一个空格隔开,表示可达第一组边界和第二组边界的单元格的坐标,输出顺序任意。
- 随想录的思路:可以分别从两组边界出发,逆流而上(由低到高),分别标记访问到的单元格,若某单元格两次都被标记了,则为目标单元格
- 题目描述 给定一个由 1(陆地)和 0(水)组成的矩阵,你最多可以将矩阵中的一格水变为一块陆地,在执行了此操作之后,矩阵中最大的岛屿面积是多少。 岛屿面积的计算方式为组成岛屿的陆地的总数。岛屿是被水包围,并且通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设矩阵外均被水包围。 输入描述 第一行包含两个整数 N, M,表示矩阵的行数和列数。之后 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。 输出描述 输出一个整数,表示最大的岛屿面积。如果矩阵中不存在岛屿,则输出0。
- 首先用dfs或bfs遍历一遍标记一下每个岛屿(记录其面积并标记其陆地为其编号),然后遍历每个非陆地单元格,计算其周围岛屿面积之和+1
- 存在特殊情况,全都为陆地,要单独考虑
字典 strList 中从字符串 beginStr 和 endStr 的转换序列是一个按下述规格形成的序列:
-
序列中第一个字符串是 beginStr。
-
序列中最后一个字符串是 endStr。
-
每次转换只能改变一个字符。
-
转换过程中的中间字符串必须是字典 strList 中的字符串,且strList里的每个字符串只用使用一次。
-
给你两个字符串 beginStr 和 endStr 和一个字典 strList,找到从 beginStr 到 endStr 的最短转换序列中的字符串数目。如果不存在这样的转换序列,返回 0。
-
输入描述 第一行包含一个整数 N,表示字典 strList 中的字符串数量。 第二行包含两个字符串,用空格隔开,分别代表 beginStr 和 endStr。 后续 N 行,每行一个字符串,代表 strList 中的字符串。
-
输出描述 输出一个整数,代表从 beginStr 转换到 endStr 需要的最短转换序列中的字符串数量。如果不存在这样的转换序列,则输出 0。
-
输入示例 6 abc def efc dbc ebc dec dfc yhn
-
输出示例 4
-
提示信息 从 startStr 到 endStr,在 strList 中最短的路径为 abc -> dbc -> dec -> def,所以输出结果为 4,如图:
-
数据范围:2 <= N <= 500
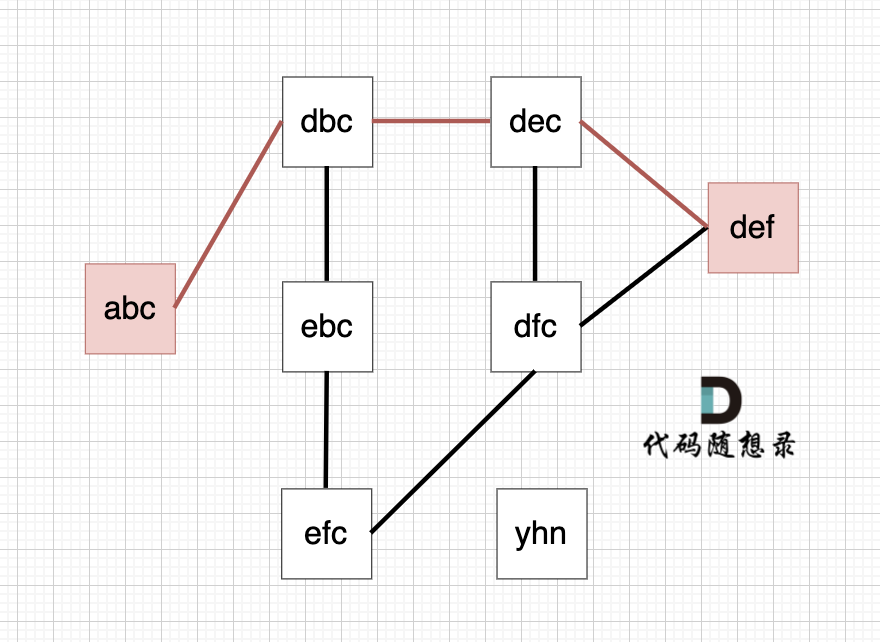
- 可以使用dfs或bfs寻找从beginStr到endStr的所有可能路径,形成一条边需要满足只改变了一个字符,记录最短路径的节点值。可以将beginStr和endStr加入到strList中,dfs只从beginStr开始遍历。
- 随想录思路:由于求的是无向图最短路径,使用bfs较为合适,当前遍历到endStr时长度即为最短路径,随想录的思路是对字符串的每个字符进行26个字母的变换并检测是否有与之相同的字符串
给定一个有向图,包含 N 个节点,节点编号分别为 1,2,...,N。现从 1 号节点开始,如果可以从 1 号节点的边可以到达任何节点,则输出 1,否则输出 -1。
输入描述
第一行包含两个正整数,表示节点数量 N 和边的数量 K。 后续 K 行,每行两个正整数 s 和 t,表示从 s 节点有一条边单向连接到 t 节点。
输出描述
如果可以从 1 号节点的边可以到达任何节点,则输出 1,否则输出 -1。
输入示例
4 4
1 2
2 1
1 3
2 4
输出示例
1
提示信息
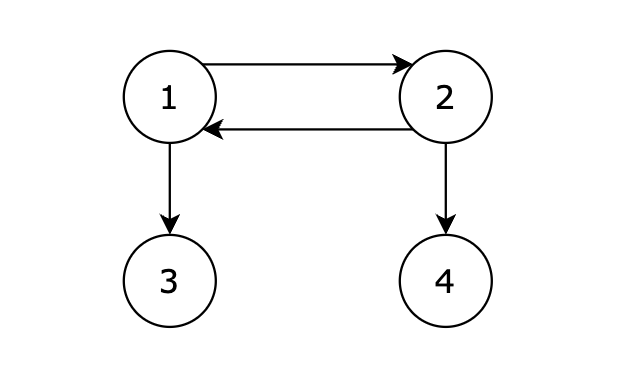
- 基本思路就是使用dfs或bfs进行遍历把访问过的节点都标记上,值得注意的是如何存储有向图,本题适合使用邻接表
给定一个由 1(陆地)和 0(水)组成的矩阵,岛屿是被水包围,并且通过水平方向或垂直方向上相邻的陆地连接而成的。
你可以假设矩阵外均被水包围。在矩阵中恰好拥有一个岛屿,假设组成岛屿的陆地边长都为 1,请计算岛屿的周长。岛屿内部没有水域。
输入描述
第一行包含两个整数 N, M,表示矩阵的行数和列数。之后 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。
输出描述
输出一个整数,表示岛屿的周长。
输入示例
5 5
0 0 0 0 0
0 1 0 1 0
0 1 1 1 0
0 1 1 1 0
0 0 0 0 0
输出示例
14
提示信息
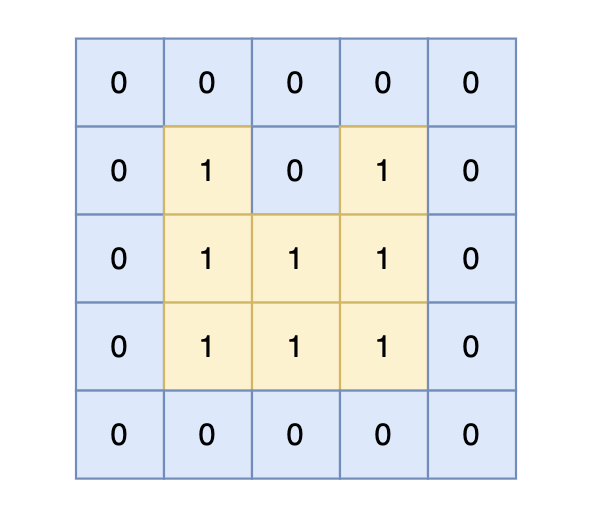
- 结合示意图,可以发现周长中的每个单位1都对应着某块陆地的一条边,所以通过dfs或bfs遍历时可以判断该陆地网格的4条边是否是周长中的1条边
- 随想录的思路:周长=4 * 岛屿陆地数- 2 * 临边数
题目描述 给定一个包含 n 个节点的无向图中,节点编号从 1 到 n (含 1 和 n )。
你的任务是判断是否有一条从节点 source 出发到节点 destination 的路径存在。
输入描述 第一行包含两个正整数 N 和 M,N 代表节点的个数,M 代表边的个数。
后续 M 行,每行两个正整数 s 和 t,代表从节点 s 与节点 t 之间有一条边。
最后一行包含两个正整数,代表起始节点 source 和目标节点 destination。
输出描述
输出一个整数,代表是否存在从节点 source 到节点 destination 的路径。如果存在,输出 1;否则,输出 0。
