This is the official code repository of Diff-TTSG: Denoising probabilistic integrated speech and gesture synthesis.
Demo Page: https://shivammehta25.github.io/Diff-TTSG/
Huggingface Space: https://huggingface.co/spaces/shivammehta25/Diff-TTSG
We present Diff-TTSG, the first diffusion model that jointly learns to synthesise speech and gestures together. Our method is probabilistic and non-autoregressive, and can be trained on small datasets from scratch. In addition, to showcase the efficacy of these systems and pave the way for their evaluation, we describe a set of careful uni- and multi-modal subjective tests for evaluating integrated speech and gesture synthesis systems.
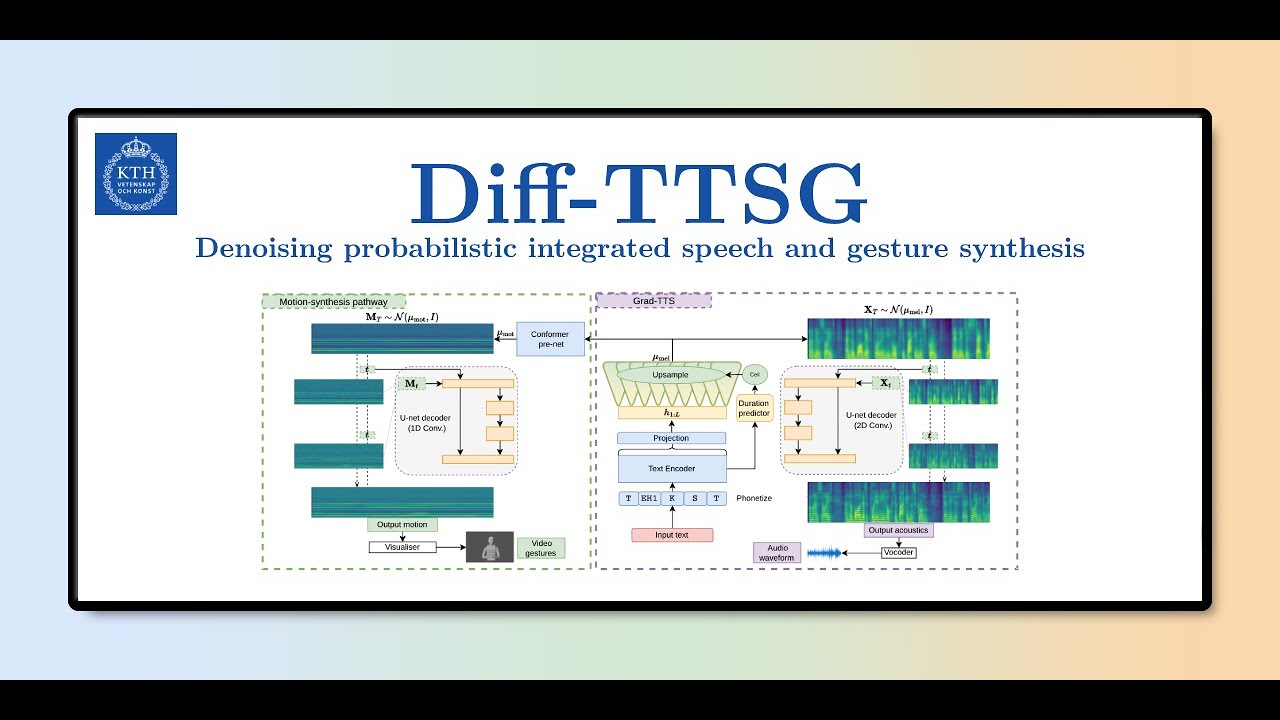
-
Clone this repository
git clone https://github.com/shivammehta25/Diff-TTSG.git cd Diff-TTSG -
Create a new environment (optional)
conda create -n diff-ttsg python=3.10 -y conda activate diff-ttsg
-
Setup diff ttsg (This will install all the dependencies and download the pretrained models)
- Is you are using Linux or Mac OS, run the following command
make install
- else install all dependencies and alignment build simply by
pip install -e . -
Run gradio UI
gradio app.py
or use synthesis.ipynb
Pretrained checkpoint (Should be autodownloaded by running either make install or gradio app.py)
If you use or build on our method or code for your research, please cite our paper:
@inproceedings{mehta2023diff,
author={Mehta, Shivam and Wang, Siyang and Alexanderson, Simon and Beskow, Jonas and Sz{\'e}kely, {\'E}va and Henter, Gustav Eje},
title={{D}iff-{TTSG}: {D}enoising probabilistic integrated speech and gesture synthesis},
year={2023},
booktitle={Proc. ISCA Speech Synthesis Workshop (SSW)},
pages={150--156},
doi={10.21437/SSW.2023-24}
}
The code in the repository is heavily inspired by the source code of