Webscraping
You can download webpages with the Generic module by adding an URL as seed node and setting the base path to <Object ID>. If you set the response format to "text", after downloading HTML files you will find the HTML source code of pages in the text property. Use CSS selectors, XPath and regular expressions to scrape data using the pipe & modifier syntax inside of keys. Values can be passed to further functions using the pipe | operator followed by the modifiers css: or xpath: or re:. The preset for scraping tables from Wikipedia is a good starting point. The Extract data-function in the Data View provides a preview for developing your keys.
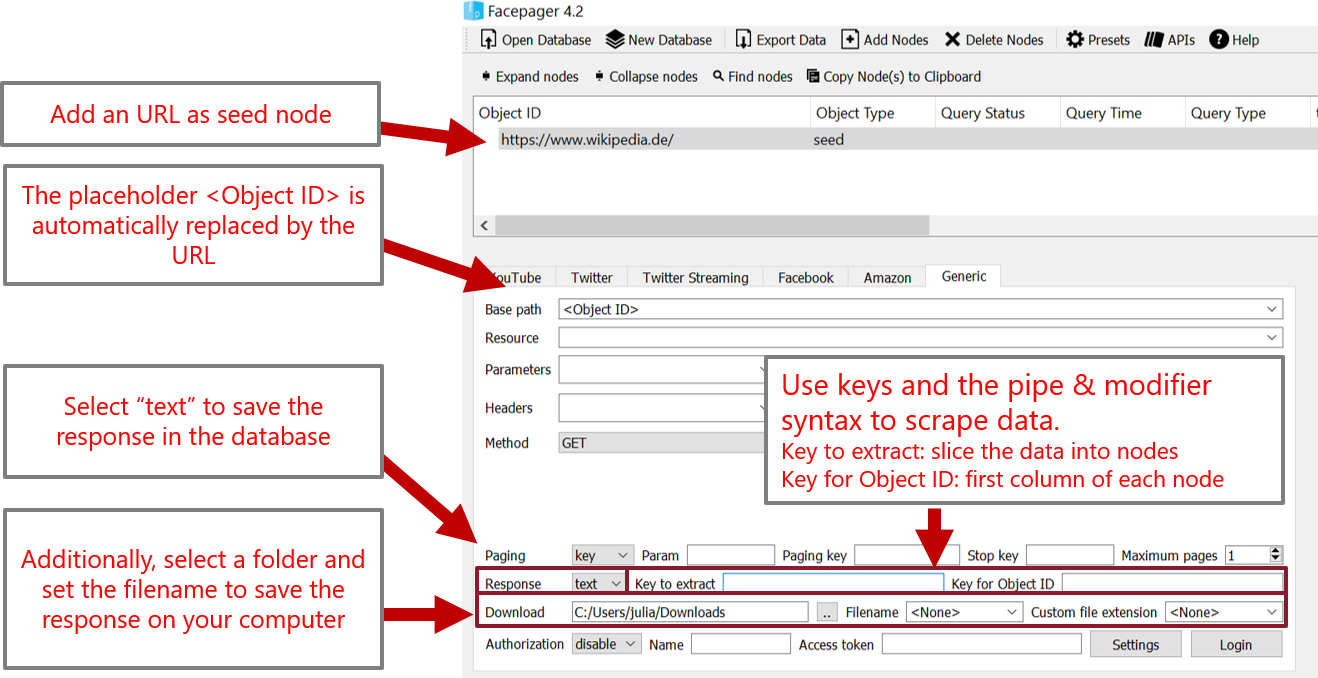
For example, text|css:div.article will first select the text key and second pass the value to an XML parser in order to select all elements matching the CSS selector div.article (=all div elements containing "article" in the class attribute).
The same may be achieved using XPath: text|xpath://div[@class='article'] will first select the text key and second pass the value to an XML parser in order to select all elements matching the given XPath expression (=all div elements with class attribute "article").
To search for text, use regular expression. For example, text|re:[0-9]+ will extract all numbers.
You can even chain functions. For example, text|css:div.article|xpath://text() will first select the text key, then select div elements with class "article", and finally extract all text in the elements.
If the extracted HTML or XML elements contain JSON, you can convert it from text to JSON with the modifier json:. Add a key if you are only interested in specific values of the object.
By default, the result is saved in the text key. In order to rename the key, prefix your expression with newkey=. For example, link=text|xpath://@href will save all links to the link-key.
The pipe & modifier syntax can be used inside of keys at different places:
- You can extract elements and values when downloading data using the fields
Key to extractandKey for Object IDin the Generic Module. New child nodes are created from the extracted data. - In order to show HTML data in the data view and export it as a CSV file you can scrape data in the column setup.
- You can use the same keys in placeholders.
- The function
Extract dataright above the Detail View lets you extract data after downloading. This function follows the same logic like in the downloading step. New child nodes are created from the extracted data.
Modifiers parse and convert the data. Mosts modifiers consist of a name followed by a colon and options after the colon. Some modifiers don't have options and the colon is omitted, see below. Modifiers can be chained by using a pipe |. You can escape special characters such as the pipe with a backslash.
| modifier | options | examples |
|---|---|---|
| css | Add css selectors to extract elements from HTML or XML |
css:a css:div.article
|
| xpath | Add xpath selectors to extract elements from HTML or XML. |
xpath://a/@href xpath://a/text() css:div.article|xpath:string()
|
| re | Use regular expressions to find and extract text. The first matching group (first parentheses) is returned. Special characters are escaped by a backslash. |
re:[0-9]+ re:hashtag/(\\w+)
|
| js | Parse Javascript and get the content of variables or objects by their name. This is helpful if your HTML contains script tags. |
js:captions xpath://script/text()|js:display_comments
|
| json | Parse JSON and get components by key. This is helpful if your HTML contains JSON inside of tags or JavaScript |
json:messagetext xpath://script/text()|js:commentslist|json:comment
|
| not | Return false if any of the values contains the given value, otherwise true. This is helpful for stopping pagination if specific data is not present |
not:hasNextPage summary|not:hasNextPage
|
| is | Return true if any of the values contains the given value, otherwise false. This is helpful for stopping pagination if specific data is present |
is:lastPage summary|is:lastPage
|
| utc | Convert a Unix timestamp to a formatted UTC date. Note: before Facepager 4.5 this modifier was called timestamp. | utc |
| timestamp | Convert a formatted ISO date (e.g. 2021-10-01 13:10:00) to a Unix timestamp. Note: before Facepager 4.5 the utc modifier was called timestamp. | timestamp |
| timestamp | Convert a formatted date to a Unix timestamp. Provide the format after the colon, you will find the syntax in the reference of strptime, see https://docs.python.org/3/library/datetime.html. Note: before Facepager 4.5 the utc modifier was called timestamp. | timestamp:%Y-%m-%d %H:%M:%S |
| shortdate | Convert shortdates (e.g. on Twitter) to a formatted UTC date. The parsed pattern is %a %b %d %H:%M:%S %z %Y
|
shortdate |
| encode | Change encoding of the text. |
encode:utf-8 css:div.article|encode:utf-8
|
| base64 | Base64 encode the value. This is helpful for uploading base64 encoded data | base64 |
| length | Get the number of values. |
length css:div.article|length
|
| file | The previous value is interpreted as filename and loaded from your upload folder. You can add filenames with the Add Nodes -> Add files button. |
Object ID|file filename|file
|