输入示例
5 4
1 2
1 3
2 4
3 4
1 4
输出示例
1
提示信息
- 使用并查集,虽然并查集寻找根节点的模式类似于有向图,而本题是无向图,但考虑到2个节点只要根节点相同,就在同一个集合中,就可以认为存在1条路径
题目描述 树可以看成是一个图(拥有 n 个节点和 n - 1 条边的连通无环无向图)。
现给定一个拥有 n 个节点(节点标号是从 1 到 n)和 n 条边的连通无向图,请找出一条可以删除的边,删除后图可以变成一棵树。
输入描述 第一行包含一个整数 N,表示图的节点个数和边的个数。
后续 N 行,每行包含两个整数 s 和 t,表示图中 s 和 t 之间有一条边。
输出描述
输出一条可以删除的边。如果有多个答案,请删除标准输入中最后出现的那条边。
输入示例
3
1 2
2 3
1 3
输出示例
1 3
提示信息
1 <= N <= 1000.
- 由于树最小的连通图,每次加边时,一定是将两个不连通的节点相连,因此可以通过判断2个节点是否属于同一集合来确定是否是冗余连接
有向树指满足以下条件的有向图。该树只有一个根节点,所有其他节点都是该根节点的后继。该树除了根节点之外的每一个节点都有且只有一个父节点,而根节点没有父节点。有根树拥有 n 个节点和 n - 1 条边。
输入一个有向图,该图由一个有着 n 个节点(节点编号 从 1 到 n),n 条边,请返回一条可以删除的边,使得删除该条边之后该有向图可以被当作一颗有向树。
输入描述 第一行输入一个整数 N,表示有向图中节点和边的个数。
后续 N 行,每行输入两个整数 s 和 t,代表 s 节点有一条连接 t 节点的单向边
输出描述
输出一条可以删除的边,若有多条边可以删除,请输出标准输入中最后出现的一条边。
输入示例
3
1 2
1 3
2 3
输出示例
2 3
提示信息
- 与冗余连接类似,还是使用并查集,但是因为是有向图,需要考虑边的方向,s -> t 表示一条s到t的单向边,那么可以设置 t 的 根为 s的根,所以每次加边时,需要除了需要判断2个节点是否有相同的根(即是否构成有向环),还要考虑 后一个节点 是否已经有了父节点(防止入度大于2),如果这两种情况同时发生,则删除环上的边
在世界的某个区域,有一些分散的神秘岛屿,每个岛屿上都有一种珍稀的资源或者宝藏。国王打算在这些岛屿上建公路,方便运输。
不同岛屿之间,路途距离不同,国王希望你可以规划建公路的方案,如何可以以最短的总公路距离将 所有岛屿联通起来(注意:这是一个无向图)。
给定一张地图,其中包括了所有的岛屿,以及它们之间的距离。以最小化公路建设长度,确保可以链接到所有岛屿。
输入描述 第一行包含两个整数V 和 E,V代表顶点数,E代表边数 。顶点编号是从1到V。例如:V=2,一个有两个顶点,分别是1和2。
接下来共有 E 行,每行三个整数 v1,v2 和 val,v1 和 v2 为边的起点和终点,val代表边的权值。
输出描述 输出联通所有岛屿的最小路径总距离 输入示例 7 11 1 2 1 1 3 1 1 5 2 2 6 1 2 4 2 2 3 2 3 4 1 4 5 1 5 6 2 5 7 1 6 7 1 输出示例 6 提示信息 数据范围: 2 <= V <= 10000; 1 <= E <= 100000; 0 <= val <= 10000;
如下图,可见将所有的顶点都访问一遍,总距离最低是6.

- 显然本题是求最小生成树,可以使用 prim 或 krustal 算法
某个大型软件项目的构建系统拥有 N 个文件,文件编号从 0 到 N - 1,在这些文件中,某些文件依赖于其他文件的内容,这意味着如果文件 A 依赖于文件 B,则必须在处理文件 A 之前处理文件 B (0 <= A, B <= N - 1)。请编写一个算法,用于确定文件处理的顺序。 输入描述 第一行输入两个正整数 N, M。表示 N 个文件之间拥有 M 条依赖关系。
后续 M 行,每行两个正整数 S 和 T,表示 T 文件依赖于 S 文件。
输出描述 输出共一行,如果能处理成功,则输出文件顺序,用空格隔开。
如果不能成功处理(相互依赖),则输出 -1。
输入示例
5 4
0 1
0 2
1 3
2 4
输出示例
0 1 2 3 4
提示信息
文件依赖关系如下:
- 本题考察有向图的拓扑排序,思路是每次寻找没有后继节点的节点,即叶节点,记录下来,再删去该节点
- 随想录的思路是找入度为0的节点,而入度可以在处理输入的有向边是记录;同时,可以对于叶子节点,其出度为0,也可以记录出度用作叶子节点的判断;
- 随想录是使用队列的方式存储要访问的节点,在处理某个节点时,将其入度为0的后继节点加入队列,而我是通过判断是否已经访问过和出度是否为0来遍历的
小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。
小明的起点是第一个车站,终点是最后一个车站。然而,途中的各个车站之间的道路状况、交通拥堵程度以及可能的自然因素(如天气变化)等不同,这些因素都会影响每条路径的通行时间。
小明希望能选择一条花费时间最少的路线,以确保他能够尽快到达目的地。
输入描述 第一行包含两个正整数,第一个正整数 N 表示一共有 N 个公共汽车站,第二个正整数 M 表示有 M 条公路。
接下来为 M 行,每行包括三个整数,S、E 和 V,代表了从 S 车站可以单向直达 E 车站,并且需要花费 V 单位的时间。
输出描述 输出一个整数,代表小明从起点到终点所花费的最小时间。 输入示例 7 9 1 2 1 1 3 4 2 3 2 2 4 5 3 4 2 4 5 3 2 6 4 5 7 4 6 7 9 输出示例 12 提示信息 能够到达的情况:
