I think i have fixed the ctcloss nan problem!
Now!
Please pull the latest code from master.
Please update the pytorch to >= v1.2.0
Enjoy it!
PS: Once there is ctclossnan, please
- Change the
batchSizeto smaller (eg: 8, 16, 32)- Change the
lrto smaller (eg: 0.00001, 0.0001)- Contact me by emailing to [email protected]
- CentOS7
- Python3.6.5
- torch==1.2.0
- torchvision==0.4.0
- Tesla P40 - Nvidia
-
Download a pretrained model from Baidu Cloud (extraction code:
si32) -
People who cannot access Baidu can download a copy from Google Drive
-
Run demo
python demo.py -m path/to/model -i data/demo.jpg
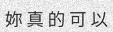
Expected output
-妳----真---的的---可---------以 => 妳真的可以
-
Variable length
It support variable length.
-
Chinese support
I change it to
binary modewhen reading the key and value, so you can use it to do Chinese OCR. -
Change CTCLoss from warp-ctc to torch.nn.CTCLoss
As we know, warp-ctc need to compile and it seems that it only support PyTorch 0.4. But PyTorch support CTCLoss itself, so i change the loss function to
torch.nn.CTCLoss. -
Solved PyTorch CTCLoss become
nanafter several epochJust don't know why, but when i train the net, the loss always become
nanafter several epoch.I add a param
dealwith_lossnantoparams.py. If set it toTrue, the net will autocheck and replace allnan/infin gradients to zero. -
DataParallel
I add a param
multi_gputoparams.py. If you want to use multi gpu to train your net, please set it toTrueand set the paramngputo a proper number.
-
Put your images in a folder and organize your images in the following format:
label_number.jpgFor example
- English
hi_0.jpg hello_1.jpg English_2.jpg English_3.jpg E n g l i s h_4.jpg...
- Chinese
一身转战_0.jpg 三千里_1.jpg 一剑曾当百万师_2.jpg 一剑曾当百万师_3.jpg 一 剑 曾 当 百 万 师_3.jpg ...
So you can see, the number is used to distinguish the same label.
-
Run the
create_dataset.pyintoolfolder bypython tool/create_dataset.py --out lmdb/data/output/path --folder path/to/folder
-
Use the same step to create train and val data.
-
The advantage of the folder mode is that it's convenient! But due to some illegal character can't be in the path
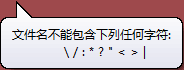
So the disadvantage of the folder mode is that it's labels are limited.
-
Your data file should like
absolute/path/to/image/一身转战_0.jpg 一身转战 absolute/path/to/image/三千里_1.jpg 三千里 absolute/path/to/image/一剑曾当百万师_2.jpg 一剑曾当百万师 absolute/path/to/image/3.jpg 一剑曾当百万师 absolute/path/to/image/一 剑 曾 当 百 万 师_4.jpg 一 剑 曾 当 百 万 师 absolute/path/to/image/xxx.jpg label of xxx.jpg . . .
DO REMEMBER:
- It must be the absolute path to image.
- The first line can't be empty.
- There are no blank line between two data.
-
Run the
create_dataset.pyintoolfolder bypython tool/create_dataset.py --out lmdb/data/output/path --file path/to/file
-
Use the same step to create train and val data.
Parameters and alphabets can't always be the same in different situation.
-
Change parameters
Your can see the
params.pyin detail. -
Change alphabets
Please put all the alphabets appeared in your labels to
alphabets.py, or the program will throw error during training process.
Run train.py by
python train.py --trainroot path/to/train/dataset --valroot path/to/val/dataset