The future of fstar mode
Here's a list of features that would be nice to have in F* IDEs, what difficulties may arise, and what changes these features would require:
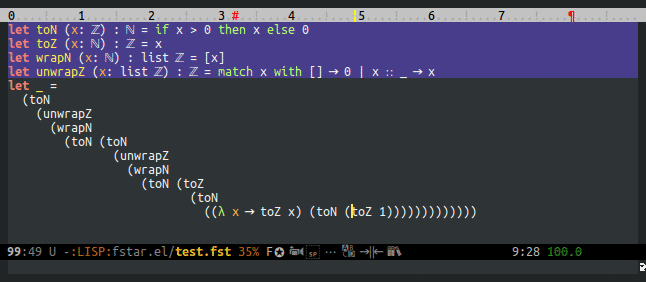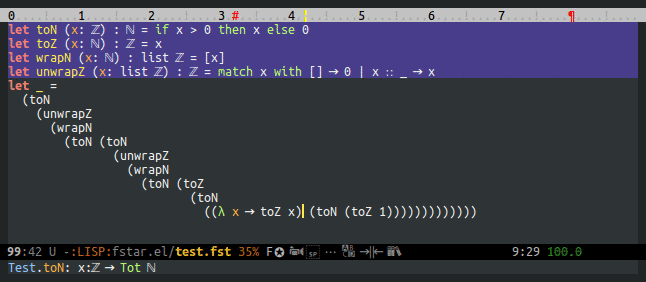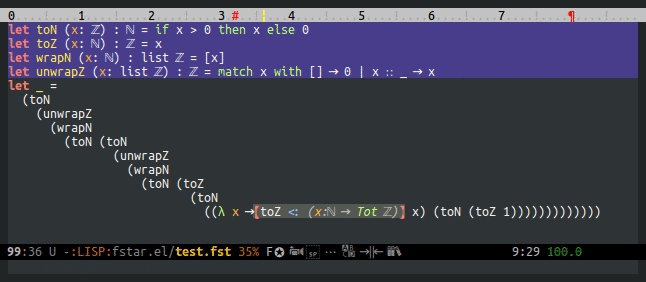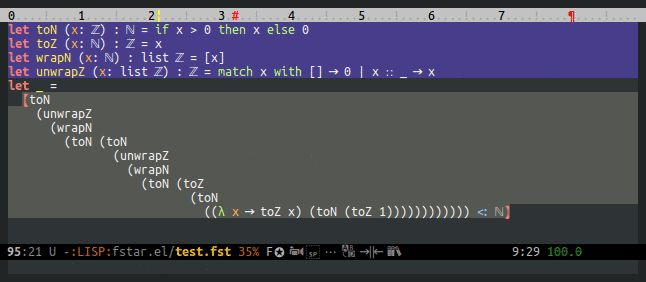
F* currently records (and fstar-mode displays) the type of all free and bound variables. This makes it possible to query F* about the type of the symbol that the point is on. This is too restrictive, though: it would be much nicer to be able to get the type at point, but also the types of all enclosing contexts.
Types are added by the typechecker in the tk field of terms, but types are dropped by normalization, substitution, and possibly other operations. Normalization isn't too bad, but substitution is a killer: after typechecking, the AST of let a = 1 in f a doesn't have a type for (f a).
Implementation cost of a fix: low — just change the substitution engine to preserve types and substitute in types as well.
Runtime cost of a fix: high if done naively, nil otherwise — substitution now would have to recurse on types, not just terms, and the extra fields may consume extra memory. We could turn this off for batch use, though, and thus only increase memory use when running in IDE mode. Better, we could make this a dynamically settable option, and we'd only consume the extra time and memory if the IDE explicitly requests it.
As an alternative, one could imagine adding a hook into tc_maybe_top_level_term that would get called once per subterm, with the type and its term.
(May not be an issue) We need to be able to fetch the top-level term that covers any given point, and extract the corresponding type information. This might mean re-typechecking the term, if we don't always ensure that types are preserved.
Ranges are added by the parser, but then copied onto new AST nodes created while desugaring, This is the right thing to do for error reporting, but for type-at-point it doesn't work. This is a problem in plenty of places, like function applications (implicit arguments get the same range as the function they attach to) and let bindings (the body gets wrapped in a Tm_abs). As a concrete example, the AST of let a = 1 in 1 + f a contains a Tm_abs node (fun a -> f a) with a range covering exactly 1 + f a and type nat -> nat., but of course, 1 + f a doesn't have type nat -> nat.
Implementation cost of a fix: high: Review most of the desugaring code and mark "hypothetical" ranges so that they can be skipped when cycling through enclosing types. This requires tagging all ranges with an extra boolean. This can also be implemented lazily, by fixing examples as they pop up — but finding where a term is created and where a range is used is hard.
Runtime cost of a fix: One extra boolean per range, and less sharing of ranges (since ranges that were previously shared will now be duplicated — one copy with hypothetical = false, and one with hypothetical = true.
Related to “types at point”. The idea here is that you could mark a chunk of code, press a key, and get the type of that region.
This is harder than getting the types of terms covering the current point, because you also need to typecheck e.g. partial applications. For example, one would like to be able to write let _ = map f [1;2], highlight map f, and typecheck it.
In general types are very useful while writing code — it would be nice to be able to typecheck partial programs. For example, one might write something like let a = 1 +, then press a key, and get int as the expected type. but if they wrote let (a: nat) = 1 +, they'd get nat.
This is hard, because currently these terms don't even parse — but maybe we can do smart things by taking the parser's partial state and using it to extend the current input into a complete term? Bonus points of course it the process handles things like let a = 1 + <point here> in .