如下图所示,起始车站为 1 号车站,终点车站为 7 号车站,绿色路线为最短的路线,路线总长度为 12,则输出 12。
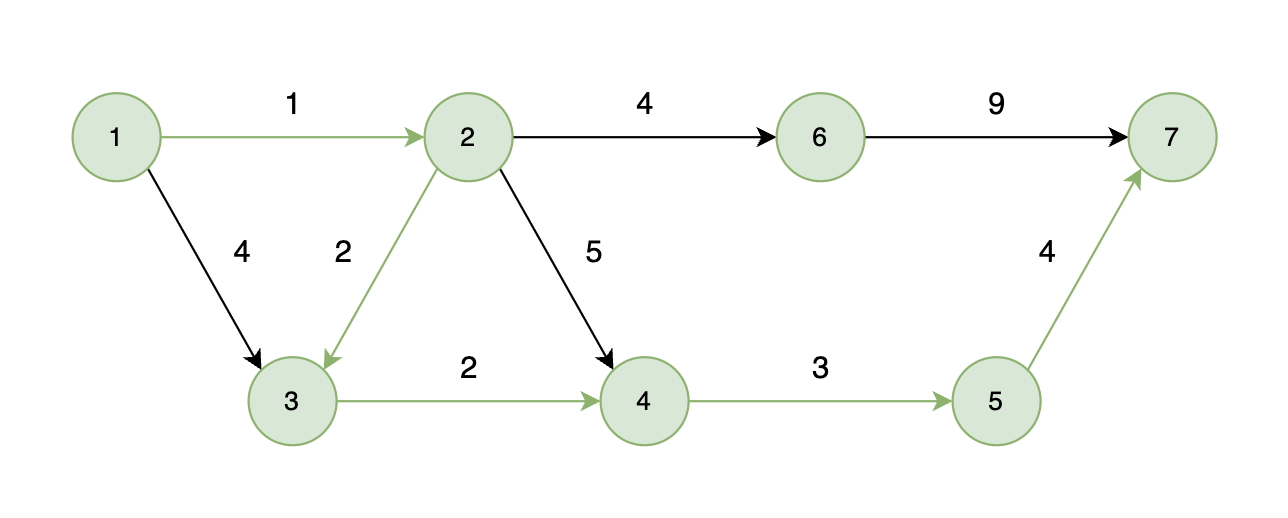

某国为促进城市间经济交流,决定对货物运输提供补贴。共有 n 个编号为 1 到 n 的城市,通过道路网络连接,网络中的道路仅允许从某个城市单向通行到另一个城市,不能反向通行。
网络中的道路都有各自的运输成本和政府补贴,道路的权值计算方式为:运输成本 - 政府补贴。权值为正表示扣除了政府补贴后运输货物仍需支付的费用;权值为负则表示政府的补贴超过了支出的运输成本,实际表现为运输过程中还能赚取一定的收益。
请找出从城市 1 到城市 n 的所有可能路径中,综合政府补贴后的最低运输成本。如果最低运输成本是一个负数,它表示在遵循最优路径的情况下,运输过程中反而能够实现盈利。
城市 1 到城市 n 之间可能会出现没有路径的情况,同时保证道路网络中不存在任何负权回路。
输入描述 第一行包含两个正整数,第一个正整数 n 表示该国一共有 n 个城市,第二个整数 m 表示这些城市中共有 m 条道路。
接下来为 m 行,每行包括三个整数,s、t 和 v,表示 s 号城市运输货物到达 t 号城市,道路权值为 v (单向图)。
输出描述
如果能够从城市 1 到连通到城市 n, 请输出一个整数,表示运输成本。如果该整数是负数,则表示实现了盈利。如果从城市 1 没有路径可达城市 n,请输出 "unconnected"。
输入示例
6 7
5 6 -2
1 2 1
5 3 1
2 5 2
2 4 -3
4 6 4
1 3 5
输出示例
1
提示信息

示例中最佳路径是从 1 -> 2 -> 5 -> 6,路上的权值分别为 1 2 -2,最终的最低运输成本为 1 + 2 + (-2) = 1。
示例 2:
4 2 1 2 -1 3 4 -1
在此示例中,无法找到一条路径从 1 通往 4,所以此时应该输出 "unconnected"。
数据范围:
1 <= n <= 1000; 1 <= m <= 10000; -100 <= v <= 100;
- 单源含负权重边的最短路径问题,使用Bellman-Ford算法
- Bellman-Ford优化版本:使用队列来保证每次只对已经计算过的节点进行松弛,同时,使用bool visited[] 保证队列中不含重复节点,使用邻接表将当前节点的相邻节点加入队列
- 对于判断是否存在负环,初始版本的Bellman-Ford只需要在第V次判断最短路径是否有更新;优化版本的Bellman-Ford需要记录每个节点加入队列的次数,若某节点加入队列次数>=V次,则存在负环
某国为促进城市间经济交流,决定对货物运输提供补贴。共有 n 个编号为 1 到 n 的城市,通过道路网络连接,网络中的道路仅允许从某个城市单向通行到另一个城市,不能反向通行。
网络中的道路都有各自的运输成本和政府补贴,道路的权值计算方式为:运输成本 - 政府补贴。权值为正表示扣除了政府补贴后运输货物仍需支付的费用;权值为负则表示政府的补贴超过了支出的运输成本,实际表现为运输过程中还能赚取一定的收益。
请计算在最多经过 k 个城市的条件下,从城市 src 到城市 dst 的最低运输成本。
输入描述 第一行包含两个正整数,第一个正整数 n 表示该国一共有 n 个城市,第二个整数 m 表示这些城市中共有 m 条道路。
接下来为 m 行,每行包括三个整数,s、t 和 v,表示 s 号城市运输货物到达 t 号城市,道路权值为 v。
最后一行包含三个正整数,src、dst、和 k,src 和 dst 为城市编号,从 src 到 dst 经过的城市数量限制。
输出描述 输出一个整数,表示从城市 src 到城市 dst 的最低运输成本,如果无法在给定经过城市数量限制下找到从 src 到 dst 的路径,则输出 "unreachable",表示不存在符合条件的运输方案。
- 进行一次松弛相等于求与起点相邻1条边的节点的最短距离,松弛k+1次即求与起点相邻k+1条边的节点的最短距离
- 同时,由于存在负环的缘故,在进行每次松弛前,要拷贝当前的最短距离列表,使得松弛更新总是根据前一次松弛后的结果,而不是本次松弛中产生的结果
小明喜欢去公园散步,公园内布置了许多的景点,相互之间通过小路连接,小明希望在观看景点的同时,能够节省体力,走最短的路径。
给定一个公园景点图,图中有 N 个景点(编号为 1 到 N),以及 M 条双向道路连接着这些景点。每条道路上行走的距离都是已知的。
小明有 Q 个观景计划,每个计划都有一个起点 start 和一个终点 end,表示他想从景点 start 前往景点 end。由于小明希望节省体力,他想知道每个观景计划中从起点到终点的最短路径长度。 请你帮助小明计算出每个观景计划的最短路径长度。
输入描述 第一行包含两个整数 N, M, 分别表示景点的数量和道路的数量。
接下来的 M 行,每行包含三个整数 u, v, w,表示景点 u 和景点 v 之间有一条长度为 w 的双向道路。
接下里的一行包含一个整数 Q,表示观景计划的数量。
接下来的 Q 行,每行包含两个整数 start, end,表示一个观景计划的起点和终点。
输出描述 对于每个观景计划,输出一行表示从起点到终点的最短路径长度。如果两个景点之间不存在路径,则输出 -1。 输入示例 7 3 2 3 4 3 6 6 4 7 8 2 2 3 3 4 输出示例 4 -1 提示信息 从 2 到 3 的路径长度为 4,3 到 4 之间并没有道路。
1 <= N, M, Q <= 1000.
- 对于M对起点和终点,可以直接使用M次Bellman-Ford算法,时间复杂度为 O(M * V * E)
- 因为本题是无向图,所以Bellman-Ford算法进行松弛时,对于每条无向边,要对2端节点都进行松弛
- 当然,对于多源的最短路径问题,可以使用Folyd算法,基于动态规划的思想
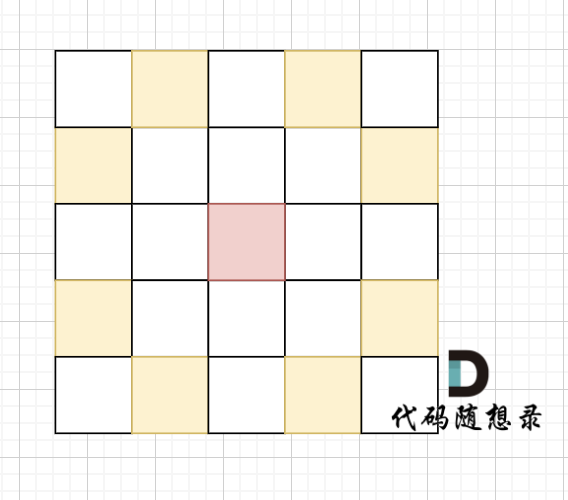
在象棋中,马和象的移动规则分别是“马走日”和“象走田”。现给定骑士的起始坐标和目标坐标,要求根据骑士的移动规则,计算从起点到达目标点所需的最短步数。
棋盘大小 1000 x 1000(棋盘的 x 和 y 坐标均在 [1, 1000] 区间内,包含边界)
输入描述 第一行包含一个整数 n,表示测试用例的数量,1 <= n <= 100。
接下来的 n 行,每行包含四个整数 a1, a2, b1, b2,分别表示骑士的起始位置 (a1, a2) 和目标位置 (b1, b2)。
输出描述
输出共 n 行,每行输出一个整数,表示骑士从起点到目标点的最短路径长度。
输入示例
6
5 2 5 4
1 1 2 2
1 1 8 8
1 1 8 7
2 1 3 3
4 6 4 6
输出示例
2
4
6
5
1
0
提示信息
骑士移动规则如图,红色是起始位置,黄色是骑士可以走的地方。
- 可以使用BFS,但是时间复杂度太高
- 使用AStar算法,通过启发式函数计算起点到当前节点的距离+当前节点到终点的距离之和决定优先级队列中的顺序,从而bfs的一层一层的搜索修改为向终点方向的搜索,因此可以大幅度降低时间复杂度
给你二叉树的根节点 root ,请你采用前序遍历的方式,将二叉树转化为一个由括号和整数组成的字符串,返回构造出的字符串。
空节点使用一对空括号对 "()" 表示,转化后需要省略所有不影响字符串与原始二叉树之间的一对一映射关系的空括号对。
- 总体可以分为2步,首先使用前序遍历生成字符串,然后删除可以省略的空括号对
- 二叉树的前序遍历:先当前节点,然后左子树,最后右子树,可以使用递归
- 自己想的思路是通过string的insert函数在某个位置上进行插入,插入括号对或数字,位置的确定比较麻烦;另一种思路是直接在递归函数返回时构造string,通过+号将括号和字符串连接构造string,比较简洁
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
提示: 输入输出格式与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
- 可以使用根据二叉树创建字符串的方式进行序列化,然后反序列化进行解析
- 还可以使用dfs的先序遍历,如果为叶节点,则加上2个none
给定一个二叉搜索树 root 和一个目标结果 k,如果二叉搜索树中存在两个元素且它们的和等于给定的目标结果,则返回 true。
- 首先,二叉搜索树保证了数据的有序性;目标是寻找和为k的2个元素
- 二叉搜索树的中序遍历为有序数组,然后使用首尾双指针发寻找两数之和
- 使用dfs或bfs遍历二叉搜索树,同时使用哈希表记录已经遍历过的节点的值
给你一个有 n 个服务器的计算机网络,服务器编号为 0 到 n - 1 。同时给你一个二维整数数组 edges ,其中 edges[i] = [ui, vi] 表示服务器 ui 和 vi 之间有一条信息线路,在 一秒 内它们之间可以传输 任意 数目的信息。再给你一个长度为 n 且下标从 0 开始的整数数组 patience 。
题目保证所有服务器都是 相通 的,也就是说一个信息从任意服务器出发,都可以通过这些信息线路直接或间接地到达任何其他服务器。
编号为 0 的服务器是 主 服务器,其他服务器为 数据 服务器。每个数据服务器都要向主服务器发送信息,并等待回复。信息在服务器之间按 最优 线路传输,也就是说每个信息都会以 最少时间 到达主服务器。主服务器会处理 所有 新到达的信息并 立即 按照每条信息来时的路线 反方向 发送回复信息。
在 0 秒的开始,所有数据服务器都会发送各自需要处理的信息。从第 1 秒开始,每 一秒最 开始 时,每个数据服务器都会检查它是否收到了主服务器的回复信息(包括新发出信息的回复信息):
如果还没收到任何回复信息,那么该服务器会周期性 重发 信息。数据服务器 i 每 patience[i] 秒都会重发一条信息,也就是说,数据服务器 i 在上一次发送信息给主服务器后的 patience[i] 秒 后 会重发一条信息给主服务器。 否则,该数据服务器 不会重发 信息。 当没有任何信息在线路上传输或者到达某服务器时,该计算机网络变为 空闲 状态。
请返回计算机网络变为 空闲 状态的 最早秒数 。
- 问题
- 如何存储图:邻接表
- 如何求最短路径:BFS,从目标节点0向其他节点扩散,而不是从其他节点寻找0节点
- 如何求空闲时间:对每个节点分别求空闲时间,取最大值,根据该节点到0的最短路径和patience值确定
总共有 n 个颜色片段排成一列,每个颜色片段要么是 'A' 要么是 'B' 。给你一个长度为 n 的字符串 colors ,其中 colors[i] 表示第 i 个颜色片段的颜色。
Alice 和 Bob 在玩一个游戏,他们 轮流 从这个字符串中删除颜色。Alice 先手 。
如果一个颜色片段为 'A' 且 相邻两个颜色 都是颜色 'A' ,那么 Alice 可以删除该颜色片段。Alice 不可以 删除任何颜色 'B' 片段。 如果一个颜色片段为 'B' 且 相邻两个颜色 都是颜色 'B' ,那么 Bob 可以删除该颜色片段。Bob 不可以 删除任何颜色 'A' 片段。 Alice 和 Bob 不能 从字符串两端删除颜色片段。 如果其中一人无法继续操作,则该玩家 输 掉游戏且另一玩家 获胜 。 假设 Alice 和 Bob 都采用最优策略,如果 Alice 获胜,请返回 true,否则 Bob 获胜,返回 false。
- 由于多个连续的相同片段经过若干次删除后仍然会剩余2个相同片段,所以A和B的删除策略似乎相互没有影响
- 只需要一次性统计A和B可以删除的个数并比较
给定一个整数 n ,返回 n! 结果中尾随零的数量。 提示 n! = n * (n - 1) * (n - 2) * ... * 3 * 2 * 1
- 10! = 10 * 9 * 8 * 7 * 6 * 5 * 4 * 3 * 2 * 1 = 3628800
- 10 * 370 * 6030 * 5 * 2 * 50 * 2 = 22311000000
- 暴力算法是在求完阶乘结果后算尾随零的个数,但是阶乘后的结果太大了,long long都无法表示
- 或者可以计算包含的 5、2和10的个数,1对5和2代表一个0,1个10代表一个0,10也可以分解为2 * 5
- 同时,乘积中2的数目远多于5,所以末尾0个数由5的个数决定
给定整数 n 和 k,返回 [1, n] 中字典序第 k 小的数字。
示例 1: 输入: n = 13, k = 2 输出: 10 解释: 字典序的排列是 [1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9],所以第二小的数字是 10。
示例 2: 输入: n = 1, k = 1 输出: 1
提示: 1 <= k <= n <= 109
- 首先是构造一个函数用以判断2个数字在字典序中的大小,从左向右依次比较,若某一位小则小,若一个变为0另一个没有,则变为0的小
给你一个数组 nums,对于其中每个元素 nums[i],请你统计数组中比它小的所有数字的数目。
换而言之,对于每个 nums[i] 你必须计算出有效的 j 的数量,其中 j 满足 j != i 且 nums[j] < nums[i] 。
以数组形式返回答案。
- 使用类似于map的数据结构记录小于num[i]的数字的数目
给定一个整数数组 arr,如果它是有效的山脉数组就返回 true,否则返回 false。
让我们回顾一下,如果 arr 满足下述条件,那么它是一个山脉数组:
arr.length >= 3
在 0 < i < arr.length - 1 条件下,存在 i 使得:
arr[0] < arr[1] < ... arr[i-1] < arr[i]
arr[i] > arr[i+1] > ... > arr[arr.length - 1]
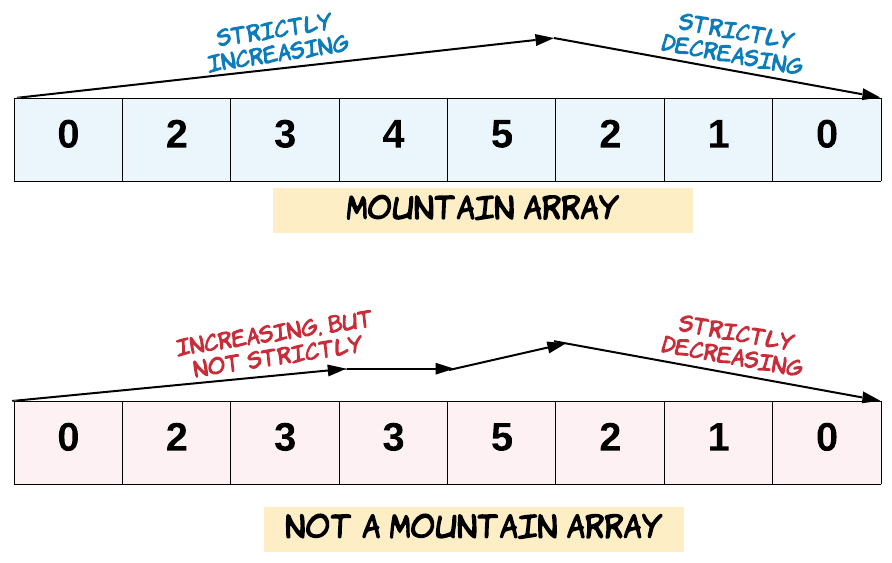
- 分为2个阶段(递增和递减),用2个布尔变量表示
- 双指针,从两端向中间汇合,同时要排出只递增或只递减的情况
给你一个字符串 s 。
你的任务是重复以下操作删除 所有 数字字符:
删除 第一个数字字符 以及它左边 最近 的 非数字 字符。 请你返回删除所有数字字符以后剩下的字符串。
- 直接循环模拟,for循环找到第一个数字,看情况删除,时间复杂度O(n^2)
- 由于删除的非数字字符一定是数字字符的前一个,所以可以使用栈来维护,同时std::string可以模拟栈的行为(s.pop_back()和s.push_bach()),因为可以直接在结果string上操作。
给你一个整数数组 arr,如果每个数的出现次数都是独一无二的,就返回 true;否则返回 false。 示例 1:
输入:arr = [1,2,2,1,1,3] 输出:true 解释:在该数组中,1 出现了 3 次,2 出现了 2 次,3 只出现了 1 次。没有两个数的出现次数相同。 示例 2:
输入:arr = [1,2] 输出:false 示例 3:
输入:arr = [-3,0,1,-3,1,1,1,-3,10,0] 输出:true
提示:
1 <= arr.length <= 1000 -1000 <= arr[i] <= 1000
- 使用map统计每个数的出现次数,再确定map的值是否有重复(也可以用map)
给你一个整数数组 nums 和一个 非负 整数 k 。如果一个整数序列 seq 满足在下标范围 [0, seq.length - 2] 中 最多只有 k 个下标 i 满足 seq[i] != seq[i + 1] ,那么我们称这个整数序列为 好 序列。 请你返回 nums 中 好 子序列的最长长度。
- 初步想法是使用动态规划
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。
- 统计每个元素之前的零元素的个数,然后根据此个数依次向前移动,再将最后几个元素变为0。统计零元素的个数与元素前移可以在一个for循环中同时进行,只需要用一个变量记录遇到的零元素的个数。
给你一个整数数组 nums ,请计算数组的 中心下标 。
数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。
如果中心下标位于数组最左端,那么左侧数之和视为 0 ,因为在下标的左侧不存在元素。这一点对于中心下标位于数组最右端同样适用。
如果数组有多个中心下标,应该返回 最靠近左边 的那一个。如果数组不存在中心下标,返回 -1 。
示例 1:
输入:nums = [1, 7, 3, 6, 5, 6] 输出:3 解释: 中心下标是 3 。 左侧数之和 sum = nums[0] + nums[1] + nums[2] = 1 + 7 + 3 = 11 , 右侧数之和 sum = nums[4] + nums[5] = 5 + 6 = 11 ,二者相等。 示例 2:
输入:nums = [1, 2, 3] 输出:-1 解释: 数组中不存在满足此条件的中心下标。 示例 3:
输入:nums = [2, 1, -1] 输出:0 解释: 中心下标是 0 。 左侧数之和 sum = 0 ,(下标 0 左侧不存在元素), 右侧数之和 sum = nums[1] + nums[2] = 1 + -1 = 0 。
提示:
1 <= nums.length <= 10^4 -1000 <= nums[i] <= 1000
- 需要考虑到left_sum与right_sum的关系:
left_sum+nums[cur]+right_sum=sum。因此只需一次计算总和sum即可降低之后计算左和与右和的复杂度,左和只需在从左到右的遍历过程中每次加前一个数即可。
给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。
- 有序数组+时间复杂度 O(log n) => 二分法,但是题目要求所求元素的第一个和最后一个位置,一个单纯的想法是先用二分法找到一个目标元素,再分别向左向右找第一个和最后一个位置,但这样最坏情况的时间复杂度为 O(n)
- 随想录的思路是是否二分法分别求左边界和右边界,加起来仍然是 O(log n),其中用二分法求左右边界的算法值得仔细思考
class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
int leftBorder = getLeftBorder(nums, target);
int rightBorder = getRightBorder(nums, target);
// 情况一
if (leftBorder == -2 || rightBorder == -2) return {-1, -1};
// 情况三
if (rightBorder - leftBorder > 1) return {leftBorder + 1, rightBorder - 1};
// 情况二
return {-1, -1};
}
private:
int getRightBorder(vector<int>& nums, int target) {
int left = 0;
int right = nums.size() - 1;
int rightBorder = -2; // 记录一下rightBorder没有被赋值的情况
while (left <= right) {
int middle = left + ((right - left) / 2);
if (nums[middle] > target) {
right = middle - 1;
} else { // 寻找右边界,nums[middle] == target的时候更新left
left = middle + 1;
rightBorder = left;
}
}
return rightBorder;
}
int getLeftBorder(vector<int>& nums, int target) {
int left = 0;
int right = nums.size() - 1;
int leftBorder = -2; // 记录一下leftBorder没有被赋值的情况
while (left <= right) {
int middle = left + ((right - left) / 2);
if (nums[middle] >= target) { // 寻找左边界,nums[middle] == target的时候更新right
right = middle - 1;
leftBorder = right;
} else {
left = middle + 1;
}
}
return leftBorder;
}
};这个算法实现了一个二分查找,目的是找到给定目标值 target 在一个已排序数组 nums 中的右边界(即找到第一个大于 target 的元素的索引)。如果没有大于 target 的元素,函数将返回 -2,以表明 target 在数组的所有元素的左侧。
-
初始化变量:
left和right:分别指向数组的左右边界,初始时分别为 0 和nums.size() - 1。rightBorder:用于记录右边界的索引,初始为 -2,表示尚未找到。
-
二分查找循环:
- 只要
left小于等于right,就继续进行查找。 - 计算中间索引
middle:使用(left + (right - left) / 2)来防止溢出。
- 只要
-
判断中间元素:
- 如果
nums[middle]大于target,说明目标值可能在左半部分,因此更新right为middle - 1。 - 如果
nums[middle]小于或等于target,说明目标值可能在右半部分,或者middle可能就是目标值,因此:- 更新
left为middle + 1。 - 同时更新
rightBorder为left,因为这个时候left就是下一个可能的右边界。
- 更新
- 如果
-
返回结果:
- 当循环结束后,返回
rightBorder。如果target小于数组中的所有元素,rightBorder将保持 -2。
- 当循环结束后,返回
这种方法适用于需要在一个有序数组中找到某个值的右边界的场景,例如在进行区间查询、统计问题时。它的时间复杂度为 O(log n),因为每次迭代都将搜索范围减半。
给定一个非负整数数组 nums, nums 中一半整数是 奇数 ,一半整数是 偶数 。
对数组进行排序,以便当 nums[i] 为奇数时,i 也是 奇数 ;当 nums[i] 为偶数时, i 也是 偶数 。
你可以返回 任何满足上述条件的数组作为答案 。 示例 1:
输入:nums = [4,2,5,7] 输出:[4,5,2,7] 解释:[4,7,2,5],[2,5,4,7],[2,7,4,5] 也会被接受。 示例 2:
输入:nums = [2,3] 输出:[2,3] 提示:
2 <= nums.length <= 2 * 10^4 nums.length 是偶数 nums 中一半是偶数 0 <= nums[i] <= 1000 进阶:可以不使用额外空间解决问题吗?
- 最初的思路:从位置0开始依次遍历,分别获取奇数和偶数数组,再创建一个符合题意的数组并将奇数和偶数填入,时间复杂度为 O(n),空间复杂度为 O(n)
- gpt给出的优化思路:最初算法的时间复杂度是 O(n),但额外使用了两个数组 odd 和 even 来存储奇数和偶数,空间复杂度是 O(n)。优化的思路是避免额外的空间开销,直接在原数组 nums 上进行操作,这样可以将空间复杂度降到 O(1)。使用双指针法,分别指向数组的奇数和偶数位置,遍历数组,让这两个指针都发生奇数位置为偶数或偶数位置为奇数时,交换两个位置的元素,这样就能在原数组上操作,空间复杂度降低至 O(1)。
给你一个 非严格递增排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。
考虑 nums 的唯一元素的数量为 k ,你需要做以下事情确保你的题解可以被通过:
更改数组 nums ,使 nums 的前 k 个元素包含唯一元素,并按照它们最初在 nums 中出现的顺序排列。nums 的其余元素与 nums 的大小不重要。 返回 k 。 判题标准:
系统会用下面的代码来测试你的题解:
int[] nums = [...]; // 输入数组 int[] expectedNums = [...]; // 长度正确的期望答案
int k = removeDuplicates(nums); // 调用
assert k == expectedNums.length; for (int i = 0; i < k; i++) { assert nums[i] == expectedNums[i]; } 如果所有断言都通过,那么您的题解将被 通过。
示例 1:
输入:nums = [1,1,2] 输出:2, nums = [1,2,_] 解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。 示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4] 输出:5, nums = [0,1,2,3,4] 解释:函数应该返回新的长度 5 , 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4 。不需要考虑数组中超出新长度后面的元素。
提示:
1 <= nums.length <= 3 * 104 -104 <= nums[i] <= 104 nums 已按 非严格递增 排列
- 最初的思路:从头开始依次遍历,使用2个指针,一个指向重复的要被替换的元素,另一个向后遍历,当后一个指针指向的元素与之前的元素相同,则后一个指针继续遍历,直到遇到新的不同的元素,则此时前一个指针的元素被替换为这个新的元素,然后前一个指针前进一步。
给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。 说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝 int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。 // 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。 for (int i = 0; i < len; i++) { print(nums[i]); }
示例 1:
输入:nums = [1,1,1,2,2,3] 输出:5, nums = [1,1,2,2,3] 解释:函数应返回新长度 length = 5, 并且原数组的前五个元素被修改为 1, 1, 2, 2, 3。 不需要考虑数组中超出新长度后面的元素。 示例 2:
输入:nums = [0,0,1,1,1,1,2,3,3] 输出:7, nums = [0,0,1,1,2,3,3] 解释:函数应返回新长度 length = 7, 并且原数组的前七个元素被修改为 0, 0, 1, 1, 2, 3, 3。不需要考虑数组中超出新长度后面的元素。
提示:
1 <= nums.length <= 3 * 104 -104 <= nums[i] <= 104 nums 已按升序排列
- 最初的思路是使用一个变量flag来跟踪重复的次数,其他与之前类似
- gpt的思路:
#include <vector>
using std::vector;
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
const int n = nums.size();
if (n <= 2) {
return n;
}
int p1 = 2; // 从第三个元素开始判断
for (int p2 = 2; p2 < n; ++p2) {
if (nums[p2] != nums[p1 - 2]) {
nums[p1] = nums[p2]; // 当前元素与 p1-2 元素不相等,放入 p1 位置
++p1; // 更新 p1,表示新数组的有效长度
}
}
return p1; // 新数组的长度
}
};
保留两个指针 p1 和 p2,p1 继续指向新数组的插入位置,p2 遍历整个数组。为了保证每个元素最多出现两次,我们只需确保在 p1-2 位置上的元素和当前 nums[p2] 不相等即可。如果 nums[p2] 和前两个元素相同,跳过该元素;否则将其插入到 p1 位置。 当nums[p1-2]==nums[p2]时,必有nums[p1-2]==nums[p1-1]==nums[p2],因为数组是有序的或者说是递增的。
给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:
输入:nums = [3,2,3] 输出:3 示例 2:
输入:nums = [2,2,1,1,1,2,2] 输出:2
提示: n == nums.length 1 <= n <= 5 * 104 -109 <= nums[i] <= 109
进阶:尝试设计时间复杂度为 O(n)、空间复杂度为 O(1) 的算法解决此问题。
- 排序法,时间复杂度 O(nlog n),空间复杂度为 O(log n)(递归排序算法的栈空间)
- 哈希法,时间复杂度 O(n),空间复杂度 O(n)
给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。
根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指数 是指他(她)至少发表了 h 篇论文,并且 至少 有 h 篇论文被引用次数大于等于 h 。如果 h 有多种可能的值,h 指数 是其中最大的那个。
示例 1:
输入:citations = [3,0,6,1,5] 输出:3 解释:给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 3, 0, 6, 1, 5 次。 由于研究者有 3 篇论文每篇 至少 被引用了 3 次,其余两篇论文每篇被引用 不多于 3 次,所以她的 h 指数是 3。 示例 2:
输入:citations = [1,3,1] 输出:1
提示:
n == citations.length 1 <= n <= 5000 0 <= citations[i] <= 1000
- 最初错误的思路:排序法,排序后的数组,若 nums[index] = num,则表示 >=num 的元素有 nums.size()-index 个,因此找最大的index满足 nums.size() - index >= nums[index],即引用次数大于等于 nums[index] 的论文要大于等于 nums.size() -index 篇,此时H指数为 nums[index]
- 排序法,根据 H指数的定义,H指数的范围是 0~n,所以只需从n到0遍历,检查排序后的第 n-h 大的元素是否大于等于 h。时间复杂度 O(n log n),空间复杂度 O(log n)。
- 计数排序,根据定义,我们可以发现 H 指数不可能大于总的论文发表数,所以对于引用次数超过论文发表数的情况,我们可以将其按照总的论文发表数来计算即可。这样我们可以限制参与排序的数的大小为 [0,n](其中 n 为总的论文发表数),使得计数排序的时间复杂度降低到 O(n)。 最后我们可以从后向前遍历数组 counter,对于每个 0≤i≤n,在数组 counter 中得到大于或等于当前引用次数 i 的总论文数。当我们找到一个 H 指数时跳出循环,并返回结果。
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
示例 1:
输入: nums = [1,3,5,6], target = 5 输出: 2 示例 2:
输入: nums = [1,3,5,6], target = 2 输出: 1 示例 3:
输入: nums = [1,3,5,6], target = 7 输出: 4
提示:
1 <= nums.length <= 104 -104 <= nums[i] <= 104 nums 为 无重复元素 的 升序 排列数组 -104 <= target <= 104
- 二分法,需要注意的是当目标值不在数组中该如何确定索引值
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:

输入:head = [1,2,3,4] 输出:[2,1,4,3] 示例 2:
输入:head = [] 输出:[] 示例 3:
输入:head = [1] 输出:[1]
提示:
链表中节点的数目在范围 [0, 100] 内 0 <= Node.val <= 100
- 奇数个节点时,最后一个节点不变;对于如何交换两个节点(不改变节点的值),就需要单链表的一些操作,要使用指针指向一些节点
实现RandomizedSet 类:
RandomizedSet() 初始化 RandomizedSet 对象 bool insert(int val) 当元素 val 不存在时,向集合中插入该项,并返回 true ;否则,返回 false 。 bool remove(int val) 当元素 val 存在时,从集合中移除该项,并返回 true ;否则,返回 false 。 int getRandom() 随机返回现有集合中的一项(测试用例保证调用此方法时集合中至少存在一个元素)。每个元素应该有 相同的概率 被返回。 你必须实现类的所有函数,并满足每个函数的 平均 时间复杂度为 O(1) 。
示例:
输入 ["RandomizedSet", "insert", "remove", "insert", "getRandom", "remove", "insert", "getRandom"] [ [], [1], [2], [2], [], [1], [2], [] ] 输出 [null, true, false, true, 2, true, false, 2]
解释 RandomizedSet randomizedSet = new RandomizedSet(); randomizedSet.insert(1); // 向集合中插入 1 。返回 true 表示 1 被成功地插入。 randomizedSet.remove(2); // 返回 false ,表示集合中不存在 2 。 randomizedSet.insert(2); // 向集合中插入 2 。返回 true 。集合现在包含 [1,2] 。 randomizedSet.getRandom(); // getRandom 应随机返回 1 或 2 。 randomizedSet.remove(1); // 从集合中移除 1 ,返回 true 。集合现在包含 [2] 。 randomizedSet.insert(2); // 2 已在集合中,所以返回 false 。 randomizedSet.getRandom(); // 由于 2 是集合中唯一的数字,getRandom 总是返回 2 。
提示:
-2^31 <= val <= 2^31 - 1 最多调用 insert、remove 和 getRandom 函数 2 * 10^5 次 在调用 getRandom 方法时,数据结构中 至少存在一个 元素。
- 要求插入、删除和获取这3个函数的平均时间复杂度都是 O(1),首先思考用什么数据结构或容器存储元素,是自己实现还是使用C++标准库容器
- leetcode官方思路:
变长数组 + 哈希表 这道题要求实现一个类,满足插入、删除和获取随机元素操作的平均时间复杂度为 O(1)。
变长数组可以在 O(1) 的时间内完成获取随机元素操作,但是由于无法在 O(1) 的时间内判断元素是否存在,因此不能在 O(1) 的时间内完成插入和删除操作。哈希表可以在 O(1) 的时间内完成插入和删除操作,但是由于无法根据下标定位到特定元素,因此不能在 O(1) 的时间内完成获取随机元素操作。为了满足插入、删除和获取随机元素操作的时间复杂度都是 O(1),需要将变长数组和哈希表结合,变长数组中存储元素,哈希表中存储每个元素在变长数组中的下标。
插入操作时,首先判断 val 是否在哈希表中,如果已经存在则返回 false,如果不存在则插入 val,操作如下:
在变长数组的末尾添加 val;
在添加 val 之前的变长数组长度为 val 所在下标 index,将 val 和下标 index 存入哈希表;
返回 true。
删除操作时,首先判断 val 是否在哈希表中,如果不存在则返回 false,如果存在则删除 val,操作如下:
从哈希表中获得 val 的下标 index;
将变长数组的最后一个元素 last 移动到下标 index 处,在哈希表中将 last 的下标更新为 index;
在变长数组中删除最后一个元素,在哈希表中删除 val;
返回 true。
删除操作的重点在于将变长数组的最后一个元素移动到待删除元素的下标处,然后删除变长数组的最后一个元素。该操作的时间复杂度是 O(1),且可以保证在删除操作之后变长数组中的所有元素的下标都连续,方便插入操作和获取随机元素操作。
获取随机元素操作时,由于变长数组中的所有元素的下标都连续,因此随机选取一个下标,返回变长数组中该下标处的元素。
给你一个单链表的头节点 head ,请你判断该链表是否为
回文链表。如果是,返回 true ;否则,返回 false 。
示例 1:

提示:
链表中节点数目在范围[1, 105] 内 0 <= Node.val <= 9
进阶:你能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题?
- 一个思路就是遍历一遍,依次记录元素值,然后反转,看序列是否相同,时间复杂度为 O(n),空间复杂度为 O(n)
- 回想录思路:反转后半部分指针
分为如下几步:
- 用快慢指针,快指针有两步,慢指针走一步,快指针遇到终止位置时,慢指针就在链表中间位置
- 同时用pre记录慢指针指向节点的前一个节点,用来分割链表
- 将链表分为前后均等两部分,如果链表长度是奇数,那么后半部分多一个节点
- 将后半部分反转 ,得cur2,前半部分为cur1
- 按照cur1的长度,一次比较cur1和cur2的节点数值
- 树根始终为黑色
- 外部节点均为黑色
- 其余节点若为红色,则其孩子节点必为黑色
- 从任一外部节点到根节点的沿途,黑色节点的数目相等
设a,b,c均是0到9之间的数字,abc,bcc是两个三位数,且有abc+bcc=532。 求满足条件的所有a,b,c的值。
题目没有任何输入。
请输出所有满足题日条件的α,b,c的值。 a,b,c之间用空格隔开。 每个输出占一行。
- 直接枚举
- 根据题目描述,a!=0, b!=0,
设是一个4位数,它的9倍恰好是其反序数(如1234的反序数是4321),求的值。
题目没有任何输入。
输出题目要求的4位数,如果结果有多组,那么每组结果之间以回车隔开。
- 枚举
- 根据题目描述,首位不为0,首位必为1(否则其9倍为5位数),最后一位不为0
输入一个高度h,输出一个高度为h、上底边长度为h的梯形
把一个个大小差一圈的筐叠上去,使得从上往下看时,边筐花色交错。这个 工作现在要让计算机来完成,得看你的了。
输入是一个个三元组,分别是:外筐尺寸n(n为满足0<n<80的奇整数), 中心花色字符,外筐花色字符,后二者都为ASCⅡ可见字符。
输出叠在一起的筐图案,中心花色与外筐花色字符从内层起交错相叠,多筐 相叠时,最外筐的角总是被打磨掉。叠筐与叠筐之间应有一行间隔。
输入年、月、日,计算该天是本年的第几天。
包括3个整数:年(1≤Y≤3000)、月(1≤M≤12)、日(1≤D≤31)
输入可能有多组测试数据,对于每组测试数据, 输出一个整数,代表Input中的年、月、日对应本年的第几天。
1990 9 20 2000 5 1
263 122
输入10个整数,彼此以空格分隔。重新排序后输出(也按空格分隔),要求: 1)首先输出其中的奇数,并且按照从大到小的顺序排列:2)然后输出其中的偶数,并且按照从小到大的顺序排列。
n个小孩围坐成一圈,并按顺时针编号为1,2,…,n,从编号为p的小孩顺时针依次报数,由1报 到m,报到m时,这名小孩从圈中出去;然后下一名小孩再从1报数,报到m时再出去。以此 类推,直到所有小孩都从圈中出去。请按出去的先后顺序输出小孩的编号。
第一个是n,第二个是p,第三个是m(0<m,n<300)。 最后一行是:000。
按出圈的顺序输出编号,编号之间以逗号间隔。
8 3 4 0 0 0
6,2,7,4,3,5,1,8
- 使用队列来实现这种循环的遍历
- 首先,从p开始将n个数放入队列;接着,使用一个变量表示当前报数的值,队列每次出列时判断当前报数值是否为m,若为m则输出当前值并将报数值重新置1,否则继续将当前元素入栈
在某个字符串(长度不超过100)中有左括号、右括号和大小写字母:规定(与常见的算数式子一样)任何一个左括号都从内到外与在它右边且距离最近的右括号匹配。写一个程序,找到无法匹配的左括号和右括号,输出原来的字符串,并在下一行标出不能匹配的括号。不能匹配的左括号用"$"标注,不能匹配的右括号用"?"标注。
输入包括多组数据,每组数据一行,包含一个字符串,只包含左右括号和大小写字母,字符串长度不超过100。
对每组输出数据,输出两行,第一行包含原始输入字符,第二行由"$""?"和空格组成,"$"和"?"表示与之对应的左括号和右括号不能匹配。
- 这种括号匹配问题显然使用栈来解决
- 左括号不能匹配对应最终栈非空,右括号不能匹配对应栈为空的情况
汉诺塔问题(Tower of Hanoi)是一个经典的递归问题。它的规则如下:
- 有三根柱子,称为 A、B、C 柱子。
- 在柱子 A 上,有若干个大小不等的圆盘,较大的圆盘在下,较小的圆盘在上。
- 目标是把所有圆盘从柱子 A 移动到柱子 C 上,柱子 B 可以作为辅助柱子。
- 移动时需要遵循以下规则:
- 每次只能移动一个圆盘。
- 大圆盘不能放在小圆盘上。
设有 n 个圆盘,步骤如下:
- 递归地将前
n-1个圆盘从柱子 A 移动到柱子 B,柱子 C 作为辅助。 - 将第
n个圆盘从柱子 A 移动到柱子 C。 - 递归地将前
n-1个圆盘从柱子 B 移动到柱子 C,柱子 A 作为辅助。
- 当
n=1时,只需要直接把这个盘子从 A 移动到 C。 - 当
n>1时:- 先把
n-1个盘子从 A 移动到 B。 - 把第
n个盘子从 A 移动到 C。 - 再把
n-1个盘子从 B 移动到 C。
- 先把
#include <iostream>
using namespace std;
// 汉诺塔递归函数
void hanoi(int n, char source, char auxiliary, char destination) {
// 基本情况:如果只有一个圆盘,直接从源柱移动到目标柱
if (n == 1) {
cout << "Move disk 1 from " << source << " to " << destination << endl;
return;
}
// 递归步骤:
// 1. 先将 n-1 个圆盘从源柱移动到辅助柱
hanoi(n - 1, source, destination, auxiliary);
// 2. 将第 n 个圆盘从源柱移动到目标柱
cout << "Move disk " << n << " from " << source << " to " << destination << endl;
// 3. 最后将 n-1 个圆盘从辅助柱移动到目标柱
hanoi(n - 1, auxiliary, source, destination);
}
int main() {
int n;
cout << "Enter the number of disks: ";
cin >> n;
// 开始汉诺塔的递归移动
hanoi(n, 'A', 'B', 'C'); // A 是源柱,B 是辅助柱,C 是目标柱
return 0;
}- 函数定义:
hanoi(int n, char source, char auxiliary, char destination):n:要移动的圆盘数。source:源柱。auxiliary:辅助柱。destination:目标柱。
- 递归过程:
- 如果只有一个圆盘 (
n == 1),直接移动到目标柱。 - 否则,先递归地把
n-1个圆盘从源柱移动到辅助柱。 - 再把最大的第
n个盘子从源柱移动到目标柱。 - 最后递归地把
n-1个盘子从辅助柱移动到目标柱。
- 如果只有一个圆盘 (
假设用户输入 n=3,输出将会是:
Move disk 1 from A to C
Move disk 2 from A to B
Move disk 1 from C to B
Move disk 3 from A to C
Move disk 1 from B to A
Move disk 2 from B to C
Move disk 1 from A to C
汉诺塔问题的时间复杂度为 O(2^n),因为每次递归会将 n-1 个盘子从一个柱子移到另一个柱子,并且需要移动 2^(n-1) 次。